






















著者:
♪(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
♪(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
♪(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
♪(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
♪(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
♪Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected])
左のテーブル
3.3 Entity state tracking: PROPARA
抽象
自然言語の入力として、目標はイベントや論理グラフなどのグラフを生成することである。このタスクに大規模な言語モデル(LMs)を用いるために、既存のアプローチは、構造化された共通認識の出力グラフをノードとエッジの平らなリストとして「シリアリズム化」します。実行可能であるにもかかわらず、これらのシリアリズム化されたグラフは、LMsが事前に訓練された自然言語体から大きく異なり、LMsが正しく生成するのを妨げます。この論文では、我々が構造化された共通認識の論理タスクを生成コードタスクとして枠組みする代わりに、コードの事前訓練されたLMsは、https://github.com/マダン/ココゲンで。
1 導入
テキスト生成のための大規模な事前訓練された言語モデルの能力の増加により、概要化、翻訳、および質問回答を含むさまざまなタスクで成功した(Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022)。
それにもかかわらず、自然言語(NL)のタスクのためのLLMを雇用することは単純であるが、主要な残留課題は、イベントグラフ(Tandon et al. 2019)、推論グラフ(Madaan et al. 2021a)、スクリプト(Sakaguchi et al. 2021)、および論点説明グラフ(Saha et al. 2021)などのイベントグラフ(Tandon et al. 2019)、推論グラフ(Madaan et al. 2021a)などのタスクを含む構造化された常識推論のためのLLMをどのように活用するかである。
具体的には、生成される構造(例えば、グラフまたはテーブル)は、テキストに変換される、または「連続化」される。
構造化された出力をテキストに変換することは有望な結果を示しているが(Rajagopal et al., 2021; Madaan and Yang, 2021), LLMsはこれらの「不自然な」出力を生成するために苦労している: LMsは主にフリー形式のテキストでプレトレーニングされ、これらの連続化された構造化された出力は、プレトレーニングデータの大半とは大きく異なります。
したがって、グラフ生成のためのLLMの使用は、通常、タスク特有のトレーニングデータの大量を必要とし、それらの生成された出力は構造的なエラーとセマンティックの不一致を示し、手動または二次的な下流モデルを使用してさらに修正する必要がある(Madaan et al., 2021b)。
これらの闘いにもかかわらず、コードの大言語モデルの最近の成功(Code-LLMs; Chen et al., 2021b; Xu et al., 2022)は、自然言語からのコード生成(Austin et al., 2021; Nijkamp et al., 2022)、コード完成(Fried et al., 2022)、およびコード翻訳(Wang et al., 2021)などのタスクのために、Code-LLMsは、プログラムなどの構造化されたデータで複雑な推論を実行することができることを示しています。

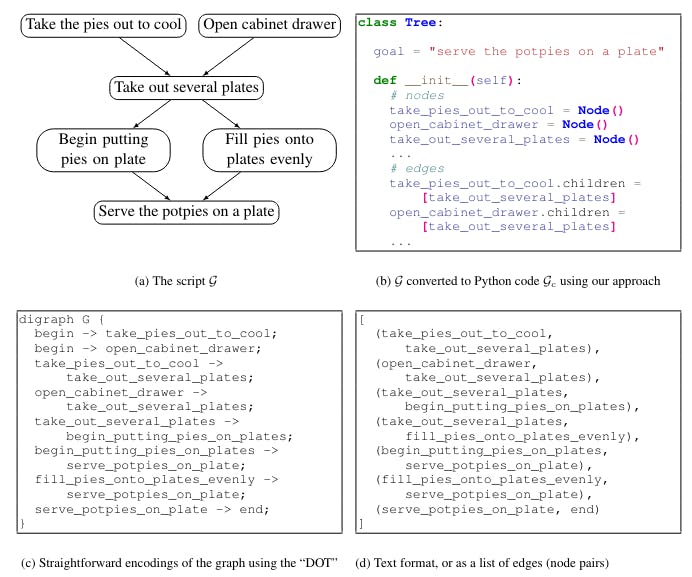
したがって、私たちの主な洞察は、コードの大きな言語モデルが良好な構造化された常識推理であるということです。さらに、私たちは、コードLLMsは、必要な出力グラフをコードプレトレーニングデータで観察されたものに似たフォーマットに変換するときに、NL-LLMsよりもさらに良い構造化された推理者であることを示しています。CoDE FORCoムンセンスGenエレクトロニクスは、図1で示されています。
私たちの貢献は以下の通りです。
- ♪
- We highlight the insight that Code-LLMs are better structured common sense reasoners than NL-LLMs, when representing the desired graph prediction as code. 私たちは、Code-LLMsは、コードとして望ましいグラフ予測を表すとき、NL-LLMsよりも、より良い構造化された常識推論家であるという洞察を強調します。 ♪
- 私たちはCOCOGENを提案します:構造化された常識の生成のためにコードのLLMを活用する方法。 ♪
- 我々は3つの構造化された常識生成タスクを対象に幅広い評価を実施し、下流タスクの例の数をコントロールしながら、細かい調整または少数のショットでテストされたNL-LLMsを大幅に上回ることを示しています。 ♪
- 私たちは、データ形式化の役割、モデルサイズ、および数少ないショットの例の数を示す徹底的な除去研究を実施します。 ♪
この論文は CC BY 4.0 DEED ライセンスの下で archiv で利用できます。
♪この論文は CC BY 4.0 DEED ライセンスの下で archiv で利用できます。








