






















키 입력 역학을 사용한 사용자 인식을 위한 ML 모델
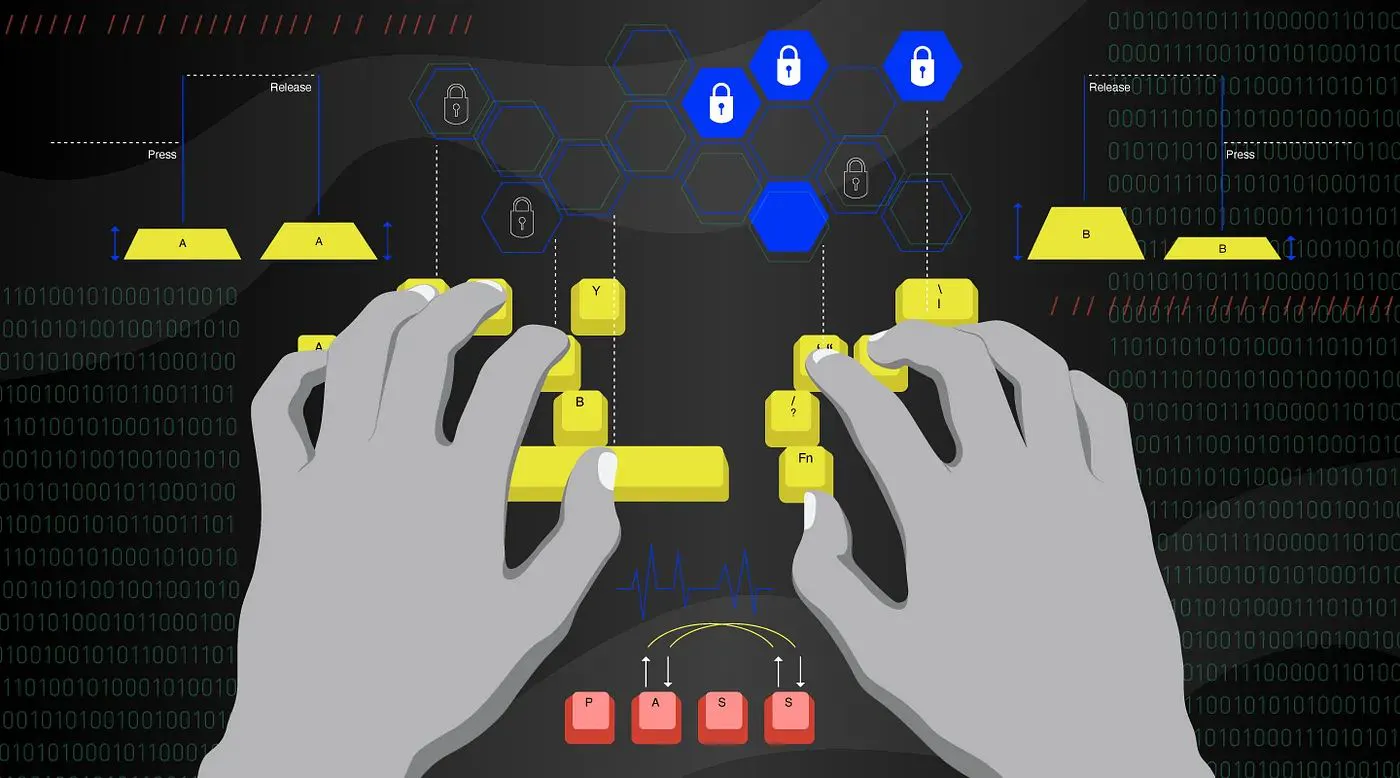
이 기사의 사용자 인식을 위한 기계 학습 모델에 사용되는 키 입력 역학은 행동 생체 인식입니다. 키 입력 역학은 각 사람이 자신의 신원을 확인하기 위해 입력하는 독특한 방식을 사용합니다. 이는 타이핑 패턴을 추출하기 위해 컴퓨터 키보드의 키 입력을 구성하는 키 누르기 및 키 놓기의 2가지 키 입력 이벤트를 분석하여 수행됩니다.
이 기사에서는 이러한 패턴을 적용하여 사용자 인식을 위한 3가지 정밀한 기계 학습 모델을 만드는 방법을 살펴보겠습니다.


이 기사의 목표는 기계 학습 모델(1. SVM 2. Random Forest 3. XGBoost )을 구축 및 훈련 하고 5가지 입력을 기반으로 사용자를 예측할 수 있는 실제 라이브 단일 포인트 API에 모델을 배포하는 두 부분으로 나뉩니다. 매개변수: ML 모델 및 4가지 키 입력 시간.
1. 모델 구축
문제
이 부분의 목표는 키 입력 데이터를 기반으로 사용자 인식을 위한 ML 모델을 구축하는 것입니다. 키 입력 역학은 개인의 신원을 확인하기 위해 개인이 입력하는 고유한 방식을 활용하는 행동 생체 인식입니다.
타이핑 패턴은 주로 컴퓨터 키보드에서 추출됩니다. 키 입력 역학에 사용되는 패턴은 주로 키 입력을 구성하는 두 가지 이벤트인 키 누르기 및 키 놓기에서 파생됩니다.
Key-Press 이벤트는 키를 처음 누를 때 발생하고 Key-Release는 해당 키를 연속적으로 놓을 때 발생합니다.
이 단계에서는 사용자의 키 입력 정보 데이터 세트가 다음 정보와 함께 제공됩니다.
-
keystroke.csv: 이 데이터 세트에는 110명의 사용자로부터 키 입력 데이터가 수집됩니다. - 모든 사용자는 13개의 상수 문자열을 8번 입력하라는 요청을 받고 키 입력 데이터(각 키에 대한 키 누름 시간 및 키를 놓는 시간)가 수집됩니다.
- 데이터 세트에는 880개의 행과 27개의 열이 포함되어 있습니다.
- 첫 번째 열은 UserID를 나타내고 나머지는 첫 번째부터 13번째 문자의 눌림 및 해제 시간을 나타냅니다.
다음을 수행해야 합니다.
일반적으로 원시 데이터는 정보를 충분히 제공하지 못하며, 좋은 모델을 구축하려면 원시 데이터에서 유용한 특징을 추출 해야 합니다.
이와 관련하여 다음과 같은 네 가지 기능이 있습니다.
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
가 소개되고 각각의 정의는 위에 설명되어 있습니다.
2. keystroke.csv, 의 각 행에 대해 두 개의 연속 키 각각에 대해 이러한 기능을 생성 해야 합니다.
3. 이전 단계를 완료한 후 행당 각 특성에 대한 평균 및 표준 편차를 계산 해야 합니다. 결과적으로 행당 8개의 특성(평균 4개, 표준 편차 4개)이 있어야 합니다. → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
KeystrokDynamics 저장소의 GitHub에서 찾을 수 있는 모든 코드는 다음과 같습니다.
ML 학습
이제 데이터를 구문 분석했으므로 ML을 훈련하여 모델 구축을 시작할 수 있습니다.
서포트 벡터 머신
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
추가 자료:
랜덤 포레스트
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
추가 자료:
극단적인 그래디언트 부스팅
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
추가 자료:
기사가 마음에 들고 저를 지지하고 싶다면 다음을 확인하세요.
🔔 나를 따라오세요 Bogdan Tudorache








