






















の中に
基本については理解できたので、より高度な SQL の概念を見てみましょう。一見すると少し複雑に聞こえるかもしれませんが、考えられるすべてのケースについて初心者向けの簡単な例を示しますので、簡単に理解できるでしょう。
コンテンツの概要
Cumulative Sum-
Ranking Window Functions -
Use cases -
Offset window functions -
Key Takeaways
累積合計
over()式にパラメータがないか、パラメータによるパーティションが存在する例をすでに検討しました。ここで、 over()式の 2 番目のパラメータであるorder by を見てみましょう。
従業員 ID、従業員名、部門、給与、およびすべての給与の合計を要求してみましょう。
select employee_id, employee_name, department, salary, sum(salary) over() from salary


次に、 order byパラメーターをover()式に追加します。
select employee_id, employee_name, department, salary, sum(salary) over(order by employee_id desc) from salary 

ここで何が起こったのかを詳しく調べる必要があると思います。
まず、 employee_id が降順にソートされるようになりました。
ウィンドウ関数を適用した結果の列には、累積合計が表示されます。
累積和についてはご存知かと思います。その本質は単純です。累積合計または累計は「これまでの金額」を意味します。累積和の定義は、追加が増えるにつれて増加または大きくなる特定のシーケンスの合計です。
この例では次のようになります。employee_id値が最も高い従業員の給与は 3700、累積合計も 3700 です。2 番目の従業員の給与は 1500、累積合計は 5200 です。3 番目の従業員、給与が 2900、累計が 8100 など。
over()式の order by パラメーターは順序を指定します。ウィンドウ関数を集計する場合、累積合計の順序が決まります。
over()式では、partition by 属性と order by 属性の両方を指定できます。
select employee_id, employee_name, department, salary, sum(salary) over(partition by department order by employee_id desc) from salary


この場合、累計は部門ごとに計算されます。
注意!両方の属性がover()式で指定されている場合、パーティション by が常に最初に来て、その後に による順序が続きます。例: over(partition by 部門 order byemployee_id) 。
累積合計について説明した後、おそらくこれが頻繁に使用される唯一のタイプの累積合計であると言う必要があります。逆に、累積平均や累積数はほとんど使用されません。
それにもかかわらず、累積平均計算の例を示します。これは、特定の点までの一連の値の平均を示します。
select employee_id, employee_name, department, salary, avg(salary) over(order by employee_id desc) from salary


ランキングウィンドウの機能
ランキング ウィンドウ関数を使用して、一連の値内の値の位置を決定します。 OVER句内のORDER BY式はランク付けの基準を指定し、各値に指定されたパーティション内のランクが割り当てられます。行がランク付け基準に対して同じ値を共有する場合、それらの行には同じランクが割り当てられます。
ランキング ウィンドウの機能がどのように機能するかを確認するには、給与テーブルから従業員 ID、従業員名、部門、給与の列をリクエストしてみましょう。
select employee_id, employee_name, department, salary from salary 

ここで、ウィンドウ関数row_number() over()を使用して列を 1 つ追加します。
select employee_id, employee_name, department, salary, row_number() over() from salary


ウィンドウ関数row_number() over() は、順序を変更せずに行に番号を割り当てました。今のところ、これは私たちにとってあまり価値がありませんね。
しかし、行に給与の降順で番号を付けたい場合はどうすればよいでしょうか?これを実現するには、ソート順序を指定する必要があります。つまり、パラメータによって順序を over() 式に渡す必要があります。
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary

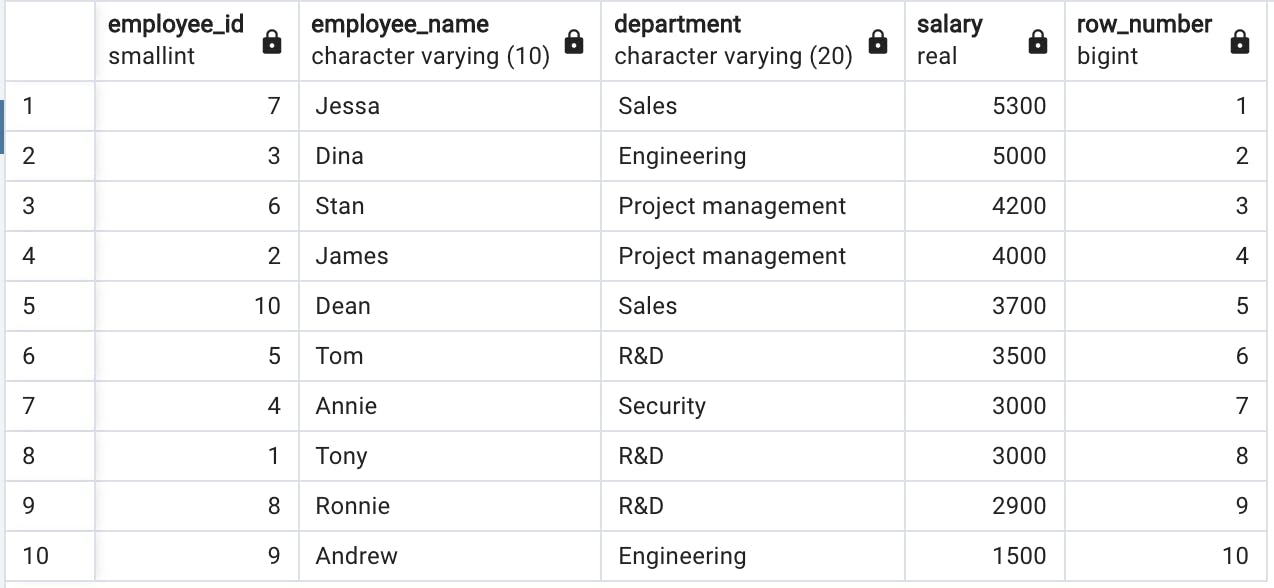
比較のために残りのランキング関数をクエリに追加します。
select employee_id, employee_name, department, salary, row_number() over(order by salary desc), rank() over(order by salary desc), dense_rank() over(order by salary desc), percent_rank() over(order by salary desc), ntile(5) over(order by salary desc) from salary
各ランキング ウィンドウ関数を見てみましょう。
ウィンドウ関数row_number() over(order by給与 desc) は、給与の降順に行をランク付けし、行番号を割り当てます。アニーとトニーの給与は同じですが、異なる番号が割り当てられていることに注意してください。
ウィンドウ関数Rank() over(order by給与 desc ) は、給与の降順にランクを割り当てます。同一の値には同じランクが割り当てられますが、次の値には新しい行番号が割り当てられます。
ウィンドウ関数dense_rank() over(order by給与desc)は、給与の降順にランクを割り当てます。同一の値には同じランクが割り当てられます。
ウィンドウ関数percent_rank() over(order by給与記述)は、現在の行の相対(パーセンテージ)ランクであり、次の式で計算されます: (ランク - 1) / (パーティション内の行の総数 - 1)。
ウィンドウ関数ntile(5) over(order by給与 desc) は、行数を 5 等分し、各部分に番号を割り当てます。パーツの数はntile(5)関数内で指定します。
注意! sum(salary) などの集計関数とは異なり、row_number() などのランキング関数は内部に列を取りません。ただし、ntile(5)関数ではパーツ数を指定します。
使用例
ランキング ウィンドウ関数を使用して実際のタスクを検討してみましょう。社員ID、社員名、部署、給与を表示し、給与の降順に行番号を割り当てます。
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary


場合によっては、部門 (セクション) 内で給与の降順に行に番号を付ける必要がある場合があります。これは、属性によるパーティションを over() 式に追加することで実行できます。
select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) from salary

タスクをもっと難しくしてみましょう。最高給与の従業員を部門ごとに 1 人だけ維持する必要があります。これはサブクエリを使用して実現できます。
select * from ( select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) as rn from salary ) as t2 where rn = 1


もう 1 つの例として、各都市で最も給与の高い 3 人の従業員を表示する必要がある場合は、次の操作を行います。
select * from ( select employee_id, employee_name, city, salary, row_number() over(partition by city order by salary desc) as rn from salary ) as t2 where rn <= 3


この種のタスクは、特にセクション (グループ) 内の特定の数の行を属性の昇順または降順で表示する必要がある場合に非常に一般的です。実際には、私は一貫してウィンドウ関数row_number() over()を使用し、もちろんDensse_rank() over()も使用します。
オフセットウィンドウ関数
これらの関数を使用すると、現在の行からの距離に基づいて他の行からデータを返すことができます。より視覚的にするために、first_value()、last_value()、および nth_value() 関数を見てみましょう。
select t1.*, first_value(salary)over(partition by department), last_value(salary)over(partition by department), nth_value(salary,2)over(partition by department) from salary as t1 order by department 

注意! 3 つのウィンドウ関数すべてにおいて、次のようになります。
select t1.*, first_value(salary)over(partition by department order by salary decs), last_value(salary)over(partition by department order by salary decs), nth_value(salary,2)over(partition by department order by salary decs) from salary as t1 order by department関数first_value(salary) over(部門別パーティション)およびlast_value(salary) over(部門別パーティション) は、セクション (部門) 内の最初と最後の給与値を表示します。
次に、関数nth_value(salary, 2) over(partition byDepartment) は、セクション (部門) 内の 2 番目の給与値を表示します。 nth_value()では、追加の引数、つまりセクション内の行番号が指定されることに注意してください。この場合、行番号は 2 なので、関数は 2 番目の給与値を表示します。
上記とは別に、 lag()関数とlead()関数もあります。 lag()関数は、現在の行の前の行から値を取得するために使用されます。 lead() 関数は、現在の行に続く行から値を取得するために使用されます。
select t1.*, lag(salary)over(order by salary), lead(salary)over(order by salary) from salary as t1
ご覧のとおり、関数lag (salary) over (order by給与) は給与を 1 行下にシフトし、関数lead(salary) over(order by給与) は給与を 1 行上にシフトします。これらの関数は非常に似ていますが、 lag()を使用する方が便利だと思います。


注意!これらの関数では、over() 式で order by パラメーターを指定することが必須です。また、partition by を使用してパーティション分割を指定することもできますが、これは必須ではありません。
select t1.*, lag(salary)over(partition by department order by salary) from salary as t1 order by department
ここで、 lag() は以前と同じ機能を実行しますが、特にセクション (部門) 内で実行されます。


重要なポイント
最後に、今日取り上げた内容の概要を簡単に説明します。
累積合計はシーケンスの現在までの合計を表し、後続の加算ごとに累積されます。
ランキング ウィンドウ関数は、ランク付けの基準を指定する式による順序で、一連の値内の値の位置を決定するために使用されます。
オフセット ウィンドウ関数には、 f irst_value() 、 last_value() 、およびnth_value()が含まれており、現在の行からの距離に基づいて他の行からデータを取得できます。 lag()関数とlead()関数を忘れないでください。 lag()関数は現在の行の前の行から値を取得するのに便利ですが、 lead()関数は現在の行の後の行から値を取得するために使用されます。
ご参加いただきありがとうございます。この記事が SQL のウィンドウ関数の機能をより深く理解し、日常的なタスクをより自信を持って迅速に行えるようになることを願っています。








