






















Os autores:
Não(1) Aman Madaan, Instituto de Tecnologias da Língua, Universidade Carnegie Mellon, EUA ([email protected]);
Não(2) Shuyan Zhou, Instituto de Tecnologias da Língua, Universidade de Carnegie Mellon, EUA ([email protected]);
Não(3) Uri Alon, Instituto de Tecnologias da Língua, Universidade de Carnegie Mellon, EUA ([email protected]);
Não(4) Yiming Yang, Instituto de Tecnologias da Língua, Universidade de Carnegie Mellon, EUA ([email protected]);
Não(5) Graham Neubig, Instituto de Tecnologias da Língua, Universidade Carnegie Mellon, EUA ([email protected]).
NãoAuthors:
(1) Aman Madaan, Instituto de Tecnologias da Língua, Universidade Carnegie Mellon, EUA ([email protected]);
(2) Shuyan Zhou, Instituto de Tecnologias da Língua, Universidade de Carnegie Mellon, EUA ([email protected]);
(3) Uri Alon, Instituto de Tecnologias da Língua, Universidade de Carnegie Mellon, EUA ([email protected]);
(4) Yiming Yang, Instituto de Tecnologias da Língua, Universidade de Carnegie Mellon, EUA ([email protected]);
(5) Graham Neubig, Instituto de Tecnologias da Língua, Universidade Carnegie Mellon, EUA ([email protected]).
Mesa da Esquerda
2 COCOGEN: Representar estruturas Commonsense com código e 2.1 Converter (T,G) em código Python
2.2 Prompting de poucos disparos para gerar G
3 Avaliação e 3.1 Configuração Experimental
3.2 Geração de roteiro: Prospect
3.3 Rastreamento de estado de entidade: PROPARA
3.4 Geração de gráficos de argumento: EXPLAGRAPHS
6 Conclusão, reconhecimentos, limitações e referências
A Few-shot modelos de tamanho estimado
G. Desenhar uma classe de Python para uma tarefa estruturada
H Impacto do tamanho do modelo
Abstração
Nós abordamos a tarefa geral do raciocínio de sentido comum estruturado de dados: dado uma entrada de linguagem natural, o objetivo é gerar um gráfico como um evento ou um gráfico de raciocínio. Para empregar modelos de linguagem grande (LMs) para esta tarefa, as abordagens existentes “serializam” o gráfico de saída como uma lista plana de nós e bordas. Embora seja viável, esses gráficos serializados desviam-se fortemente da corpora da linguagem natural em que os LMs foram pré-treinados, impedindo que os LMs os gerem corretamente. Neste artigo, mostramos que quando, em vez de enquadrar tarefas de raciocínio comum estruturado como tarefas de geração de código, LMs de código pré-treinados são raciocínios deHTTPS://github.com/madaan/CoCoGen em Portugal. o
1 Introdução
As capacidades crescentes de grandes modelos de linguagem pré-treinados (LLMs) para gerar texto permitiram sua aplicação bem-sucedida em uma variedade de tarefas, incluindo resumo, tradução e resposta a perguntas (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
No entanto, enquanto empregar LLMs para tarefas de linguagem natural (NL) é simples, um grande desafio remanescente é como aproveitar LLMs para raciocínio de senso comum estruturado, incluindo tarefas como gerar gráficos de eventos (Tandon et al., 2019), gráficos de raciocínio (Madaan et al., 2021a), scripts (Sakaguchi et al., 2021), e gráficos de explicação de argumento (Saha et al., 2021). Ao contrário de tarefas de raciocínio de senso comum tradicionais, como compreensão de leitura ou resposta a perguntas, o senso comum estruturado visa gerar saída estruturada dada uma entrada de linguagem natural. Esta família de tarefas depende do conhecimento da língua natural aprendido pelo LLM, mas também requer previsão estruturada complexa e geração.
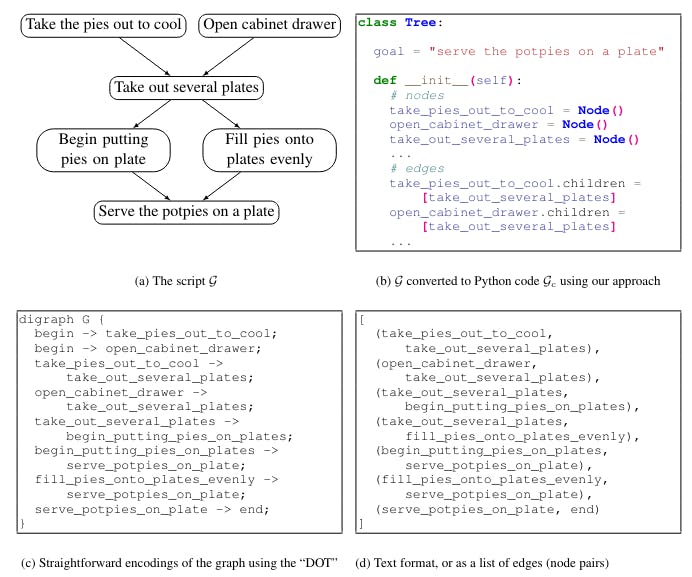
Especificamente, a estrutura a ser gerada (por exemplo, um gráfico ou uma tabela) é convertida, ou “serializada”, em texto. tais conversões incluem “flattening” o gráfico em uma lista de pares de nós (Figura 1d), ou em uma linguagem de especificação como DOT (Figura 1c; Gansner et al., 2006).
Enquanto a conversão da saída estruturada em texto mostrou resultados promissores (Rajagopal et al., 2021; Madaan e Yang, 2021), os LLMs lutam para gerar essas saídas “naturais”: os LMs são principalmente pré-treinados em texto de forma livre, e essas saídas estruturadas serializadas divergem fortemente da maioria dos dados de pré-treinamento.
Consequentemente, o uso de LLMs para a geração de gráficos geralmente requer uma grande quantidade de dados de treinamento específicos de tarefas, e suas saídas geradas mostram erros estruturais e inconsistências semânticas, que precisam ser corrigidas ainda mais manualmente ou usando um modelo subsequente secundário (Madaan et al., 2021b).
Apesar destas lutas, o recente sucesso dos modelos de código de grande linguagem (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) para tarefas como a geração de código a partir da linguagem natural (Austin et al., 2021; Nijkamp et al., 2022), a conclusão de código (Fried et al., 2022), e a tradução de código (Wang et al., 2021), mostram que os Code-LLMs são capazes de executar raciocínios complexos em dados estruturados, como programas. Assim, em vez de forçar os LLMs de linguagem natural (NL-LLMs) a serem finamente ajustados em dados de sentido comum estruturados, uma maneira mais fácil de fechar a discrepância entre os dados de pré-treinamento (forma de texto livre) e os dados específicos de

Assim, nossa visão principal é que grandes modelos de linguagem de código são bons raciocínios de bom senso comum estruturados. Além disso, mostramos que os Code-LLMs podem ser raciocínios ainda melhor estruturados do que os NL-LLMs, ao converter o gráfico de saída desejado em um formato semelhante ao observado nos dados de pré-treinamento de código.CoPara oCoMônicaGenEvolução, que é demonstrada na Figura 1.
Nossas contribuições são as seguintes:
- Não
- Destacamos a visão de que os Code-LLMs são raciocínios de bom senso melhor estruturados do que os NL-LLMs, quando representam a previsão gráfica desejada como código. Não
- Nós propomos COCOGEN: um método para aproveitar LLMs de código para geração de senso comum estruturado. Não
- Realizamos uma avaliação abrangente em três tarefas estruturadas de geração de senso comum e demonstramos que a COCOGEN supera muito os NL-LLMs, seja finamente ajustados ou testados com poucas fotografias, enquanto controla o número de exemplos de tarefas a jusante. Não
- Realizamos um estudo de ablação completo, que mostra o papel da formatação de dados, o tamanho do modelo e o número de exemplos de poucas imagens. Não
Este artigo está disponível em arquivo sob a licença CC BY 4.0 DEED.
NãoEste artigo está disponível em arquivo sob a licença CC BY 4.0 DEED.








