




















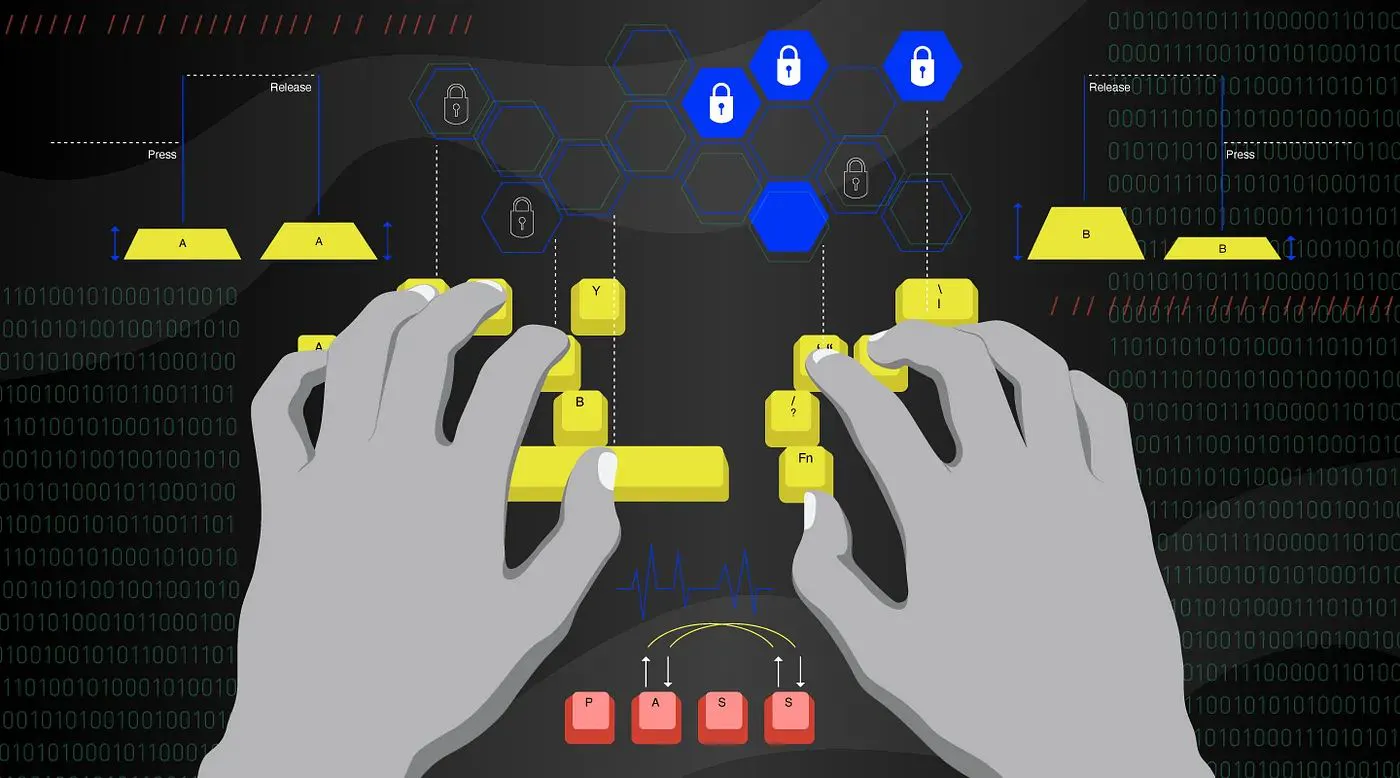


Modelos de ML para reconhecimento de usuário usando Keystroke Dynamics
A dinâmica de pressionamento de tecla usada nos modelos de aprendizado de máquina deste artigo para reconhecimento do usuário é a biometria comportamental. A dinâmica de pressionamento de tecla usa a forma distinta que cada pessoa digita para confirmar sua identidade. Isso é feito analisando os 2 eventos de pressionamento de tecla e liberação de tecla - que constituem um pressionamento de tecla em teclados de computador para extrair padrões de digitação.
Este artigo examinará como esses padrões podem ser aplicados para criar três modelos precisos de aprendizado de máquina para reconhecimento do usuário.


O objetivo deste artigo será dividido em duas partes, construir e treinar modelos de aprendizado de máquina (1. SVM 2. Random Forest 3. XGBoost ) e implantar o modelo em uma API real de ponto único capaz de prever o usuário com base em 5 entradas parâmetros: o modelo ML e 4 vezes de pressionamento de tecla.
1. Construindo Modelos
O problema
O objetivo desta parte é construir modelos de ML para reconhecimento do usuário com base nos dados de pressionamento de tecla . A dinâmica de pressionamento de tecla é uma biometria comportamental que utiliza a maneira única que uma pessoa digita para verificar a identidade de um indivíduo.
Os padrões de digitação são predominantemente extraídos de teclados de computador. os padrões usados na dinâmica de pressionamento de tecla são derivados principalmente dos dois eventos que compõem um pressionamento de tecla: o pressionamento de tecla e a liberação de tecla.
O evento Key-Press ocorre na pressão inicial de uma tecla e o Key-Release ocorre na liberação subsequente dessa tecla.
Nesta etapa, um conjunto de dados de informações de pressionamento de tecla dos usuários é fornecido com as seguintes informações:
-
keystroke.csv: neste conjunto de dados, são coletados os dados de pressionamento de tecla de 110 usuários. - Todos os usuários são solicitados a digitar uma string constante de 13 comprimentos 8 vezes e os dados de pressionamento de tecla (tempo de pressionamento de tecla e tempo de liberação de tecla para cada tecla) são coletados.
- O conjunto de dados contém 880 linhas e 27 colunas.
- A primeira coluna indica UserID e o restante mostra o tempo de pressionamento e liberação do primeiro ao 13º caractere.
Você deve fazer o seguinte:
Normalmente, os dados brutos não são suficientemente informativos e é necessário extrair recursos informativos dos dados brutos para construir um bom modelo .
A este respeito, quatro características:
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
são apresentados e as definições de cada um deles são descritas acima.
2. Para cada linha em keystroke.csv, você deve gerar esses recursos para cada duas chaves consecutivas.
3. Após concluir a etapa anterior, você deve calcular a média e o desvio padrão de cada recurso por linha. Como resultado, você deve ter 8 características (4 médias e 4 desvios padrão) por linha. → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
Todo o código você encontra no meu GitHub no repositório KeystrokeDynamics:
Treine os MLs
Agora que analisamos os dados, podemos começar a construir os modelos treinando os MLs.
Máquina de vetores de suporte
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
Leitura adicional:
Floresta Aleatória
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
Leitura adicional:
Aumento extremo de gradiente
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
Leitura adicional:
Também publicado aqui.
Se você gostou do artigo e gostaria de me apoiar, certifique-se de:
🔔 Siga-me Bogdan Tudorache
🔔 Conecte-se comigo: LinkedIn | Reddit








