




















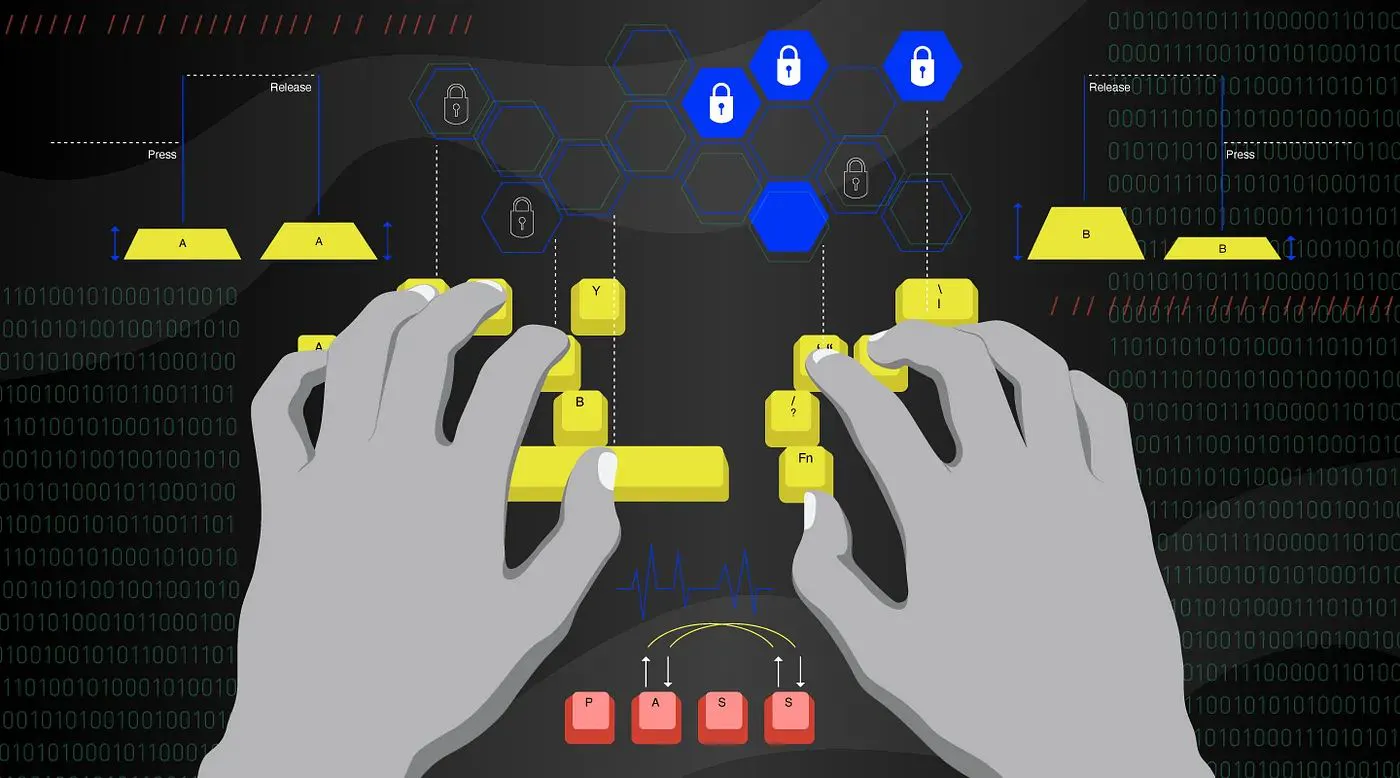


Modelos de aprendizaje automático para el reconocimiento de usuarios mediante Keystroke Dynamics
La dinámica de pulsaciones de teclas que se utiliza en los modelos de aprendizaje automático de este artículo para el reconocimiento de usuarios es biométrica del comportamiento. La dinámica de pulsaciones de teclas utiliza la forma distintiva en que cada persona escribe para confirmar su identidad. Esto se logra analizando los dos eventos de pulsación de tecla al presionar y soltar la tecla, que componen una pulsación de tecla en los teclados de computadora para extraer patrones de escritura.
Este artículo examinará cómo se pueden aplicar estos patrones para crear tres modelos precisos de aprendizaje automático para el reconocimiento de usuarios.


El objetivo de este artículo se dividirá en dos partes: construir y entrenar modelos de aprendizaje automático (1. SVM 2. Random Forest 3. XGBoost ) e implementar el modelo en una API real de un solo punto capaz de predecir al usuario en función de 5 entradas. parámetros: el modelo ML y 4 tiempos de pulsación de teclas.
1. Construcción de modelos
El problema
El objetivo de esta parte es crear modelos de ML para el reconocimiento de usuarios en función de sus datos de pulsaciones de teclas . La dinámica de pulsaciones de teclas es una biometría conductual que utiliza la forma única en que una persona escribe para verificar la identidad de un individuo.
Los patrones de escritura se extraen predominantemente de los teclados de computadora. Los patrones utilizados en la dinámica de pulsaciones de teclas se derivan principalmente de los dos eventos que componen una pulsación de tecla: la pulsación de tecla y la liberación de tecla.
El evento Key-Press tiene lugar al presionar inicialmente una tecla y el Key-Release ocurre al soltar posteriormente esa tecla.
En este paso, se proporciona un conjunto de datos de información de pulsaciones de teclas de los usuarios con la siguiente información:
-
keystroke.csv: en este conjunto de datos, se recopilan los datos de pulsaciones de teclas de 110 usuarios. - Se pide a todos los usuarios que escriban una cadena constante de 13 longitudes 8 veces y se recopilan los datos de pulsación de tecla (tiempo de pulsación de tecla y tiempo de liberación de tecla para cada tecla).
- El conjunto de datos contiene 880 filas y 27 columnas.
- La primera columna indica el ID de usuario y el resto muestra el tiempo de presionar y soltar del primero al decimotercer carácter.
Debes hacer lo siguiente:
Por lo general, los datos sin procesar no son lo suficientemente informativos y es necesario extraer características informativas de los datos sin procesar para construir un buen modelo .
En este sentido, cuatro características:
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
se introducen y las definiciones de cada uno de ellos se describen arriba.
2. Para cada fila en keystroke.csv, debes generar estas funciones para cada dos teclas consecutivas.
3. Después de completar el paso anterior, debes calcular la media y la desviación estándar para cada característica por fila. Como resultado, deberías tener 8 características (4 medias y 4 desviaciones estándar) por fila. → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
Todo el código lo podéis encontrar en mi GitHub en el repositorio de KeystrokeDynamics:
Entrenar a los ML
Ahora que hemos analizado los datos, podemos comenzar a construir los modelos entrenando los ML.
Máquinas de vectores soporte
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
Lectura adicional:
Bosque aleatorio
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
Lectura adicional:
Aumento de gradiente extremo
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
Lectura adicional:
También publicado aquí.
Si te gusta el artículo y quieres apoyarme, asegúrate de:
🔔 Sígueme Bogdan Tudorache
🔔 Conéctate conmigo: LinkedIn | Reddit








