




















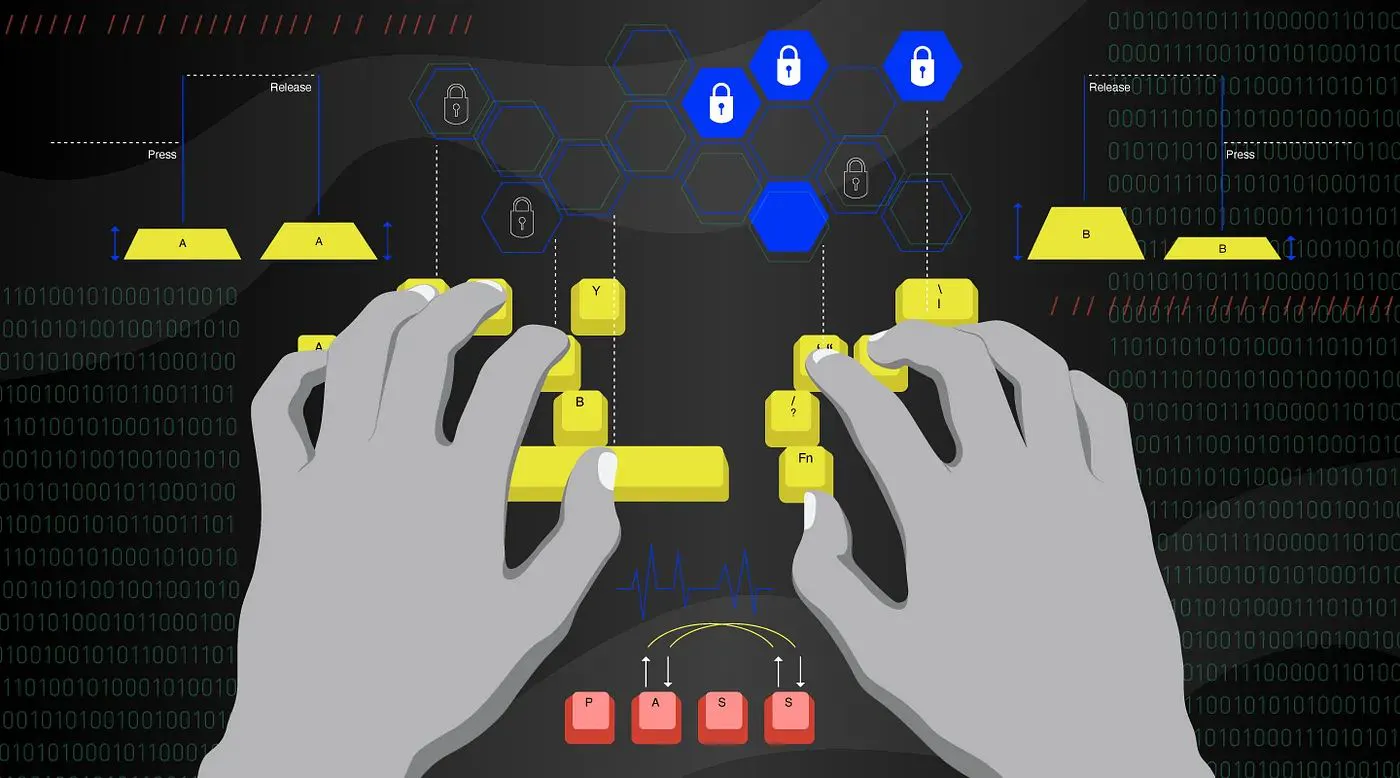


Modèles ML pour la reconnaissance des utilisateurs à l'aide de la dynamique de frappe
La dynamique de frappe utilisée dans les modèles d'apprentissage automatique de cet article pour la reconnaissance des utilisateurs est la biométrie comportementale. La dynamique de frappe utilise la manière distinctive dont chaque personne tape pour confirmer son identité. Ceci est accompli en analysant les 2 événements de frappe sur Key-Press et Key-Release - qui constituent une frappe sur les claviers d'ordinateur pour extraire les modèles de frappe.
Cet article examinera comment ces modèles peuvent être appliqués pour créer 3 modèles d'apprentissage automatique précis pour la reconnaissance des utilisateurs.


L'objectif de cet article sera divisé en deux parties, la construction et la formation de modèles d'apprentissage automatique (1. SVM 2. Random Forest 3. XGBoost ) et le déploiement du modèle dans une véritable API à point unique en direct capable de prédire l'utilisateur sur la base de 5 entrées. paramètres : le modèle ML et 4 temps de frappe.
1. Construire des modèles
Le problème
L'objectif de cette partie est de créer des modèles ML pour la reconnaissance des utilisateurs en fonction de leurs données de frappe . la dynamique de frappe est une biométrie comportementale qui utilise la manière unique dont une personne tape pour vérifier l'identité d'un individu.
Les modèles de frappe sont principalement extraits des claviers d’ordinateurs. les modèles utilisés dans la dynamique des frappes sont dérivés principalement des deux événements qui composent une frappe : la pression sur la touche et le relâchement de la touche.
L'événement Key-Press a lieu lors de l' enfoncement initial d'une touche et le Key-Release se produit lors du relâchement ultérieur de cette touche.
Dans cette étape, un ensemble de données d'informations sur les frappes des utilisateurs est fourni avec les informations suivantes :
-
keystroke.csv: dans cet ensemble de données, les données de frappe de 110 utilisateurs sont collectées. - Tous les utilisateurs sont invités à taper 8 fois une chaîne constante de 13 longueurs et les données de frappe (temps d'appui sur la touche et temps de relâchement de la touche pour chaque touche) sont collectées.
- L'ensemble de données contient 880 lignes et 27 colonnes.
- La première colonne indique l'ID utilisateur et le reste indique le temps d'appui et de relâchement pour le premier au 13ème caractère.
Vous devez procéder comme suit :
Habituellement, les données brutes ne sont pas suffisamment informatives et il est nécessaire d' extraire des fonctionnalités informatives des données brutes pour construire un bon modèle .
À cet égard, quatre caractéristiques :
Hold Time “HT”Press-Press time “PPT”Release-Release Time “RRT”Release-Press time “RPT”
sont présentés et les définitions de chacun d’eux sont décrites ci-dessus.
2. Pour chaque ligne de keystroke.csv, vous devez générer ces fonctionnalités pour deux touches consécutives.
3. Après avoir terminé l'étape précédente, vous devez calculer la moyenne et l'écart type pour chaque entité par ligne. En conséquence, vous devriez avoir 8 caractéristiques (4 moyennes et 4 écarts types) par ligne. → process_csv()
def calculate_mean_and_standard_deviation(feature_list): from math import sqrt # calculate the mean mean = sum(feature_list) / len(feature_list) # calculate the squared differences from the mean squared_diffs = [(x - mean) ** 2 for x in feature_list] # calculate the sum of the squared differences sum_squared_diffs = sum(squared_diffs) # calculate the variance variance = sum_squared_diffs / (len(feature_list) - 1) # calculate the standard deviation std_dev = sqrt(variance) return mean, std_dev
def process_csv(df_input_csv_data): data = { 'user': [], 'ht_mean': [], 'ht_std_dev': [], 'ppt_mean': [], 'ppt_std_dev': [], 'rrt_mean': [], 'rrt_std_dev': [], 'rpt_mean': [], 'rpt_std_dev': [], } # iterate over each row in the dataframe for i, row in df_input_csv_data.iterrows(): # iterate over each pair of consecutive presses and releases # print('user:', row['user']) # list of hold times ht_list = [] # list of press-press times ppt_list = [] # list of release-release times rrt_list = [] # list of release-press times rpt_list = [] # I use the IF to select only the X rows of the csv if i < 885: for j in range(12): # calculate the hold time: release[j]-press[j] ht = row[f"release-{j}"] - row[f"press-{j}"] # append hold time to list of hold times ht_list.append(ht) # calculate the press-press time: press[j+1]-press[j] if j < 11: ppt = row[f"press-{j + 1}"] - row[f"press-{j}"] ppt_list.append(ppt) # calculate the release-release time: release[j+1]-release[j] if j < 11: rrt = row[f"release-{j + 1}"] - row[f"release-{j}"] rrt_list.append(rrt) # calculate the release-press time: press[j+1] - release[j] if j < 10: rpt = row[f"press-{j + 1}"] - row[f"release-{j}"] rpt_list.append(rpt) # ht_list, ppt_list, rrt_list, rpt_list are a list of calculated values for each feature -> feature_list ht_mean, ht_std_dev = calculate_mean_and_standard_deviation(ht_list) ppt_mean, ppt_std_dev = calculate_mean_and_standard_deviation(ppt_list) rrt_mean, rrt_std_dev = calculate_mean_and_standard_deviation(rrt_list) rpt_mean, rpt_std_dev = calculate_mean_and_standard_deviation(rpt_list) # print(ht_mean, ht_std_dev) # print(ppt_mean, ppt_std_dev) # print(rrt_mean, rrt_std_dev) # print(rpt_mean, rpt_std_dev) data['user'].append(row['user']) data['ht_mean'].append(ht_mean) data['ht_std_dev'].append(ht_std_dev) data['ppt_mean'].append(ppt_mean) data['ppt_std_dev'].append(ppt_std_dev) data['rrt_mean'].append(rrt_mean) data['rrt_std_dev'].append(rrt_std_dev) data['rpt_mean'].append(rpt_mean) data['rpt_std_dev'].append(rpt_std_dev) else: break data_df = pd.DataFrame(data) return data_df
Tout le code que vous pouvez trouver sur mon GitHub dans le dépôt KeyStrokeDynamics :
Former les ML
Maintenant que nous avons analysé les données, nous pouvons commencer à créer les modèles en entraînant les ML.
Machine à vecteurs de support
def train_svm(training_data, features): import joblib from sklearn.svm import SVC """ SVM stands for Support Vector Machine, which is a type of machine learning algorithm used: for classification and regression analysis. SVM algorithm aims to find a hyperplane in an n-dimensional space that separates the data into two classes. The hyperplane is chosen in such a way that it maximizes the margin between the two classes, making the classification more robust and accurate. In addition, SVM can also handle non-linearly separable data by mapping the original features to a higher-dimensional space, where a linear hyperplane can be used for classification. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train an SVM model on the data svm_model = SVC() svm_model.fit(X, y) # Save the trained model to disk svm_model_name = 'models/svm_model.joblib' joblib.dump(svm_model, svm_model_name)
Lecture complémentaire :
Forêt aléatoire
def train_random_forest(training_data, features): """ Random Forest is a type of machine learning algorithm that belongs to the family of ensemble learning methods. It is used for classification, regression, and other tasks that involve predicting an output value based on a set of input features. The algorithm works by creating multiple decision trees, where each tree is built using a random subset of the input features and a random subset of the training data. Each tree is trained independently, and the final output is obtained by combining the outputs of all the trees in some way, such as taking the average (for regression) or majority vote (for classification). :param training_data: :param features: :return: ML Trained model """ import joblib from sklearn.ensemble import RandomForestClassifier # Split the data into features and labels X = training_data[features] y = training_data['user'] # Train a Random Forest model on the data rf_model = RandomForestClassifier() rf_model.fit(X, y) # Save the trained model to disk rf_model_name = 'models/rf_model.joblib' joblib.dump(rf_model, rf_model_name)
Lecture complémentaire :
Augmentation extrême du dégradé
def train_xgboost(training_data, features): import joblib import xgboost as xgb from sklearn.preprocessing import LabelEncoder """ XGBoost stands for Extreme Gradient Boosting, which is a type of gradient boosting algorithm used for classification and regression analysis. XGBoost is an ensemble learning method that combines multiple decision trees to create a more powerful model. Each tree is built using a gradient boosting algorithm, which iteratively improves the model by minimizing a loss function. XGBoost has several advantages over other boosting algorithms, including its speed, scalability, and ability to handle missing values. :param training_data: :param features: :return: ML Trained model """ # Split the data into features and labels X = training_data[features] label_encoder = LabelEncoder() y = label_encoder.fit_transform(training_data['user']) # Train an XGBoost model on the data xgb_model = xgb.XGBClassifier() xgb_model.fit(X, y) # Save the trained model to disk xgb_model_name = 'models/xgb_model.joblib' joblib.dump(xgb_model, xgb_model_name)
Lecture complémentaire :
Également publié ici.
Si vous aimez l’article et souhaitez me soutenir, assurez-vous de :
🔔 Suivez-moi Bogdan Tudorache See More
🔔 Connectez-vous avec moi : LinkedIn | Reddit








