























Я тестировал 7 самых популярных моделей ИИ, чтобы увидеть, насколько хорошо они обрабатывают счета-фактуры вне коробки, без каких-либо тонкостей.
Читайте для того, чтобы узнать:
- Какая модель превосходит все остальные по крайней мере на 20% →
- Почему Google не работает со структурированными данными →
- Узнайте, какие модели лучше всего справляются со сканерами низкого разрешения →
Проверенные модели
Чтобы достичь цели этого теста, я начал поиск моделей ИИ, используя эти критерии:
- →
- Популярность: Популярные модели имеют лучшую поддержку и документацию. →
-
Invoice Processing Capability: The model needs to be able to process invoices from the get-go, without fine-tuning or training the API.
→ - Интеграция: Поскольку результаты этого теста предназначены для использования на практике, важно, чтобы у каждой модели были возможности интеграции API для легкой интеграции. →
Я приземлился на 7 моделях ИИ, изложенных ниже. Я дал каждому из них прозвище для удобства:
- →
- Amazon Analyze Expense API, or “AWS” →
- Azure AI Document Intelligence — фактурная предварительная модель, или «Azure» →
- Google Document AI — «Fact Parser» или «Google» →
- GPT-4o API — ввод текста с OCR третьей стороны, или «GPTt» →
- GPT-4o API - image input, or “GPTi” →
- Gemini 2.0 Pro Experimental или «Джемини» →
- Deepseek v3 — ввод текста, или «Deepseek-t» →
Invoice Dataset
Модели тестировались на наборе данных из 20 счетов-фактур различных размеров и годов выпуска (с 2006 по 2020 год).
|
2006 — 2010 | 6 | →
|
2011 — 2015 |
4 |
| → 2016 — 2020 |
10 |
2016 — 2020
Счетный год
Количество фактур
Количество фактур
2006 — 2010
6
2011 — 2015
2011 — 2015
4
4
2016 — 2020
2016 — 2020
10
Методология
Анализируя каждый счет, я определил список из 16 ключевых полей, которые являются общими для всех счетов-фактур и содержат самые важные данные:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Fields extracted by the models were mapped to a common naming convention to ensure consistency. LLM models (GPT, DeepSeek, and Gemini) were specifically asked to return the results using these common field names.
Выявление предметов фактуры
Для каждого счета-фактуры я оценивал, насколько хорошо модели извлекали поля ключевых элементов:
Description, Quantity, Unit Price, Total Price
Эффективность метрики
I’ve used a weighted efficiency metric (Eff, %) to assess the accuracy of extraction. This metric combines:
Строго необходимые поля: точные совпадения, такие как идентификатор счета-фактуры, даты и т.д.
Нестрогие основные поля: Частичные совпадения разрешены, если сходство (RLD, %) превышает порог.
Элементы счета-фактуры: оцениваются как правильные только в том случае, если все атрибуты элементов извлечены правильно.
Формулы
Общая эффективность (Eff, %): Eff, % = (COUNTIF(поля строгих эс. положительные) + COUNTIF(поля не строгих эс. положительные, если RLD > порог RLD) + COUNTIF(элементы, положительные)) / ((COUNT(все поля) + COUNT(все элементы)) * 100
Item-Level Efficiency (Eff-I, %): Eff-I, % = Positive IF (ALL(Quantity, Unit Price, Amount - positive) AND RLD(Description) > RLD threshold) * 100
Результаты признания счетов
Эффективность извлечения данных (за исключением элементов)


Эффективность извлечения данных (включая элементы)


NoteРезультаты Google исключены из этого, так как Google не смог правильно извлечь элементы.
Топ Инсайт
Azure не лучший с описаниями элементов.
В этом счете Azure не удалось обнаружить полные названия элементов, узнав только первые имена, в то время как другие модели успешно идентифицировали полные имена во всех 12 элементах.
Эта проблема значительно повлияла на эффективность Azure на этом счете, который был заметно ниже (33,3%) по сравнению с другими моделями.
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
Низкое разрешение счетов практически не влияет на качество обнаружения.
Низкое разрешение (как воспринимается человеческим глазом) счетов-фактур в целом не ухудшало качество обнаружения. Низкое разрешение в основном приводит к незначительным ошибкам распознавания, например, в одном из счетов-фактур Deepseek спутал комму с точкой, приводя к неправильному численному значению.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google не может обнаружить предметы.
Google объединяет все поля элементов в одну строку, что делает невозможным сравнение результатов с другими моделями.


Актуальные расчеты:


Все остальные сервисы имеют 100% правильное обнаружение с делением по атрибутам.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
Многолинейные описания элементов не повлияли на качество обнаружения.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Близнецы обладают наилучшим «вниманием к деталям».
LLM, такие как GPT, Gemini и DeepSeek, могут быть запрошены для извлечения большего количества данных, чем предварительно построенные модели распознавания счетов-фактур. Среди всех LLM, Gemini имеет лучшую точность, когда дело доходит до извлечения дополнительных данных из пунктов счетов-фактур.
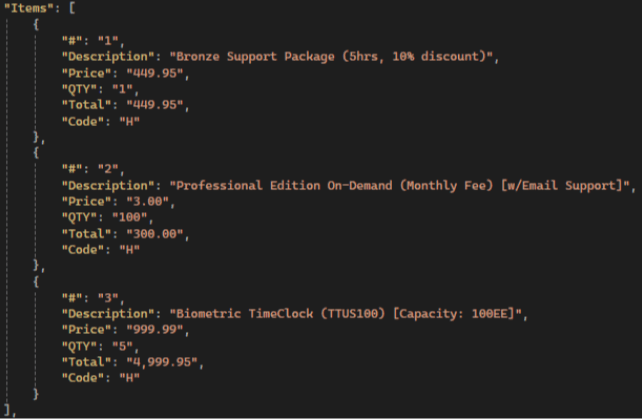
Примерная фактура:


Результаты Gemini:

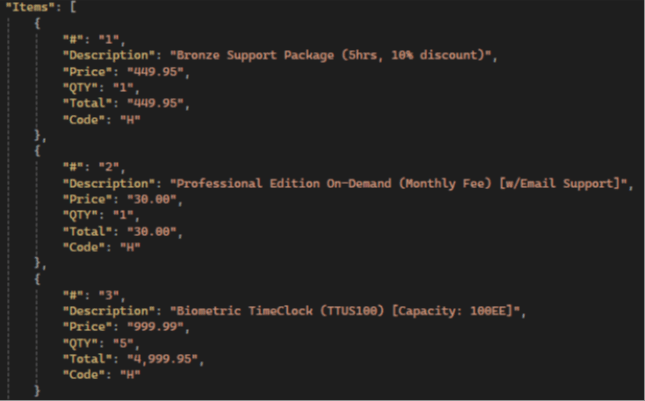
Результаты GPT:

Результаты DeepSeek:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Сравнение затрат
Я рассчитал стоимость обработки 1000 счетов по каждой модели, а также среднюю стоимость обработки одного счета:
Сервис
стоимость
стоимость
Стоимость на страницу (в среднем)
$10 / 1000 страниц (1)
$10 / 1000 страниц (1)
$0.01
Azure AI Document Intelligence
Сервис Azure Document Intelligence$10 / 1000 страниц
$10 / 1000 страниц
$0.01
Доллар 0.01
$10 / 1000 страниц
$10 / 1000 страниц
Доллар 0.01
«GPTT»: GPT-4o API, ввод текста с OCR третьей стороны
“GPTT”: GPT-4o API, text input with 3rd party OCR
«ГПТ»:$2.50 / 1M input tokens, $10.00 / 1M output tokens (2)
$2.50 / 1М входные токены, $10.00 / 1М выходные токены (2)
$0 021
$2.50 / 1М входные токены, $10.00 / 1М выходные токены
$2.50 / 1М входные токены, $10.00 / 1М выходные токены
$0.0087
$0 0087
$1,25, входные просьбы ≤ 128k токенов
$2.50, input prompts > 128k tokens
$5,00, просьбы о выходе ≤ 128k токенов
$10.00, просьбы о выходе > 128k токенов
$0 0045
$1,25, входные просьбы ≤ 128k токенов
$2.50, input prompts > 128k tokens
$5,00, просьбы о выходе ≤ 128k токенов
$10.00, просьбы о выходе > 128k токенов
$1,25, входные просьбы ≤ 128k токенов
$2,50, запросы на ввод > 128k токенов
$5,00, просьбы о выходе ≤ 128k токенов
$10.00, просьбы о выходе > 128k токенов
$0 0045
$0 0045
$10 / 1000 страниц + $0.27 / 1М токенов ввода, $1.10 / 1М токенов вывода
Deepseek v3 API
$10 / 1000 страниц + $0.27 / 1М токенов ввода, $1.10 / 1М токенов вывода
$10 / 1000 pages + $0.27 / 1M input tokens, $1.10 / 1M output tokens
$0 011
Notes:
(1) — $8 / 1000 страниц после одного миллиона в месяц
(2) — Additional $10 per 1000 pages for using a text recognition model
Ключевые находки
Most EfficientGemini и GPT-4o являются лидерами по эффективности и последовательности добычи по всем счетам.
⚠️ Worst performerGoogle AI является худшим из всех проверенных моделей, когда дело доходит до извлечения предметов, что делает общий балл эффективности низким.
Least Reliable: DeepSeek showed frequent mistakes in text and numerical values.
Какая модель лучше для чего?
✅ Gemini, AWS или Azure для высокоточного извлечения данных.
✅ GPT-4o (ввод текста с сторонним OCR) для экономически эффективного распознавания счетов-фактур и отличного баланса «стоимость-эффективность».
Избегайте Google AI, если вам нужно извлечь элементы с высокой точностью.








