



























































Jan 01, 1970
Una guía para principiantes para comprender las funciones de la ventana SQL - Parte 2 por@yonatansali
13,959 lecturas
Una guía para principiantes para comprender las funciones de la ventana SQL - Parte 2
Demasiado Largo; Para Leer
Exploremos conceptos de SQL más avanzados. Puede parecer un poco complicado a primera vista, pero proporcionaré ejemplos sencillos adecuados para principiantes para todos los casos posibles, por lo que será fácil entender lo que quiero decir.En el
Ahora que está familiarizado con los conceptos básicos, exploremos conceptos de SQL más avanzados. Puede parecer un poco complicado a primera vista, pero proporcionaré ejemplos sencillos adecuados para principiantes para todos los casos posibles, por lo que será fácil entender lo que quiero decir.
Descripción general del contenido
-
Cumulative Sum -
Ranking Window Functions -
Use cases -
Offset window functions -
Key Takeaways
Suma acumulada
Ya hemos considerado ejemplos en los que la expresión over() no tenía parámetros o tenía una partición por parámetro. Ahora, veremos el segundo parámetro posible para la expresión over() : ordenar por.
Solicitemos el ID del empleado, el nombre del empleado, el departamento, el salario y la suma de todos los salarios:
select employee_id, employee_name, department, salary, sum(salary) over() from salary
Ahora, agregaremos el orden por parámetro a la expresión over() :
select employee_id, employee_name, department, salary, sum(salary) over(order by employee_id desc) from salary
Supongo que debemos observar más de cerca lo que sucedió aquí:
En primer lugar, Employee_id ahora está ordenado en orden descendente.
En la columna resultante de la aplicación de la función de ventana, ahora hay una suma acumulada.
Creo que está familiarizado con la suma acumulativa. Su esencia es simple: la suma acumulada o total acumulado significa "cuánto hasta ahora". La definición de suma acumulativa es la suma de una secuencia dada que aumenta o se hace más grande con más sumas.
Esto es lo que tenemos en nuestro ejemplo: para el empleado con el valor de empleado_id más alto, el salario es 3700 y la suma acumulada también es 3700. El segundo empleado tiene un salario de 1500 y la suma acumulada es 5200. El tercer empleado , con un salario de 2900, tiene una suma acumulada de 8100, y así sucesivamente.
El parámetro orden por en la expresión over() especifica el orden. En el caso de agregar funciones de ventana, determina el orden del total acumulado.
En la expresión over() , se pueden especificar los atributos de partición y orden por.
select employee_id, employee_name, department, salary, sum(salary) over(partition by department order by employee_id desc) from salary
En este caso, el total acumulado se calculará por tramos.
¡NÓTESE BIEN! Si ambos atributos se especifican en la expresión over() , la partición by siempre viene primero, seguida del orden by . Por ejemplo: over(partición por orden de departamento por empleado_id) .
Después de haber analizado la suma acumulativa, debemos decir que quizás sea el único tipo de total acumulativo que se utiliza con frecuencia. Por el contrario, rara vez se utilizan el promedio acumulativo y el recuento acumulativo.
Sin embargo, daremos un ejemplo del cálculo del promedio acumulado: nos dice el promedio de una serie de valores hasta cierto punto:
select employee_id, employee_name, department, salary, avg(salary) over(order by employee_id desc) from salary
Funciones de la ventana de clasificación
Usamos las funciones de la ventana de clasificación para determinar la posición de un valor dentro de un conjunto de valores. La expresión ORDER BY dentro de la cláusula OVER dicta la base para la clasificación, y a cada valor se le asigna una clasificación dentro de su partición designada. Cuando las filas comparten valores idénticos para los criterios de clasificación, se les asigna la misma clasificación.
Para ver cómo funcionan las funciones de la ventana de clasificación, solicitemos las siguientes columnas de la tabla de salarios: ID de empleado, nombre de empleado, departamento y salario:
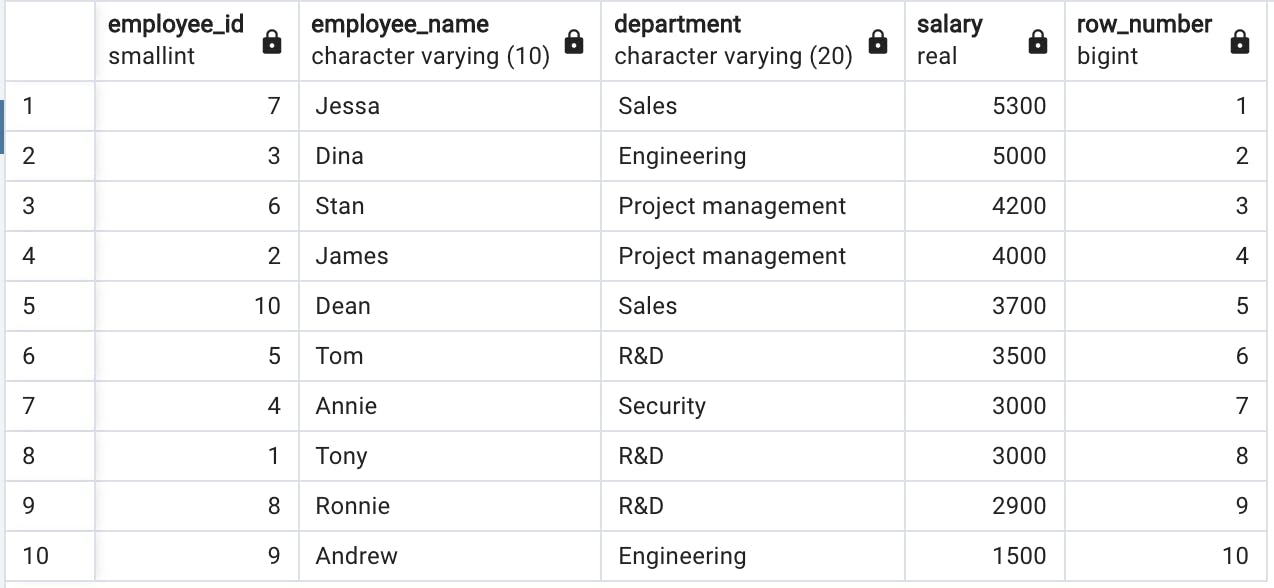
select employee_id, employee_name, department, salary from salary Ahora, agregamos una columna más con la función de ventana número_fila() sobre() :
select employee_id, employee_name, department, salary, row_number() over() from salary
La función de ventana número_fila() over() ha asignado números a las filas sin cambiar su orden. Hasta ahora esto no nos aporta mucho valor, ¿verdad?
Pero ¿qué pasa si queremos numerar las filas en orden descendente de salario? Para lograr esto, necesitamos especificar el orden de clasificación; en otras palabras, pasar el orden por parámetro a la expresión over().
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary
Agregaremos las funciones de clasificación restantes a la consulta para comparar:
select employee_id, employee_name, department, salary, row_number() over(order by salary desc), rank() over(order by salary desc), dense_rank() over(order by salary desc), percent_rank() over(order by salary desc), ntile(5) over(order by salary desc) from salary
Repasemos cada función de la ventana de clasificación:
La función de ventana número_fila() over(ordenar por descripción de salario) clasifica las filas en orden descendente de salario y asigna números de fila. Tenga en cuenta que Annie y Tony tienen el mismo salario, pero se les asignan números diferentes.
La función de ventana rango() sobre(ordenar por salario desc ) asigna rangos en orden descendente de salario. Asigna el mismo rango para valores idénticos, pero el siguiente valor obtiene un nuevo número de fila.
La función de ventana denso_rank() over(orden por salario desc) asigna rangos en orden descendente de salario. Asigna el mismo rango para valores idénticos.
La función de ventana percent_rank() over(orden por salario desc) es la clasificación relativa (porcentaje) de la fila actual, calculada mediante la fórmula: (clasificación - 1) / (número total de filas en la partición - 1).
La función de ventana ntile(5) over(order by salario desc) divide el número de filas en 5 partes iguales y asigna un número a cada parte. El número de partes se especifica dentro de la función ntile(5) .
¡NÓTESE BIEN! A diferencia de las funciones agregadas, por ejemplo, suma (salario), las funciones de clasificación, por ejemplo, número_fila(), no incluyen una columna dentro. Sin embargo, en la función ntile(5), se especifica el número de partes.
Casos de uso
Es hora de explorar tareas prácticas utilizando funciones de ventana de clasificación. Mostraremos el ID del empleado, el nombre del empleado, el departamento y el salario, y asignaremos números de fila en orden descendente de salario.
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary
A veces, es posible que necesites numerar las filas en orden descendente de salario dentro de los departamentos (secciones). Esto se puede hacer agregando el atributo partición por a la expresión over():
select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) from salary
Hagamos la tarea más desafiante. Necesitamos retener solo un empleado por departamento con el salario más alto. Esto se puede lograr usando una subconsulta:
select * from ( select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) as rn from salary ) as t2 where rn = 1
Y un ejemplo más, si necesitamos mostrar tres empleados en cada ciudad con el salario más alto, haremos lo siguiente:
select * from ( select employee_id, employee_name, city, salary, row_number() over(partition by city order by salary desc) as rn from salary ) as t2 where rn <= 3
Este tipo de tareas son muy comunes, especialmente cuando necesitas mostrar un número específico de filas dentro de secciones (grupos) en orden ascendente o descendente de algún atributo. En la práctica, uso constantemente la función de ventana row_number() over() y, por supuesto, densa_rank() over() también.
Funciones de ventana de compensación
Estas funciones le permiten devolver datos de otras filas en función de su distancia de la fila actual. Para hacerlo más visual, repasemos las funciones first_value(), last_value() y nth_value().
select t1.*, first_value(salary)over(partition by department), last_value(salary)over(partition by department), nth_value(salary,2)over(partition by department) from salary as t1 order by department ¡NÓTESE BIEN! En las tres funciones de ventana, es
select t1.*, first_value(salary)over(partition by department order by salary decs), last_value(salary)over(partition by department order by salary decs), nth_value(salary,2)over(partition by department order by salary decs) from salary as t1 order by departmentLas funciones primer_valor(salario) sobre(partición por departamento) y último_valor(salario) sobre(partición por departamento) muestran el primer y último valor salarial dentro de la sección (departamento).
A su vez, la función nth_value(salario, 2) over(partición por departamento) muestra el segundo valor salarial dentro de la sección (departamento). Tenga en cuenta que en nth_value() , se especifica un argumento adicional: el número de fila dentro de la sección. En nuestro caso, el número de fila es 2, por lo que la función muestra el segundo valor salarial.
Aparte de lo anterior, también existen funciones lag() y lead() . La función lag() se utiliza para obtener el valor de la fila que precede a la fila actual. La función lead() se utiliza para obtener el valor de una fila que sucede a la fila actual.
select t1.*, lag(salary)over(order by salary), lead(salary)over(order by salary) from salary as t1
Como puede ver, la función de retraso (salario) sobre (orden por salario) desplaza los salarios hacia abajo una fila, y la función adelantar (salario) sobre (orden por salario) desplaza los salarios hacia arriba una fila. Aunque estas funciones son bastante similares, me resulta más conveniente usar lag() .
¡NÓTESE BIEN! Para estas funciones, es obligatorio especificar el orden por parámetro en la expresión over(). También puede especificar la partición mediante partición por, pero no es obligatorio.
select t1.*, lag(salary)over(partition by department order by salary) from salary as t1 order by department
Aquí, lag() realiza la misma función que antes, pero ahora específicamente dentro de las secciones (departamentos).
Conclusiones clave
Y finalmente, una breve descripción general de lo que hemos cubierto hoy:
La suma acumulada representa el total acumulado de una secuencia, que se acumula con cada suma posterior.
Las funciones de ventana de clasificación se utilizan para determinar la posición de un valor dentro de un conjunto de valores, y el orden por expresión especifica la base para la clasificación.
Las funciones de ventana de compensación incluyen first_value() , last_value() y nth_value() , lo que permite la recuperación de datos de otras filas en función de su distancia desde la fila actual. No te olvides de las funciones lag() y lead() . La función lag() puede ser útil para obtener el valor de la fila que precede a la fila actual, mientras que la función lead() se usa para obtener el valor de una fila que sucede a la fila actual.
Gracias por acompañarme. Espero que este artículo le ayude a comprender mejor las capacidades de las funciones de ventana en SQL y le haga tener más confianza y rapidez en las tareas rutinarias.
L O A D I N G
. . . comments & more!
. . . comments & more!



