






















የቅጂ መብት:
አግኙን(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, ዩናይትድ ስቴትስ ([email protected])
አግኙን(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, ዩናይትድ ስቴትስ ([email protected]);
አግኙን(3) Uri Alon, Language Technologies Institute, Carnegie Mellon ዩኒቨርሲቲ, የአሜሪካ ([email protected])
አግኙን(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon ዩኒቨርሲቲ, የአሜሪካ ([email protected])
አግኙን(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, ዩናይትድ ስቴትስ ([email protected]).
አግኙንAuthors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, ዩናይትድ ስቴትስ ([email protected])
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, ዩናይትድ ስቴትስ ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon ዩኒቨርሲቲ, የአሜሪካ ([email protected])
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon ዩኒቨርሲቲ, የአሜሪካ ([email protected])
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, ዩናይትድ ስቴትስ ([email protected]).
የመስመር ላይ ገጾች
2 COCOGEN: ኮድ ጋር Commonsense መዋቅርዎችን ያተኮሩ እና 2.1 Python ኮድ ወደ (T,G) ያተኮሩ
3.4 አግኝቷል Graph Generation: EXPLAGRAPHS
6 መውሰድ, የምስክር ወረቀት, መስፈርቶች እና መለያዎች
አጠቃቀም
የ LMs (Language Models) ይህ ተግባር ለማግኘት, የ LMs (Language Models) በመተግበሪያውን ኮድ መተግበሪያዎች እንደ የኮድ መተግበሪያዎች እንደ የኮድ መተግበሪያዎች እንደ የኮድ መተግበሪያዎች እንደ የኮድ መተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተግበሪያዎች በመተhttps://github.com/madaan/ኮኮንያግኙ
1 መውሰድ
ግምገማዎችን ለመፍጠር የላቀ የተመሠረተ ቋንቋ ሞዴሎች (LLMs) ልማት ችሎታዎች በይነመረብ, ግምገማዎች እና ጥያቄዎች መልስ (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022) ጨምሮ የተለያዩ ሥራዎች ላይ ተስማሚ መተግበሪያዎችን ያደርጋል.
በተጨማሪም የ LLMs ለወደፊቱ ቋንቋዎች (NL) ሥራዎች መተግበሪያዎች ቀላል ነው, የ LLMs ለወደፊቱ ግምገማዎች (Tandon et al., 2019), ለወደፊቱ ግምገማዎች (Madaan et al., 2021a), ለወደፊቱ ግምገማዎች (Sakaguchi et al., 2021) እና ለወደፊቱ ግምገማዎች (Saha et al., 2021) እንደ ተሳታፊዎች (Tandon et al., 2019), ለወደፊቱ ግምገማዎች (Madaan et al., 2021a), ለወደፊቱ ግምገማዎች (Sakaguchi et al., 2021), እና ለወደፊቱ ግምገማዎች (Saha et al., 2021) መተግበሪያዎች እንዴት ይጠቀማል. የወደፊቱ ግ
ለ LLMs ለማሳየት, የአሁኑ የተመሠረተ ቅርጸት አጠቃቀም ሞዴሎች አንድ ችግር ውፅዓት ቅርጸት ለማሻሻል. ልዩነት, ለመፍጠር የሚሆን መዋቅር (እን.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.ኤ.
በ 2021; Madaan እና Yang, 2021), የ LLMs እነዚህን "የተፈጠራ" ውፅዓት ለመፍጠር ይሞክሩ: LMs በዋናነት ነፃ ቅርጽ ጽሑፍ ላይ የተመሠረተ ናቸው, እና እነዚህ serialized የተመሠረተ ውፅዓት በከፍተኛ ደረጃ ከባድ-ተፈጠራ ውሂብ መካከል አብዛኞቹ ከረጅም ጊዜ ይወዳሉ. በተጨማሪም, ለወደፊቱ ቋንቋ, የሴሜኒካዊ ተስማሚ ጥያቄዎች አብዛኛውን ጊዜ አንድ አነስተኛ ስፋት ውስጥ ይገኛሉ, እና አንድ ካርታ ውስጥ ተስማሚ ቅርጸቶች አንድ ካርታ እንደ ተስማሚ ቅርጸት ለመምረጥ ጊዜ ይበልጥ ይሸፍናል.
እንደዚህ, አንድ ቋንቋ ሞዴል, ይህም በተፈጥሮ ቋንቋ ጽሑፍ ላይ የተመሠረተ ነበር, የኮምፒዩተር የኮምፒዩተር የኮምፒዩተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒውተር የኮምፒው
የኮድ-LLMs (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) የኮድ ማምረት (Austin et al., 2021; Nijkamp et al., 2022), የኮድ ማጠናቀቅ (Fried et al., 2022) እና የኮድ መተግበሪያ (Wang et al., 2021) እንደ የኮድ-LLMs (Code-LLMs, 2021b; Xu et al., 2022) የኮድ ማምረት (Austin et al., 2021; Nijkamp et al., 2022), የኮድ ማጠናቀቅ (Fried et al., 2022), እና የኮድ መተግበሪያ (Wang et al., 2021), በኮድ-LLMs (Code-LLMs) እንደ ፕሮግራሞች እንደ የተመሠረተ ውሂብ ላይ ተስማሚ ግምገማ

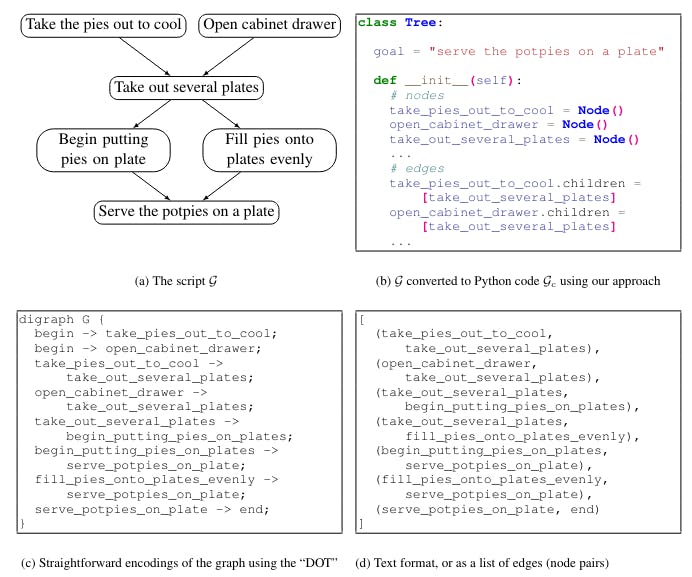
በተጨማሪም, Code-LLMs ከ NL-LLMs በላይ ይበልጥ ይበልጥ ይበልጥ ይበልጥ የተመሠረተ ይበልጥ ሊሆን ይችላል, በእርስዎ የሚፈልጉ ውፅዓት ካርታን በኮድ pre-training ውሂብ ውስጥ ተመሳሳይ ቅርጸት ወደ ተመሳሳይ ቅርጸት ለማስተዋወቅ ጊዜ.CoለCoአግኙንGenየኦሪጂናል አጠቃቀም, እና በ Figure 1 ውስጥ ያነሰ ነው.
የእኛ ክፍሎች የሚከተሉት ናቸው:
- አግኙን
- እኛ Code-LLMs ከ NL-LLMs በላይ የተመሠረተ ቅርጸቶች ናቸው, በኮድ እንደ የሚፈልጉ የ Graph prediction ያደርጋል ጊዜ. አግኙን
- እኛ COCOGEN ይሰጣሉ: የኮድ የ LLMs ለመሠረተ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ለማግኘት. አግኙን
- የ COCOGEN የ NL-LLMs በ 3 የተመሠረተ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ ጥንካሬ አግኙን
- የእኛን ግምገማዎች በይነገጽ እና በይነገጽ እና በይነገጽ እና በይነገጽ እና በይነገጽ እና በይነገጽ እና በይነገጽ እና በይነገጽ እና በይነገጽ ነው.We perform a thorough ablation study, which shows the role of data format, model size, and the number of few-shot examples. አግኙን
ይህ ጽሑፍ በ CC BY 4.0 DEED License ላይ archiv ላይ ይገኛል.
አግኙንይህ ጽሑፍ በ CC BY 4.0 DEED License ላይ archiv ላይ ይገኛል.








