






















Los autores:
y(1) Aman Madaan, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
y(2) Shuyan Zhou, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
y(3) Uri Alon, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
y(4) Yiming Yang, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
y(5) Graham Neubig, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]).
yAuthors:
(1) Aman Madaan, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
(2) Shuyan Zhou, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
(3) Uri Alon, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
(4) Yiming Yang, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]);
(5) Graham Neubig, Instituto de Tecnologías Lingüísticas, Universidad de Carnegie Mellon, Estados Unidos ([email protected]).
Mesa de la izquierda
2 COCOGEN: Representar estructuras de Commonsense con código y 2.1 Convertir (T,G) en código Python
2.2 Prueba de disparo para generar G
3 Evaluación y 3.1 Configuración experimental
3.2 Generación de guión: Prospect
3.3 Seguimiento del estado de la entidad: PROPARA
3.4 Generación de gráficos de argumentos: EXPLAGRAPHS
6 Conclusión, reconocimientos, limitaciones y referencias
A Few-shot modelos de tamaño estimado
G Diseñar una clase de Python para una tarea estructurada
Abstracción
Para emplear modelos de lenguaje grande (LM) para esta tarea, los enfoques existentes “serializan” el gráfico de salida como una lista plana de nodos y bordes: aunque sea factible, estos gráficos serializados se desvían fuertemente de la corporación del lenguaje natural en la que los LMs fueron pre-entrenados, impidiendo que los LMs los generen correctamente. En este documento, mostramos que cuando en lugar de enmarcar las tareas de razonamiento del sentido común estructuradas como tareas de generación de códigos, los LMs de código pre-entrenados son mejores razonadores de sentido común estructurados que los LMs de lengua natural, incluso cuando la tarea a continuación no implica el código fuente en absoluto. Demostramos nuestro enfoque en tres tareasHTTPS://github.com/madaan/CoCoGen. el
1 Introducción
Las capacidades crecientes de los grandes modelos de lenguaje pre-entrenados (LLM) para la generación de texto han permitido su aplicación exitosa en una variedad de tareas, incluyendo la resumida, la traducción y la respuesta a preguntas (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
Sin embargo, mientras que el empleo de LLMs para tareas de lengua natural (NL) es sencillo, un gran desafío sigue siendo cómo aprovechar los LLMs para el razonamiento de sentido común estructurado, incluyendo tareas como generar gráficos de eventos (Tandon et al., 2019), gráficos de razonamiento (Madaan et al., 2021a), scripts (Sakaguchi et al., 2021), y gráficos de explicación de argumentos (Saha et al., 2021). A diferencia de las tareas de razonamiento de sentido común tradicionales como la comprensión de la lectura o la respuesta a preguntas, el sentido común estructurado tiene como objetivo generar una salida estructurada dada una entrada de lengua natural.
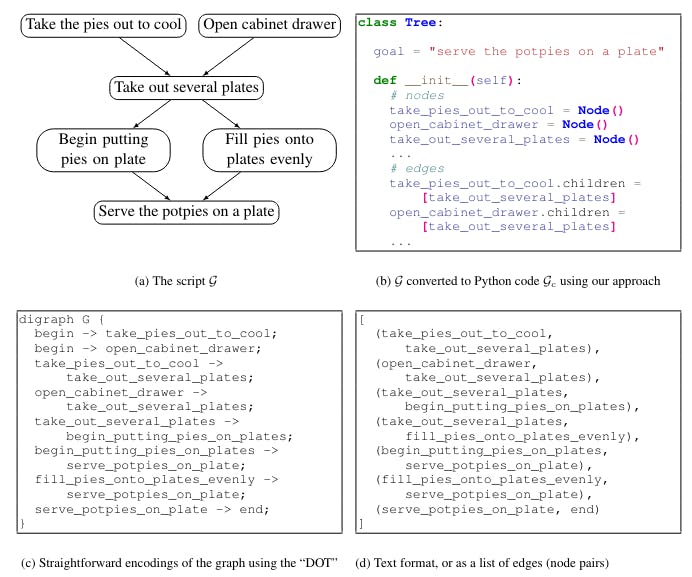
Para aprovechar los LLM, los modelos de generación de sentido común estructurados existentes modifican el formato de salida de un problema. Especificamente, la estructura a generar (por ejemplo, un gráfico o una tabla) se convierte, o "serializado", en texto.
Mientras que la conversión de la salida estructurada en texto ha mostrado resultados prometedores (Rajagopal et al., 2021; Madaan y Yang, 2021), los LLM luchan para generar estas salidas "innaturales": los LM son principalmente pre-entrenados en texto de forma libre, y estas salidas estructuradas serializadas difieren fuertemente de la mayoría de los datos pre-entrenamiento.
Por lo tanto, el uso de LLMs para la generación de gráficos suele requerir una gran cantidad de datos de capacitación específicos de tareas, y sus resultados generados muestran errores estructurales e inconsistencias semánticas, que deben ser corregidas más adelante, ya sea manualmente o mediante el uso de un modelo secundario a continuación (Madaan et al., 2021b).
A pesar de estas luchas, el reciente éxito de los modelos de código de gran lenguaje (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) para tareas como la generación de código de lenguaje natural (Austin et al., 2021; Nijkamp et al., 2022), la finalización de código (Fried et al., 2022), y la traducción de código (Wang et al., 2021), muestran que los LLMs de código son capaces de realizar razonamientos complejos sobre datos estructurados como programas. Así, en lugar de forzar a los LLMs de lenguaje natural (NL-LLMs) a ser ajustados a datos estructurados de sentido común, una forma más fácil de cerrar la discrepancia entre los datos de pre-entrenamiento (forma de texto libre) y los datos específicos de tareas

Así, nuestra visión principal es que los grandes modelos de lenguaje de código son buenos razonadores de sentido común estructurados. Además, mostramos que los Code-LLMs pueden ser razonadores estructurados aún mejor que los NL-LLMs, al convertir el gráfico de salida deseado en un formato similar al observado en los datos de pre-entrenamiento de código. llamamos nuestro método COCOGEN: modelos deCode porCoMuñozGenEvolución, y se muestra en la Figura 1.
Nuestras contribuciones son las siguientes:
- y
- Destacamos la visión de que los LLM de Código son razonadores de sentido común mejor estructurados que los LLM de NL, cuando representan la predicción gráfica deseada como código. y
- Proponemos COCOGEN: un método para aprovechar los LLM de código para la generación estructurada de sentido común. y
- Realizamos una evaluación exhaustiva en tres tareas estructuradas de generación de sentido común y demostramos que COCOGEN supera enormemente a los NL-LLM, ya sea ajustados o probados con pocos disparos, al tiempo que controlamos el número de ejemplos de tareas a continuación. y
- Realizamos un estudio de ablación exhaustivo, que muestra el papel de la formatación de datos, el tamaño del modelo y el número de ejemplos de pocos disparos. y
Este artículo está disponible en archivo bajo la licencia CC BY 4.0 DEED.
yEste artículo está disponible en archivo bajo la licencia CC BY 4.0 DEED.








