




















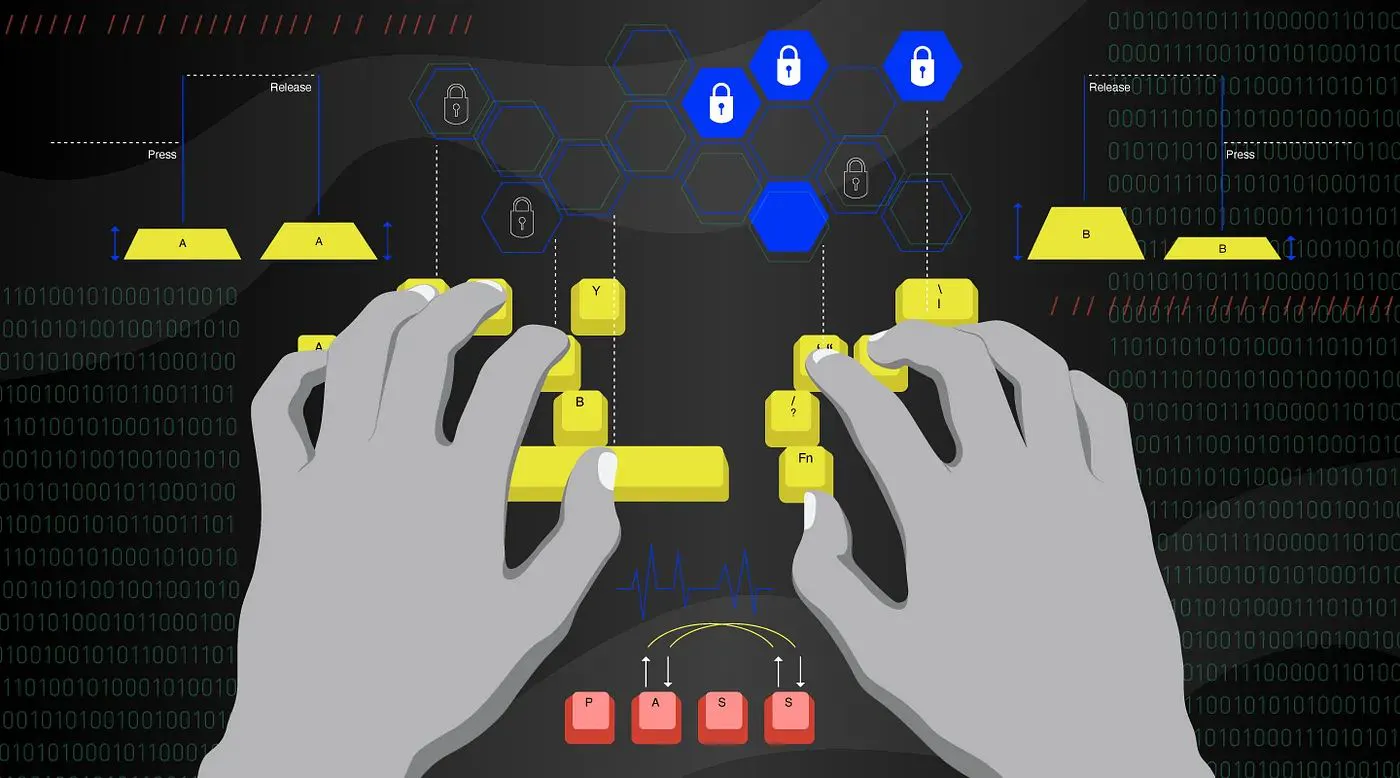


ML-Modelle zur Benutzererkennung mithilfe von Tastendruckdynamik
Die Tastendynamik, die in den maschinellen Lernmodellen dieses Artikels zur Benutzererkennung verwendet wird, ist Verhaltensbiometrie. Die Tastendynamik nutzt die unterschiedliche Art und Weise, wie jede Person tippt, um ihre Identität zu bestätigen. Dies wird durch die Analyse der beiden Tastenanschlagereignisse „ Tastendruck“ und „Tastenfreigabe“ erreicht, die auf Computertastaturen einen Tastenanschlag ausmachen, um Tippmuster zu extrahieren.
In diesem Artikel wird untersucht, wie diese Muster angewendet werden können, um drei präzise Modelle für maschinelles Lernen zur Benutzererkennung zu erstellen.


Das Ziel dieses Artikels besteht aus zwei Teilen: dem Erstellen und Trainieren von Modellen für maschinelles Lernen (1. SVM 2. Random Forest 3. XGBoost ) und dem Bereitstellen des Modells in einer echten Live-Einzelpunkt-API, die den Benutzer anhand von 5 Eingaben vorhersagen kann Parameter: das ML-Modell und 4 Tastenanschlagzeiten.
1. Modelle bauen
Das Problem
Das Ziel dieses Teils besteht darin, ML-Modelle für die Benutzererkennung basierend auf ihren Tastenanschlagsdaten zu erstellen. Bei der Tastendynamik handelt es sich um eine Verhaltensbiometrie, die die einzigartige Art und Weise, wie eine Person tippt, nutzt, um die Identität einer Person zu überprüfen.
Tippmuster werden überwiegend von Computertastaturen extrahiert. Die in der Tastenanschlagsdynamik verwendeten Muster werden hauptsächlich von den beiden Ereignissen abgeleitet, aus denen ein Tastenanschlag besteht: dem Tastendruck und dem Loslassen der Taste.
Das Key-Press-Ereignis findet beim ersten Drücken einer Taste statt und das Key-Release-Ereignis erfolgt beim anschließenden Loslassen dieser Taste.
In diesem Schritt wird ein Datensatz mit Tastenanschlaginformationen von Benutzern mit den folgenden Informationen bereitgestellt:
-
keystroke.csv: In diesem Datensatz werden die Tastenanschlagsdaten von 110 Benutzern gesammelt. - Alle Benutzer werden aufgefordert, 8 Mal eine konstante Zeichenfolge mit 13 Längen einzugeben, und die Tastenanschlagsdaten (Tastendruckzeit und Tastenfreigabezeit für jede Taste) werden erfasst.
- Der Datensatz enthält 880 Zeilen und 27 Spalten.
- Die erste Spalte gibt die Benutzer-ID an und der Rest zeigt die Druck- und Freigabezeit für das erste bis 13. Zeichen.
Sie sollten Folgendes tun:
Normalerweise sind die Rohdaten nicht informativ genug und es ist erforderlich , informative Merkmale aus den Rohdaten zu extrahieren, um ein gutes Modell zu erstellen .
In diesem Zusammenhang vier Merkmale:
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
werden vorgestellt und die jeweiligen Definitionen werden oben beschrieben.
2. Für jede Zeile in keystroke.csv, sollten Sie diese Funktionen für jeweils zwei aufeinanderfolgende Tasten generieren .
3. Nachdem Sie den vorherigen Schritt abgeschlossen haben, sollten Sie den Mittelwert und die Standardabweichung für jedes Feature pro Zeile berechnen . Als Ergebnis sollten Sie 8 Merkmale (4 Mittelwerte und 4 Standardabweichungen) pro Zeile haben. → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
Den gesamten Code finden Sie auf meinem GitHub im KeyStrokeDynamics-Repository:
Trainiere die MLs
Nachdem wir die Daten nun analysiert haben, können wir mit dem Aufbau der Modelle beginnen, indem wir die MLs trainieren.
Unterstützt Vektormaschine
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
Zusätzliche Lektüre:
Zufälliger Wald
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
Zusätzliche Lektüre:
Extreme Steigungsverstärkung
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
Zusätzliche Lektüre:
Auch hier veröffentlicht.
Wenn Ihnen der Artikel gefällt und Sie mich unterstützen möchten, achten Sie darauf:
🔔 Folge mir Bogdan Tudorache
🔔 Verbinden Sie sich mit mir: LinkedIn | Reddit








