






















Նրա գրասենյակներ :
Հիմնական(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
Հիմնական(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
Հիմնական(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
Հիմնական(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
Հիմնական(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
ՀիմնականAuthors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, ԱՄՆ ([email protected])
Հեղինակային փաթեթներ
2.2.2 Կատեգորիաների բաղադրիչները G- ն ստեղծելու համար
3 Հյուրատետր եւ 3.1 Հյուրատետր փորձառույթներ
4.2 Սպիտակային արտադրություն: Proscript
3.3 Արդյունաբերության վերահսկողություն: PROPARA
3.4 Սպիտակների գրաֆիկների արտադրություն: EXPLAGRAPHS
6 Հասկածություն, հավատումներ, սահմանափակումներ եւ տեղեկություններ
A Few-Shot մոդելների չափը ծախսերը
G- ը Python- ի դասընթացների նախագծման համար կառուցված գործառույթների համար
H-ը մոդելային չափի ազդեցությունը
Ապրիլ
Մենք լուծում ենք կառուցված տվյալների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչների բաղադրիչներիhttps://github.com/madaan/ԱյսինեԱրդյոք
1 Առաջարկ
Բարձր պրոֆեսիոնալ լեզուների մոդելների (LLMs) արտադրման համար մեծ պրոֆեսիոնալ լեզուի մոդելների (LLMs) աճող հզորությունը թույլ է տալիս նրանց հաջողությամբ օգտագործման համար տարբեր գործերի, այդ թվում, միասնականացման, अनुवादման եւ հարցերի պատասխանների (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
Սակայն, երբ աշխատում LLMs համար բնական լեզուների (NL) գործիքները պարզ է, մի հիմնական վերականգնում է, թե ինչպես է օգտագործել LLMs համար կառուցված բուժում, այդ թվում են գործիքներ, ինչպիսիք են արտադրում գործառույթների գծեր (Tandon et al., 2019), բուժում գծեր (Madaan et al., 2021a), գրասենյակներ (Sakaguchi et al., 2021), եւ բուժում բացահայտման գծեր (Saha et al., 2021). Հիմնական բուժում գործառույթներ, ինչպիսիք են կարդալ իմանալ կամ հարցերի պատասխանը, կառուցված բուժում նպատակն է արտադրել կառուցված արտադրանքը, քանի որ բուժում է բնական լեզուների ներքեւում. Այս գործառույթների ընտանիքը հիմնված է բուժ
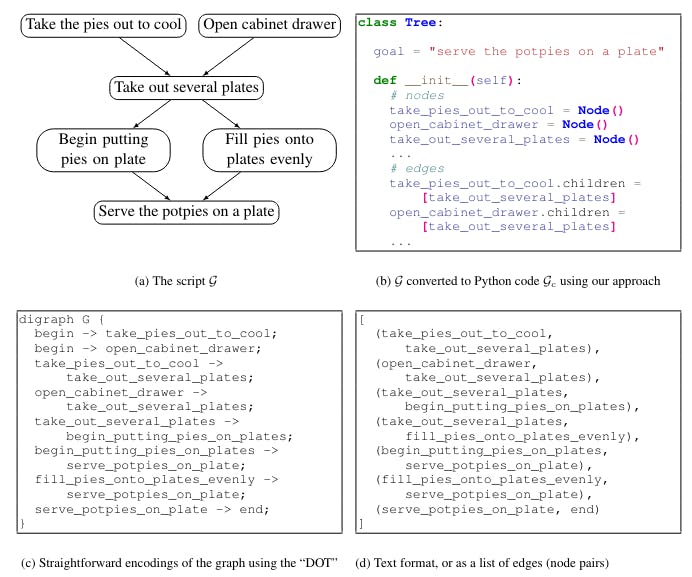
Բարձրապես, սերտիֆիկը, որը ստեղծվում է (հարկե, սերտիֆիկը կամ սերտիֆիկը) փոխվում է, կամ «սերտիֆիկացված է», տեքստով: Այս տեսակի փոխանակումներ ներառում են սերտիֆիկի «պլատացումը» սերտիֆիկի համար սերտիֆիկի սերտիֆիկների ցուցակը (հարկե 1d), կամ սերտիֆիկայի լեզվով, ինչպիսիք են DOT (հարկե 1c; Gansner et al., 2006).
Երբ կառուցված արտադրանքը տեքստի փոխելու համար ցույց է տալիս հուսալի արդյունքները (Rajagopal et al., 2021; Madaan and Yang, 2021), LLM-ները փորձում են արտադրել այդ «նեքիալ» արտադրանքը: LM-ները հիմնականում նախապատրաստված են անվճար ձեւային տեքստի վրա, եւ այդ serialized կառուցված արտադրանքը հուսալիորեն տարբերվում են նախապատրաստման տվյալների մեծամասնության հետ: Բացի այդ, բնական լեզուների համար, սենմետիկորեն relevant խոսքները սովորաբար գտնվում են փոքր լայնության ընթացքում, իսկ գրաֆի ներքին կետերը կարող են հեռանալ ավելի երկար, երբ գրաֆը ցուցադրվում է որպես հարված գծի:
Այսպիսով, օգտագործելով LLM- ները գրաֆիկային արտադրման համար սովորաբար պահանջում է մեծ քանակը աշխատանքային մասնավոր դասընթացային տվյալները, եւ նրանց արտադրված արտադրանքը ցույց են տալիս կառուցվածքի սխալները եւ սմարթային անսահմանափակությունները, որոնք պետք է ավելին վերահսկվել կամ մանրաֆիկորեն կամ օգտագործելով բարդ ներքեւում մոդել (Madaan et al., 2021b).
Բացի այդ երջանիկների, վերջին հաջողությունը մեծ լեզուների մոդելների կոդը (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) համար գործիքների, ինչպիսիք են մոդելային մոդելային մոդելային մոդելային մոդել (Austin et al., 2021; Nijkamp et al., 2022), մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդելային մոդ

Այսպիսով, մեր հիմնական իմանալը այն է, որ մեծ լեզուային մոդելներ կոդը են լավ կառուցված բաղադրիչներ. Բացի այդ, մենք ցույց ենք տալիս, որ Code-LLMs կարող են լինել նաեւ ավելի լավ կառուցված բաղադրիչներ, քան NL-LLMs, երբ փոխել ցանկացած արտադրանքի մոդելը ձեւաչափով, ինչպիսիք են այն, ինչպիսիք են ստուգված է Code- ի նախապատրաստման տվյալների. Մենք կոչում ենք մեր մեթոդը COCOGEN: մոդելներCoԴու համարCoՄոմսենսGenԱրդյոք, եւ դա ցույց է տալիս, որ սխալը 1.
Մեր գործառույթները հետեւյալ են:
- Հիմնական
- Մենք բացահայտում ենք, որ Code-LLMs- ը ավելի լավ կառուցված է, քան NL-LLMs- ը, երբ ցանկացած գրաֆիկի նախընտրականությունը ցուցադրում է որպես կոդը: Հիմնական
- Մենք առաջարկում ենք COCOGEN: մեթոդ, որը օգտագործում է LLM- ների կոդը կառուցված բաղադրիչների արտադրության համար: Հիմնական
- Մենք կատարում ենք խոշոր արժեքագրություն երեք կառուցված բուժական բուժական բուժական գործիքների վրա եւ ցույց ենք տալիս, որ COCOGEN- ը լայնորեն գերազանցում է NL-LLM- ները, այնպես որ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ, այնպես էլ: Հիմնական
- Մենք կատարում ենք ներգրավված ablation ուսումնասիրություն, որը ցույց է տալիս տվյալների ձեւավորումը, մոդել չափը, եւ քիչ-սրթ օրինակների չափը: Հիմնական
Այս գրասենյակը հասանելի է CC BY 4.0 DEED License- ի կողմից.
ՀիմնականԱյս թերթըԱրդյոք հասանելի էCC BY 4.0 DEED լուսավորումը.








