




















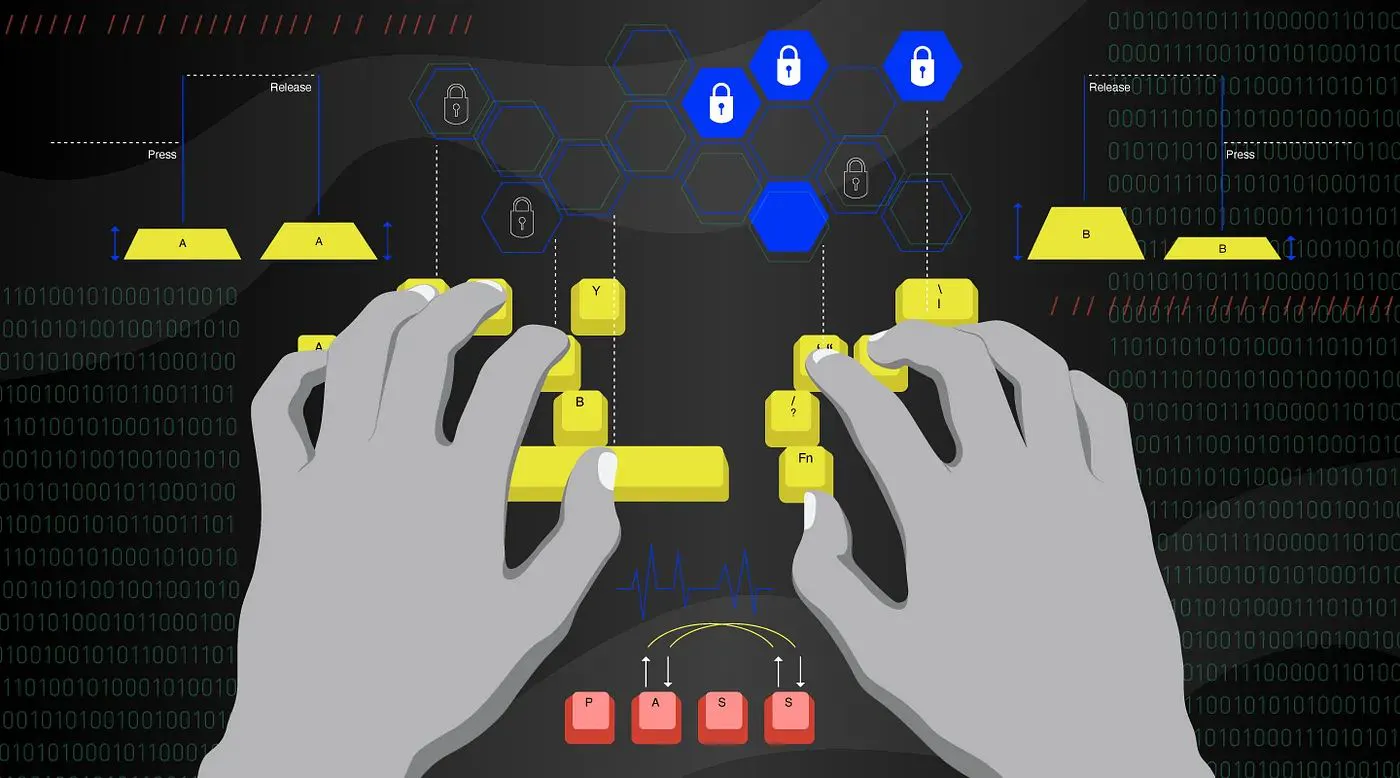


कीस्ट्रोक डायनेमिक्स का उपयोग करके उपयोगकर्ता पहचान के लिए एमएल मॉडल
उपयोगकर्ता की पहचान के लिए इस आलेख के मशीन लर्निंग मॉडल में उपयोग की जाने वाली कीस्ट्रोक गतिशीलता व्यवहारिक बायोमेट्रिक्स है। कीस्ट्रोक डायनामिक्स उस विशिष्ट तरीके का उपयोग करता है जिसे प्रत्येक व्यक्ति अपनी पहचान की पुष्टि करने के लिए टाइप करता है। यह की-प्रेस और की-रिलीज़ पर 2 कीस्ट्रोक घटनाओं का विश्लेषण करके पूरा किया जाता है - जो टाइपिंग पैटर्न निकालने के लिए कंप्यूटर कीबोर्ड पर एक कीस्ट्रोक बनाते हैं।
यह आलेख जांच करेगा कि उपयोगकर्ता पहचान के लिए 3 सटीक मशीन-लर्निंग मॉडल बनाने के लिए इन पैटर्न को कैसे लागू किया जा सकता है।


इस लेख का लक्ष्य दो भागों में विभाजित किया जाएगा, मशीन लर्निंग मॉडल का निर्माण और प्रशिक्षण (1. एसवीएम 2. रैंडम फ़ॉरेस्ट 3. XGBoost ) और 5 इनपुट के आधार पर उपयोगकर्ता की भविष्यवाणी करने में सक्षम वास्तविक लाइव सिंगल पॉइंट एपीआई में मॉडल को तैनात करना। पैरामीटर: एमएल मॉडल और 4 कीस्ट्रोक बार।
1. बिल्डिंग मॉडल
समस्या
इस भाग का उद्देश्य उपयोगकर्ता की पहचान के लिए उनके कीस्ट्रोक डेटा के आधार पर एमएल मॉडल बनाना है। कीस्ट्रोक डायनामिक्स एक व्यवहारिक बायोमेट्रिक है जो किसी व्यक्ति की पहचान को सत्यापित करने के लिए किसी व्यक्ति द्वारा टाइप किए जाने वाले अनूठे तरीके का उपयोग करता है।
टाइपिंग पैटर्न मुख्यतः कंप्यूटर कीबोर्ड से निकाले जाते हैं। कीस्ट्रोक डायनामिक्स में उपयोग किए जाने वाले पैटर्न मुख्य रूप से दो घटनाओं से प्राप्त होते हैं जो कीस्ट्रोक बनाते हैं: की-प्रेस और की-रिलीज़।
की-प्रेस घटना किसी कुंजी के प्रारंभिक अवसाद पर होती है और कुंजी-रिलीज़ उस कुंजी के बाद के रिलीज़ पर होती है।
इस चरण में, उपयोगकर्ताओं की कीस्ट्रोक जानकारी का एक डेटासेट निम्नलिखित जानकारी के साथ दिया गया है:
-
keystroke.csv: इस डेटासेट में, 110 उपयोगकर्ताओं से कीस्ट्रोक डेटा एकत्र किया जाता है। - सभी उपयोगकर्ताओं को 13-लंबाई वाली स्थिर स्ट्रिंग को 8 बार टाइप करने के लिए कहा जाता है और कीस्ट्रोक डेटा (प्रत्येक कुंजी के लिए कुंजी-प्रेस समय और कुंजी-रिलीज़ समय) एकत्र किया जाता है।
- डेटा सेट में 880 पंक्तियाँ और 27 कॉलम हैं।
- पहला कॉलम यूजरआईडी को दर्शाता है और बाकी पहले से 13वें कैरेक्टर के लिए प्रेस और रिलीज का समय दिखाता है।
आपको निम्नलिखित कार्य करना चाहिए:
आमतौर पर, कच्चा डेटा पर्याप्त जानकारीपूर्ण नहीं होता है, और एक अच्छा मॉडल बनाने के लिए कच्चे डेटा से सूचनात्मक विशेषताएं निकालने की आवश्यकता होती है।
इस संबंध में, चार विशेषताएं:
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
परिचय दिया गया है और उनमें से प्रत्येक की परिभाषाएँ ऊपर वर्णित हैं।
2. keystroke.csv, आपको प्रत्येक दो लगातार कुंजियों के लिए ये सुविधाएँ उत्पन्न करनी चाहिए।
3. पिछले चरण को पूरा करने के बाद, आपको प्रति पंक्ति प्रत्येक सुविधा के लिए माध्य और मानक विचलन की गणना करनी चाहिए। परिणामस्वरूप, आपके पास प्रति पंक्ति 8 विशेषताएँ (4 माध्य और 4 मानक विचलन) होनी चाहिए। → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
सभी कोड आप मेरे GitHub पर KeystrokeDynamics रिपॉजिटरी में पा सकते हैं:
विधायकों को प्रशिक्षित करें
अब जब हमने डेटा पार्स कर लिया है तो हम एमएल को प्रशिक्षित करके मॉडल बनाना शुरू कर सकते हैं।
समर्थन वेक्टर यंत्र
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
अतिरिक्त पढ़ना:
बेतरतीब जंगल
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
अतिरिक्त पढ़ना:
अत्यधिक ग्रेडिएंट बूस्टिंग
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
अतिरिक्त पढ़ना:
यदि आपको लेख पसंद आया और आप मेरा समर्थन करना चाहेंगे, तो सुनिश्चित करें:
🔔 मेरे पीछे आओ बोगदान टुडोराचे
🔔 मेरे साथ जुड़ें: लिंक्डइन | reddit








