






















مصنفین :
کے(1) Aman Madaan، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected])
کے(2) Shuyan Zhou، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی Mellon یونیورسٹی، امریکہ ([email protected])
کے(3) Uri Alon، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected])
کے(4) Yiming Yang، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected])
کے(5) Graham Neubig، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected]).
کےAuthors:
(1) Aman Madaan، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected])
(2) Shuyan Zhou، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی Mellon یونیورسٹی، امریکہ ([email protected])
(3) Uri Alon، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected])
(4) Yiming Yang، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected])
(5) Graham Neubig، زبان ٹیکنالوجی انسٹی ٹیوٹ، کارنجی میلون یونیورسٹی، امریکہ ([email protected]).
بائیں میز
2 COCOGEN: کوڈ کے ساتھ Commonsense ساختوں کی نمائندگی کریں اور 2.1 Python کوڈ میں تبدیل کریں (T، G)
2.2 G پیدا کرنے کے لئے چند شو پروموٹنگ
3 تجزیہ اور 3.1 تجرباتی ترتیبات
3.3 entity state tracking: پروپرا
3.4 آرائشی گراف کی پیداوار: EXPLAGRAPHS
6 اختتام، تسلیمات، محدودیتیں اور حوالہ جات
A Few-shot ماڈل سائز کا اندازہ
B Dynamic Prompt پیدا کرنے کے لئے
G ایک ساختہ کام کے لئے Python کلاس ڈیزائن
abstract کے
ہم اس کام کے لئے بڑے زبان کے ماڈل (LMs) کا استعمال کرنے کے لئے، موجودہ نقطہ نظر ڈھانچے اور کنٹینر کے ایک فلیٹ فہرست کے طور پر ڈیٹا ڈھانچے اور کنٹینر ڈھانچے کا استعمال کرتے ہیں: ایک قدرتی زبان کے داخلے کے لۓ، مقصد ایک واقعہ کے طور پر ایک گراف پیدا کرنے کے لئے ہے. اس کام کے لئے بڑے زبان کے ماڈل (LMs) کا استعمال کرنے کے لئے، موجودہ نقطہ نظر ڈھانچے اور کنٹینر کے ایک فلیٹ فہرست کے طور پر پیداوار کے کام کے طور پر پیداوار کے کام کے طور پر پیداوار کے کام کے طور پر پیداوار کے کاموں کو "سریالیز" کرتے ہیں. اگرچہ ممکن ہے، ان سریالیز شدہ گرافز قدرتی زبان کے جسم سے مضبوط طور پر مختلف ہوتے ہیںhttps://github.com/Madaan/ککوجنکے
1 داخلہ
متن پیدا کرنے کے لئے بڑے پہلے سے تربیت یافتہ زبان ماڈلوں (LLMs) کی بڑھتی ہوئی صلاحیتوں نے ان کی کامیابی کے ساتھ ایک قسم کے کاموں میں ان کا استعمال کرنے کی اجازت دی ہے، شامل طور پر خلاصہ، ترجمہ، اور سوالات کا جواب (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
تاہم، قدرتی زبان (NL) کاموں کے لئے LLMs کا استعمال کرنا سادہ ہے، ایک اہم باقی چیلنج یہ ہے کہ کس طرح تجزیہ شدہ عام عقل کے لئے LLMs کا استعمال کرنا ہے، جیسے واقعات کے گراف (Tandon et al., 2019)، منطق گراف (Madaan et al., 2021a)، سکرپٹ (Sakaguchi et al., 2021)، اور بحث وضاحت گراف (Saha et al., 2021). پڑھنے یا سوالات کا جواب دینے کے طور پر روایتی عام عقل کے کاموں کے برعکس، ساختہ عام عقل ایک قدرتی زبان کے داخلے کی طرف سے منظم پیداوار پیدا کرنے کا مقصد ہے. کاموں کا یہ خاندان LLM کی طرف سے سیکھنے والی قدرتی زبان کے علم پر منحصر ہے، لیکن یہ بھی پیچیدہ ساختہ پیش گوئی اور پیدا کرنے کی ضرورت ہے.
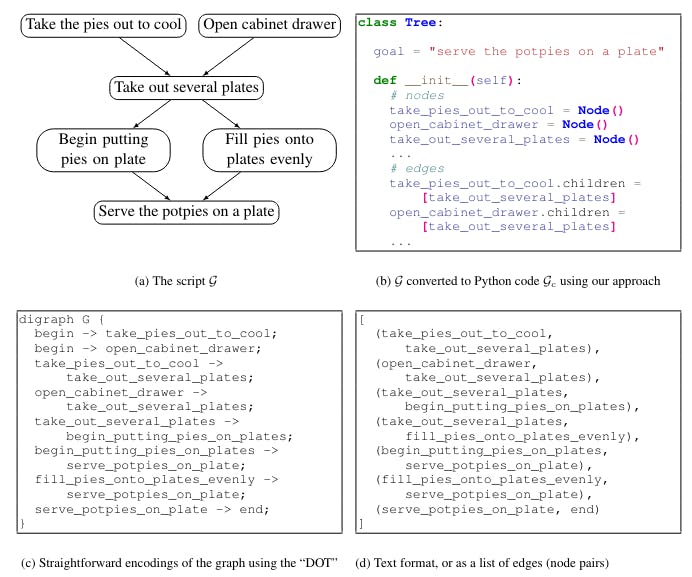
LLMs سے فائدہ اٹھانے کے لئے، موجودہ ساختہ معمول کی پیداوار کے ماڈل ایک مسئلہ کی پیداوار کے فارمیٹ کو تبدیل کرتے ہیں. خاص طور پر، پیدا ہونے والی ساخت (مثال کے طور پر، ایک گراف یا ایک ٹیبل) کو متن میں تبدیل کیا جاتا ہے، یا "سریالیز" کیا جاتا ہے.
اگرچہ ساختہ پیداوار کو ٹیکسٹ میں تبدیل کرنے میں وعدے والا نتائج دکھایا گیا ہے (Rajagopal et al., 2021; Madaan and Yang, 2021), LLMs ان "انفرادی" پیداواروں کو پیدا کرنے کے لئے لڑتے ہیں: LMs بنیادی طور پر مفت فارم ٹیکسٹ پر پہلے سے تربیت دی جاتی ہیں، اور یہ سیریز کیا ساختہ پیداوار پہلے سے تربیت کے اعداد و شمار کی اکثریت سے بہت مختلف ہیں.
لہذا، گراف کی پیداوار کے لئے LLMs کا استعمال کرتے ہوئے عام طور پر ایک بڑے پیمانے پر کام کے مخصوص تربیت کے اعداد و شمار کی ضرورت ہوتی ہے، اور ان کی پیداوار کی پیداوار ساختی غلطیوں اور سمینٹک غیر متوازنیاں دکھاتا ہے، جو manually یا ایک ثانوی نیچے کے ماڈل کا استعمال کرتے ہوئے مزید ٹھیک کرنے کی ضرورت ہے (Madaan et al., 2021b).
ان لڑائیوں کے باوجود، بڑے زبان کے کوڈ ماڈلوں (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) کی حالیہ کامیابیوں کے باوجود، اس طرح کے کاموں کے لئے کوڈ کی پیداوار کی طرف سے قدرتی زبان (Austin et al., 2021; Nijkamp et al., 2022), کوڈ مکمل (Fried et al., 2022) اور کوڈ ترجمہ (Wang et al., 2021), دکھاتا ہے کہ کوڈ-LLMs پروگرامنٹ ڈیٹا جیسے پروگراموں پر پیچیدہ منطق کرنے کے قابل ہیں. اس طرح، مصنوعی زبانوں کے LLMs (NL-LLMs) کو ساختہ عام عقل کے اعداد و شمار پر اچھی طرح سے ترتیب دینے کے بجائے، پہلے تربیت کے اعداد و شمار (فیصلہ متن فارم) اور کام کے مخصوص اعداد و شمار (

لہذا، ہمارا بنیادی نقطہ نظر یہ ہے کہ کوڈ کے بڑے زبان ماڈل اچھے ساختہ منطق ہیں. اس کے علاوہ، ہم دکھاتے ہیں کہ کوڈ LLMs NL-LLMs کے مقابلے میں بھی بہتر ساختہ منطق کر سکتے ہیں، جب مطلوبہ پیداوار گراف کو ایک شکل میں تبدیل کرنے کے طور پر کوڈ کے پہلے تربیت کے اعداد و شمار میں نظر آتا ہے.Coکے لئےCoمذاقGenاس کے نتیجے میں، یہ تصویر 1 میں دکھایا گیا ہے.
ہمارا حصہ مندرجہ ذیل ہے:
- کے
- ہم اس نقطہ نظر کو ظاہر کرتے ہیں کہ Code-LLMs NL-LLMs کے مقابلے میں بہتر تخلیق شدہ منطق ہیں، جب مطلوبہ گراف پیشکش کو کوڈ کے طور پر نمائندگی کرتے ہیں. کے
- ہم COCOGEN کی پیشکش کرتے ہیں: ایک طریقہ کار کوڈ کے LLMs کو منظم ذہن کی پیداوار کے لئے استعمال کرنے کے لئے. کے
- ہم تین ڈھانچے عام عقل کی پیداوار کے کاموں پر ایک وسیع تجزیہ کرتے ہیں اور اس بات کا ثبوت دیتے ہیں کہ COCOGEN NL-LLMs کو بہت بہتر بناتا ہے، فٹ ٹائم یا تھوڑا سا ٹیسٹ کیا جاتا ہے، جبکہ بعد میں کام کی مثالوں کی تعداد کو کنٹرول کرتا ہے. کے
- ہم ایک تفصیلی ablation مطالعہ کرتے ہیں، جس میں ڈیٹا فارمیٹنگ کا کردار، ماڈل سائز، اور تھوڑا سا مثالوں کی تعداد دکھاتا ہے. کے
یہ مضمون CC BY 4.0 DEED لائسنس کے تحت archiv پر دستیاب ہے.
کےیہ کاغذ ہےدستیاب ہے ArchiveCC BY 4.0 DEED لائسنس کے تحت.








