




















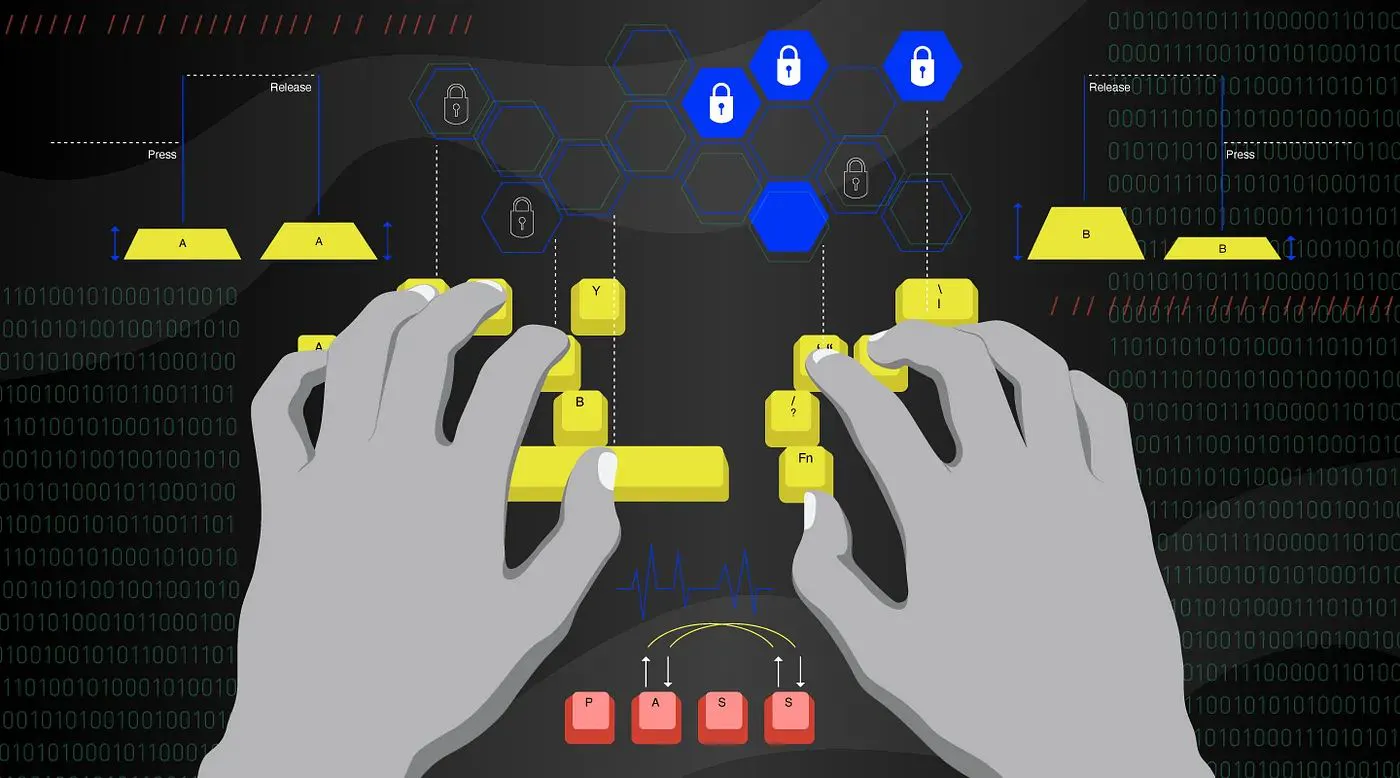


Mô hình ML để nhận dạng người dùng bằng cách sử dụng động lực gõ phím
Động lực gõ phím được sử dụng trong các mô hình học máy của bài viết này để nhận dạng người dùng là sinh trắc học hành vi. Động lực gõ phím sử dụng cách thức đặc biệt mà mỗi người gõ để xác nhận danh tính của họ. Điều này được thực hiện bằng cách phân tích 2 sự kiện nhấn phím trên Key-Press và Key-Release - tạo nên một lần nhấn phím trên bàn phím máy tính để trích xuất kiểu gõ.
Bài viết này sẽ xem xét cách áp dụng các mẫu này để tạo ra 3 mô hình học máy chính xác để nhận dạng người dùng.


Mục tiêu của bài viết này sẽ được chia thành hai phần, xây dựng và đào tạo các mô hình Machine Learning (1. SVM 2. Random Forest 3. XGBoost ) và triển khai mô hình trong API một điểm trực tiếp thực tế có khả năng dự đoán người dùng dựa trên 5 đầu vào tham số: mô hình ML và 4 lần nhấn phím.
1. Mô hình tòa nhà
Vấn đề
Mục tiêu của phần này là xây dựng các mô hình ML để nhận dạng người dùng dựa trên dữ liệu gõ phím của họ. Động lực gõ phím là sinh trắc học hành vi sử dụng cách thức duy nhất mà một người nhập để xác minh danh tính của một cá nhân.
Kiểu gõ chủ yếu được trích xuất từ bàn phím máy tính. các mẫu được sử dụng trong động lực nhấn phím chủ yếu bắt nguồn từ hai sự kiện tạo nên một lần nhấn phím: Nhấn phím và Nhả phím.
Sự kiện Nhấn phím diễn ra khi nhấn phím ban đầu và nhấn phím xảy ra ở lần nhấn phím đó tiếp theo.
Ở bước này, tập dữ liệu về thông tin gõ phím của người dùng được cung cấp với các thông tin sau:
-
keystroke.csv: trong tập dữ liệu này, dữ liệu gõ phím từ 110 người dùng được thu thập. - Tất cả người dùng được yêu cầu nhập một chuỗi không đổi có độ dài 13 lần 8 lần và dữ liệu gõ phím (thời gian nhấn phím và thời gian nhả phím cho mỗi phím) sẽ được thu thập.
- Tập dữ liệu chứa 880 hàng và 27 cột.
- Cột đầu tiên biểu thị UserID và phần còn lại hiển thị thời gian nhấn và nhả cho ký tự đầu tiên đến ký tự thứ 13.
Bạn nên làm như sau:
Thông thường, dữ liệu thô không đủ thông tin và cần trích xuất các đặc điểm thông tin từ dữ liệu thô để xây dựng một mô hình tốt .
Về vấn đề này, có bốn đặc điểm:
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
được giới thiệu và định nghĩa của từng loại đã được mô tả ở trên.
2. Đối với mỗi hàng trong keystroke.csv, bạn nên tạo các tính năng này cho mỗi hai phím liên tiếp.
3. Sau khi hoàn thành bước trước, bạn nên tính giá trị trung bình và độ lệch chuẩn cho từng đặc điểm trên mỗi hàng. Do đó, bạn phải có 8 đặc điểm (4 giá trị trung bình và 4 độ lệch chuẩn) trên mỗi hàng. → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
Tất cả mã bạn có thể tìm thấy trên GitHub của tôi trong kho lưu trữ KeystroDynamics:
Đào tạo ML
Bây giờ chúng ta đã phân tích cú pháp dữ liệu, chúng ta có thể bắt đầu xây dựng các mô hình bằng cách đào tạo các ML.
Máy Vector hỗ trợ
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
Bài đọc bổ sung:
Rừng ngẫu nhiên
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
Bài đọc bổ sung:
Tăng cường độ dốc cực cao
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
Bài đọc bổ sung:
Cũng được xuất bản ở đây.
Nếu bạn thích bài viết và muốn ủng hộ tôi, hãy đảm bảo:
🔔 Theo tôi Bogdan Tudorache
🔔 Kết nối với tôi: LinkedIn | Reddit








