






















Зохиогчийн эрх :
Өнгөрсөн(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
Өнгөрсөн(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
Өнгөрсөн(3) Uri Alon, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
Өнгөрсөн(4) Yiming Ян, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
Өнгөрсөн(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]).
ӨнгөрсөнAuthors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
(4) Yiming Ян, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]);
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon их сургууль, АНУ-ын ([email protected]).
Тавтай мод
2 COCOGEN: Код нь Commonsense бүтэц үзүүлэх, 2.1 Python код руу (T,G) хувиргах
2.2 G-г үүсгэхийн тулд хэд хэдэн утга
3 Үзүүлэлт, 3.1 Эксперименталь суурилуулах
3.2 Скрипт генераци: PROSCRIPT
3.3 Судалгааны нөхцөл Tracking: PROPARA
3.4 Аргумент график үүсгэх: EXPLAGRAPHS
6 Сэдэв, хүлээн зөвшөөрөл, хязгаарлалт, гарын авлага
A Few-Shot загварууд хэмжээ тооцоо
G структурын ажлын хувьд Python-ийн ангиллын зураг төсөл
Эдүүлбэр
Бид бүтэцтэй өгөгдлийн харьцуулалтын ерөнхий үйл явцад харьцуулахад: байгалийн хэлний эх үүсвэрийг хангахын тулд үйл явц эсвэл харьцуулалтын график шиг график үүсгэх зорилго юм. Энэ үйл явцад том хэлний загвар (LMs) ашиглахын тулд одоогийн арга замыг нунтаг, нунтаг болон богиноны хавтгай жагсаалттай жагсаалттай жагсаалттай жагсаалттай график "сериализац" болгож байна. Үнэндээ тохиромжтой боловч эдгээр харьцуулагдсан график нь LMs-ийг урьдчилан боловсруулсан байгалийн хэлний корпусээс хүчтэй харьцуулахад LMs-ийг зөв үүсгэхын тулд хязгаарлагддаг. ЭнэHTTPS://github.com/madaan/ХуувцаслалтҮйлчилгээ
1 Үйлчилгээ
Бүтээгдэхүүний текст үүсгэхийн тулд том урьдчилан боловсруулсан хэлний загвар (LLMs) нь ихээхэн нэмэгдэж буй хүчин чадал нь ихэвчлэн хуваалцлага, хуваалцлага, асуулт хариу (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
Гэсэн хэдий ч, байгалийн хэлний (NL) үйл ажиллагаа нь LLM-ийг ашиглах нь хялбар юм боловч чухал ач холбогдол нь структурирован ач холбогдолтой ач холбогдол нь LLM-ийг хэрхэн ашиглах вэ (Tandon et al., 2019), ач холбогдолтой график (Madaan et al., 2021a), скрипт (Sakaguchi et al., 2021) болон аргументийн ач холбогдолтой график (Saha et al., 2021) зэрэг ач холбогдолтой ач холбогдолтой график (Tandon et al., 2019), ач холбогдолтой график (Madaan et al., 2021a), ач холбогдолтой график (Sakaguchi et al., 2021), ач холбогдолтой ач холбогдолтой ач холбогдолтой ач холбогдолтой ач холбогдолтой ач холбогдол
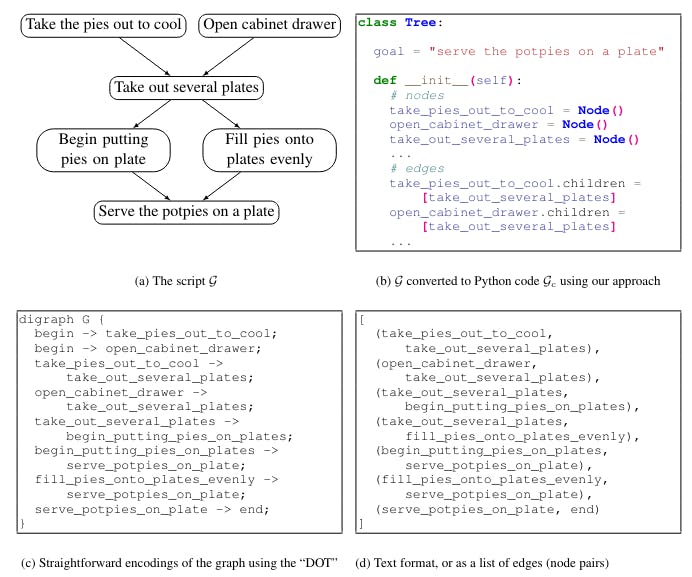
LLM-ийг ашиглахын тулд одоогийн структурын зэргийн үүсгэх загварууд нь асуудалны output формат өөрчилж байна. Жишээлбэл, үүсгэдэг бүтэц (жишээ нь график, тавцан) текстийг хувиргадаг, эсвэл "сериализсэн" байдаг. Тавтай морилно уу, график нь нодоод бүтэцний жагсаалтанд "flattening" (жишээ нь 1d), эсвэл DOT (жишээ нь 1c; Gansner et al., 2006).
Бүтээгдэхүүний талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаархи талаар
Тэгэхээр, график үүсгэх нь LLM-ийг ашиглах нь ихэвчлэн үйл ажиллагааны тусгай сургалтын өгөгдлийн том хэмжээтэй шаарддаг, тэдний үүсгэгдсэн outputs структурын алдаа, семантик нягтралтыг харуулсан, энэ нь manually эсвэл доорх доорх загвар ашиглан дэлгэрэнгүй тохируулах хэрэгтэй (Madaan et al., 2021b).
Эдгээр борлуулалттай харьцуулахад шилдэг хэлний код загвар (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) -ийн шилдэг хэлний загвар (Austin et al., 2021; Nijkamp et al., 2022), код тохиргооны (Fried et al., 2022), болон код хувилбар (Wang et al., 2021) -ийн хамгийн сүүлийн үеийн амжилт нь Code-LLMs нь програмууд гэх мэт структурын өгөгдлийн талаар цуглуулах боломжийг олгодог. Иймээс, алдартай хэлний LLMs (NL-LLMs) нь структурын мэдэлийн өгөгдлийн талаар нарийн тохиргооны байхыг хүсч байгаа бол, өмнөх сургалтын өгөгдлийн (free-text-form) болон үйл ажиллагаатай холбоотой өгөгдлийн (common-

Тиймээс бидний гол мэдлэг нь код нь том хэлний загвар нь сайн структурирован ач холбогдол юм. Дараа нь бид Code-LLM-ийг NL-LLM-иас илүү сайн структурирован ач холбогдолтой байж болохыг харуулдаг. Бид кодын өмнөх сургалтын өгөгдлийн талаархи хэлбэрээр хүссэн output graph-ийг хувиргах үед бидний арга нь COCOGEN гэж нэрлэдэг:CoЗагварCoМэндэлснийGenээрэг, энэ нь зураг 1.
Бидний туслалтууд дараах юм:
- Өнгөрсөн
- Бид Code-LLM-ийг NL-LLM-ийг харьцуулахад илүү тохиромжтой суралцагч юм гэж үздэг. Өнгөрсөн
- Бид COCOGEN санал болгож байна: бүтэцтэй ач холбогдолтой генерацид кодны LLM-ийг ашиглах арга. Өнгөрсөн
- Бид гурван бүтэцтэй ач холбогдол үүсгэх үйл явдал дээр өргөн үнэлгээ хийх, COCOGEN нь нэрийн тохиргооны эсвэл хязгаарлагдмал туршиж байгаа NL-LLM-ийг маш их сайжруулдаг бөгөөд дараах үйл явдал нь ихэвчлэн хянаж байна. Өнгөрсөн
- Бид өгөгдлийн форматинг, загварын хэмжээ, хэд хэдэн шатанд дээж тоо гэж үздэг нарийвчлалтай абрацийн судалгаа хийх. Өнгөрсөн
Энэ нийтлэл нь CC BY 4.0 DEED лицензийн дагуу archiv дээр байдаг.
ӨнгөрсөнЭнэ нийтлэл нь CC BY 4.0 DEED лицензийн дагуу archiv дээр байдаг.




