






















在里面
现在,您已经熟悉了基础知识,让我们探索更高级的 SQL 概念。乍一看可能有点复杂,但我将针对所有可能的情况提供适合初学者的简单示例,因此很容易明白我的意思。
内容概述
Cumulative Sum-
Ranking Window Functions -
Use cases -
Offset window functions -
Key Takeaways
累计金额
我们已经考虑过over()表达式没有参数或按参数分区的示例。现在,我们将看看over()表达式的第二个可能的参数 — order by。
让我们请求员工 ID、员工姓名、部门、工资以及所有工资的总和:
select employee_id, employee_name, department, salary, sum(salary) over() from salary


现在,我们将order by参数添加到over()表达式中:
select employee_id, employee_name, department, salary, sum(salary) over(order by employee_id desc) from salary 

我想我们需要仔细看看这里发生的事情:
首先, employee_id现在按降序排序。
在应用窗口函数产生的列中,现在有一个累积和。
我相信你对累积和很熟悉。它的本质很简单——累积总和或运行总计意味着“到目前为止有多少”。累积和的定义是给定序列的总和,该序列随着添加次数的增加而增加或变大。
我们的示例如下:对于具有最高employee_id值的员工,工资为3700,累计金额也是3700。第二个员工的工资为1500,累计金额为5200。第三个员工,工资2900,累计金额8100,以此类推。
over()表达式中的 order by 参数指定顺序。在聚合窗口函数的情况下,它确定累积总数的顺序。
在over()表达式中,可以指定partition by 和order by 属性。
select employee_id, employee_name, department, salary, sum(salary) over(partition by department order by employee_id desc) from salary


在这种情况下,累计总数将按分段计算。
注意!如果在over()表达式中指定了两个属性,则分区 by 始终排在第一位,然后是order by 。例如: over(按部门顺序按员工 ID 分区) 。
在我们讨论完累积和之后,我们需要说,它可能是唯一经常使用的累积总计类型。相反,累积平均和累积计数则很少使用。
尽管如此,我们还是会给出一个累积平均值计算的例子——它告诉我们直到某个点的一系列值的平均值:
select employee_id, employee_name, department, salary, avg(salary) over(order by employee_id desc) from salary


排名窗口函数
我们使用排名窗口函数来确定值在一组值中的位置。 OVER子句中的ORDER BY表达式规定了排名的基础,每个值在其指定分区内分配了一个排名。当行共享相同的排名标准值时,它们将被分配相同的排名。
要了解排名窗口函数的工作原理,我们请求工资表中的以下列:员工 ID、员工姓名、部门和工资:
select employee_id, employee_name, department, salary from salary 

现在,我们使用窗口函数row_number() over()添加一列:
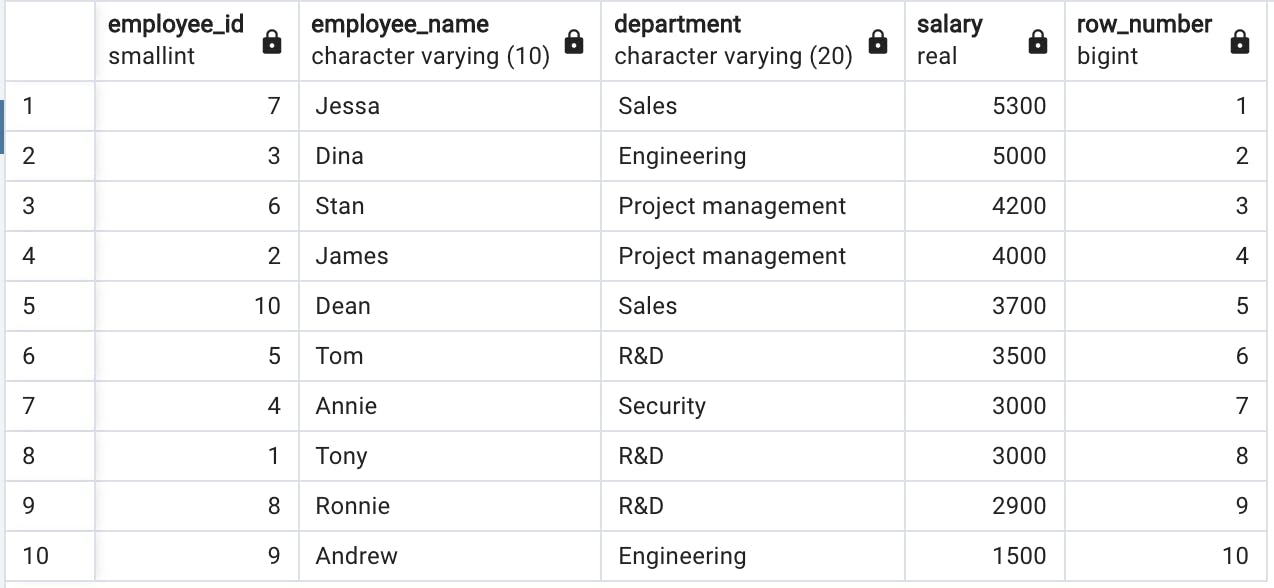
select employee_id, employee_name, department, salary, row_number() over() from salary


窗口函数row_number() over()已为行分配了编号,但不更改其顺序。到目前为止,这并没有给我们带来太大的价值,不是吗?
但是如果我们想按工资降序对行进行编号怎么办?为此,我们需要指定排序顺序,换句话说,将顺序参数传递给 over() 表达式。
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary

我们将把剩余的排名函数添加到查询中进行比较:
select employee_id, employee_name, department, salary, row_number() over(order by salary desc), rank() over(order by salary desc), dense_rank() over(order by salary desc), percent_rank() over(order by salary desc), ntile(5) over(order by salary desc) from salary
让我们看一下每个排名窗口函数:
窗口函数row_number() over(order by salary desc) 按工资降序排列行并分配行号。请注意,安妮和托尼的工资相同,但分配的数字不同。
窗口函数rank() over(order by salary desc )按工资降序分配排名。它为相同的值分配相同的排名,但下一个值会获得新的行号。
窗口函数dense_rank() over(order by salary desc) 按工资降序分配排名。它为相同的值分配相同的排名。
窗口函数percent_rank() over(order by salary desc)是当前行的相对(百分比)排名,计算公式为:(rank - 1) / (分区中的总行数 - 1)。
窗口函数ntile(5) over(order by salary desc)将行数分成 5 个相等的部分,并为每个部分分配一个数字。零件的数量在ntile(5)函数内指定。
注意!与聚合函数(例如 sum(salary))不同,排名函数(例如 row_number())内部不包含列。然而,在 ntile(5) 函数中,指定了部分的数量。
用例
是时候使用排名窗口函数来探索实际任务了。我们将显示员工 ID、员工姓名、部门和工资,并按工资降序分配行号。
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary


有时,您可能需要按部门(部分)内工资的降序对行进行编号。这可以通过将partition by属性添加到over()表达式来完成:
select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) from salary

让我们让任务更具挑战性。我们每个部门只需要保留一名薪水最高的员工。这可以使用子查询来实现:
select * from ( select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) as rn from salary ) as t2 where rn = 1


再举个例子,如果我们需要显示每个城市中薪资最高的三名员工,我们将执行以下操作:
select * from ( select employee_id, employee_name, city, salary, row_number() over(partition by city order by salary desc) as rn from salary ) as t2 where rn <= 3


此类任务非常常见,尤其是当您需要按某些属性的升序或降序显示部分(组)内的特定行数时。在实践中,我一贯使用窗口函数row_number() over() ,当然也使用 dendense_rank() over() 。
偏移窗函数
这些函数允许您根据其他行与当前行的距离返回数据。为了使其更直观,让我们看一下first_value()、last_value() 和nth_value() 函数。
select t1.*, first_value(salary)over(partition by department), last_value(salary)over(partition by department), nth_value(salary,2)over(partition by department) from salary as t1 order by department 

注意!在所有三个窗口函数中,
select t1.*, first_value(salary)over(partition by department order by salary decs), last_value(salary)over(partition by department order by salary decs), nth_value(salary,2)over(partition by department order by salary decs) from salary as t1 order by department函数first_value(salary) over(按部门分区)和last_value(salary) over(按部门分区)显示该部分(部门)内的第一个和最后一个工资值。
反过来,函数nth_value(salary, 2) over(partition by Department)显示该部分(部门)内的第二个工资值。请注意,在nth_value()中,指定了一个附加参数 - 该部分内的行号。在我们的示例中,行号为 2,因此该函数显示第二个工资值。
除了上面的函数之外,还有lag()和lead()函数。 lag()函数用于从当前行之前的行获取值。 Lead() 函数用于从当前行之后的行获取值。
select t1.*, lag(salary)over(order by salary), lead(salary)over(order by salary) from salary as t1
正如您所看到的,函数lag (salary) over (order by salary)将工资向下移动一行,而函数Lead(salary) over(order by salary)将工资向上移动一行。虽然这些函数非常相似,但我发现使用lag()更方便。


注意!对于这些函数,必须在 over() 表达式中通过参数指定顺序。您还可以使用partition by指定分区,但这不是强制性的。
select t1.*, lag(salary)over(partition by department order by salary) from salary as t1 order by department
在这里, lag()执行与以前相同的功能,但现在专门在部分(部门)内。


要点
最后,快速概述一下我们今天所讨论的内容:
累积和表示序列的运行总计,并随着后续的每次添加而累加。
排名窗口函数用于确定值在一组值中的位置,其中order by表达式指定排名的基础。
偏移窗口函数包括first_value() 、 last_value()和nth_value() ,允许根据其他行与当前行的距离检索数据。不要忘记lag()和Lead()函数。 lag()函数可以方便地从当前行之前的行获取值,而Lead()函数用于从当前行之后的行获取值。
感谢您加入我。我希望这篇文章可以帮助您更好地了解 SQL 中窗口函数的功能,并使您在日常任务中更加自信和快速。








