






















в
Итак, теперь, когда вы знакомы с основами, давайте рассмотрим более сложные концепции SQL. На первый взгляд это может показаться немного сложным, но я приведу простые примеры, подходящие для новичков, для всех возможных случаев, чтобы вам было легко уловить суть.
Обзор контента
-
Cumulative Sum -
Ranking Window Functions -
Use cases -
Offset window functions -
Key Takeaways
Совокупная сумма
Мы уже рассматривали примеры, когда выражение over() либо не имело параметров, либо имело разделение по параметрам. Теперь мы рассмотрим второй возможный параметр выражения over() — порядок по.
Давайте запросим идентификатор сотрудника, имя сотрудника, отдел, зарплату и сумму всех зарплат:
select employee_id, employee_name, department, salary, sum(salary) over() from salary


Теперь мы добавим порядок по параметру в выражение over() :
select employee_id, employee_name, department, salary, sum(salary) over(order by employee_id desc) from salary 

Думаю, нам нужно повнимательнее посмотреть, что здесь произошло:
Прежде всего, идентификатор сотрудника теперь отсортирован по убыванию.
В столбце, полученном в результате применения оконной функции, теперь отображается накопительная сумма.
Я думаю, вы знакомы с накопительной суммой. Суть его проста — накопительная сумма или промежуточный итог означает «сколько пока». Определение накопительной суммы — это сумма данной последовательности, которая увеличивается или становится больше при большем количестве сложений.
Вот что мы имеем в нашем примере: для сотрудника с наибольшим значением сотрудника_id зарплата равна 3700, а накопительная сумма также равна 3700. У второго сотрудника зарплата равна 1500, а совокупная сумма равна 5200. Третий сотрудник , при зарплате 2900, имеет совокупную сумму 8100 и так далее.
Параметр order by в выражении over() определяет порядок. В случае агрегирующих оконных функций он определяет порядок нарастающего итога.
В выражении over() можно указать атрибуты разделения и порядка.
select employee_id, employee_name, department, salary, sum(salary) over(partition by department order by employee_id desc) from salary


В этом случае нарастающий итог будет рассчитываться по разделам.
Гульника! Если в выражении over() указаны оба атрибута, сначала всегда идет секция by, а затем порядок по . Например: over(разделение по отделам, заказ по сотруднику_id) .
После того, как мы обсудили нарастающую сумму, нужно сказать, что, возможно, это единственный тип нарастающей суммы, который часто используется. Нарастающее среднее значение и совокупный подсчет, напротив, используются редко.
Тем не менее, мы приведем пример расчета кумулятивного среднего — он сообщает нам среднее значение ряда значений до определенного момента:
select employee_id, employee_name, department, salary, avg(salary) over(order by employee_id desc) from salary


Функции окна ранжирования
Мы используем функции окна ранжирования, чтобы определить положение значения в наборе значений. Выражение ORDER BY в предложении OVER определяет основу для ранжирования, при этом каждому значению присваивается ранг в пределах назначенного ему раздела. Если строки имеют одинаковые значения критериев ранжирования, им присваивается одинаковый ранг.
Чтобы увидеть, как работают функции окна ранжирования, запросим из таблицы зарплат следующие столбцы: идентификатор сотрудника, имя сотрудника, отдел и зарплату:
select employee_id, employee_name, department, salary from salary 

Теперь мы добавляем еще один столбец с помощью оконной функции row_number() over() :
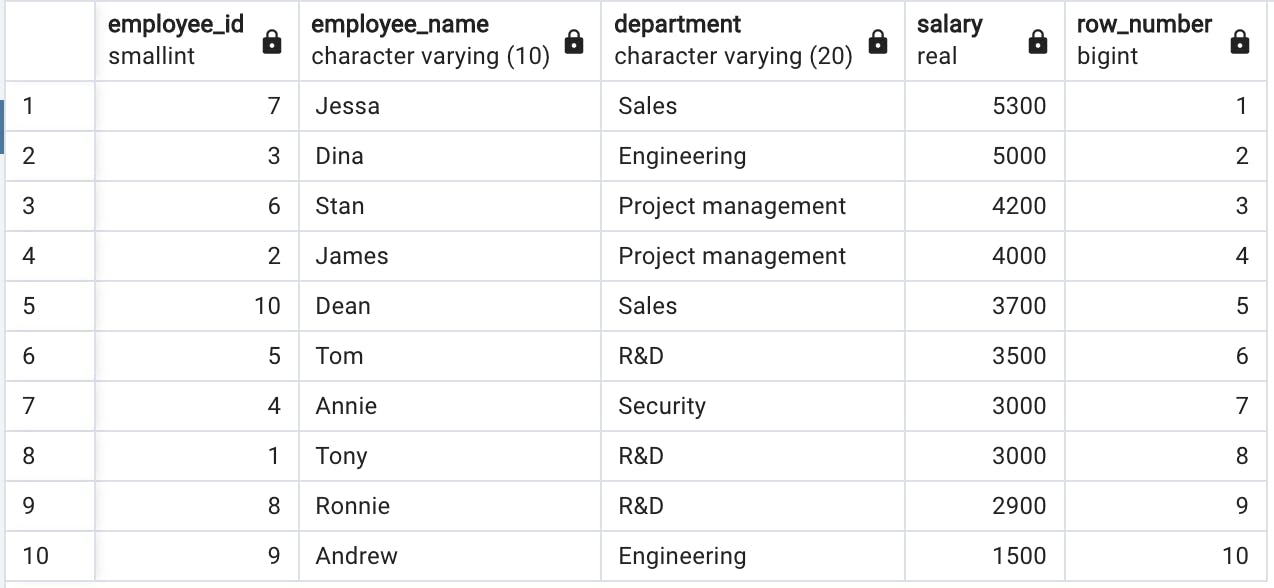
select employee_id, employee_name, department, salary, row_number() over() from salary


Оконная функция row_number() over() присвоила строкам номера, не меняя их порядка. Пока это не приносит нам особой пользы, не так ли?
Но что, если мы хотим пронумеровать строки в порядке убывания зарплаты? Для этого нам нужно указать порядок сортировки, другими словами, передать порядок по параметру в выражение over().
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary

Добавим в запрос остальные функции ранжирования для сравнения:
select employee_id, employee_name, department, salary, row_number() over(order by salary desc), rank() over(order by salary desc), dense_rank() over(order by salary desc), percent_rank() over(order by salary desc), ntile(5) over(order by salary desc) from salary
Давайте рассмотрим каждую функцию окна ранжирования:
Оконная функция row_number() over(порядок по убыванию зарплаты) ранжирует строки в порядке убывания зарплаты и присваивает номера строк. Обратите внимание, что у Энни и Тони одинаковая зарплата, но им присвоены разные номера.
Оконная функция Rank() over(порядок по убыванию зарплаты ) присваивает ранги в порядке убывания зарплаты. Он присваивает одинаковый ранг идентичным значениям, но следующее значение получает новый номер строки.
Оконная функция Densent_rank() over(порядок по убыванию зарплаты) присваивает ранги в порядке убывания зарплаты. Он присваивает одинаковый ранг одинаковым значениям.
Оконная функция процент_ранг() over(order по убыванию зарплаты) — это относительный (процентный) ранг текущей строки, рассчитываемый по формуле: (ранг — 1) / (общее количество строк в разделе — 1).
Оконная функция ntile(5) over(порядок по убыванию зарплаты) делит количество строк на 5 равных частей и присваивает каждой части номер. Количество частей указывается внутри функции ntile(5) .
Гульника! В отличие от агрегатных функций, например sum(salary), функции ранжирования, например row_number(), не принимают столбец внутрь. Однако в функции ntile(5) указывается количество частей.
Случаи использования
Пришло время изучить практические задачи с использованием оконных функций ранжирования. Мы отобразим идентификатор сотрудника, имя сотрудника, отдел и зарплату, а также назначим номера строк в порядке убывания зарплаты.
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary


Иногда может потребоваться нумерация строк в порядке убывания заработной платы внутри отделов (отделов). Это можно сделать, добавив раздел по атрибуту в выражение over():
select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) from salary

Давайте усложним задачу. Нам нужно сохранить только одного сотрудника в каждом отделе с самой высокой зарплатой. Этого можно добиться с помощью подзапроса:
select * from ( select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) as rn from salary ) as t2 where rn = 1


И еще пример, если нам нужно отобразить по три сотрудника в каждом городе с самой высокой зарплатой, мы сделаем следующее:
select * from ( select employee_id, employee_name, city, salary, row_number() over(partition by city order by salary desc) as rn from salary ) as t2 where rn <= 3


Такого рода задачи очень распространены, особенно когда нужно отобразить определенное количество строк внутри разделов (групп) в порядке возрастания или убывания какого-либо атрибута. На практике я постоянно использую оконную функцию row_number() over() и, конечно же, Densent_rank() over() .
Функции окна смещения
Эти функции позволяют вам возвращать данные из других строк в зависимости от их расстояния от текущей строки. Чтобы сделать это более наглядным, давайте рассмотрим функции first_value(), Last_value() и nth_value().
select t1.*, first_value(salary)over(partition by department), last_value(salary)over(partition by department), nth_value(salary,2)over(partition by department) from salary as t1 order by department 

Гульника! Во всех трех оконных функциях это
select t1.*, first_value(salary)over(partition by department order by salary decs), last_value(salary)over(partition by department order by salary decs), nth_value(salary,2)over(partition by department order by salary decs) from salary as t1 order by departmentФункции first_value(salary) over(раздел по отделам) и Last_value(salary) over(раздел по отделам) отображают первое и последнее значения зарплаты в пределах раздела (отдела).
В свою очередь, функция nth_value(salary, 2) over(partition by Department) показывает второе значение зарплаты внутри раздела (отдела). Обратите внимание, что в nth_value() указывается дополнительный аргумент — номер строки внутри раздела. В нашем случае номер строки равен 2, поэтому функция отображает второе значение зарплаты.
Помимо вышеперечисленного, существуют также функции lag() и lead() . Функция lag() используется для получения значения из строки, предшествующей текущей строке. Функция lead() используется для получения значения из строки, следующей за текущей.
select t1.*, lag(salary)over(order by salary), lead(salary)over(order by salary) from salary as t1
Как видите, функция lag(salary) over(order by зарплата) сдвигает зарплаты на одну строку вниз, а функция lead(salary) over(order by зарплата) сдвигает зарплаты на одну строку вверх. Хотя эти функции очень похожи, я считаю более удобным использовать lag() .


Гульника! Для этих функций обязательно указывать порядок по параметру в выражении over(). Вы также можете указать секционирование с помощью раздела, но это не обязательно.
select t1.*, lag(salary)over(partition by department order by salary) from salary as t1 order by department
Здесь lag() выполняет ту же функцию, что и раньше, но теперь конкретно внутри разделов (отделов).


Ключевые выводы
И, наконец, краткий обзор того, что мы рассмотрели сегодня:
Накопленная сумма представляет собой промежуточную сумму последовательности, накапливающуюся при каждом последующем добавлении.
Оконные функции ранжирования используются для определения положения значения в наборе значений, при этом порядок выражения определяет основу для ранжирования.
К функциям окна смещения относятся first_value() , Last_value() и nth_value() , позволяющие извлекать данные из других строк на основе их расстояния от текущей строки. Не забывайте о функциях lag() и lead() . Функция lag() может быть полезна для получения значения из строки, предшествующей текущей строке, а функция lead() используется для получения значения из строки, следующей за текущей.
Спасибо, что присоединились ко мне. Надеюсь, эта статья поможет вам лучше понять возможности оконных функций в SQL и сделает вас более уверенным и быстрым в выполнении рутинных задач.








