






















Dans le
Alors maintenant que vous connaissez les bases, explorons des concepts SQL plus avancés. Cela peut paraître un peu compliqué à première vue, mais je vais fournir des exemples simples adaptés aux débutants pour tous les cas possibles, il sera donc facile de comprendre ce que je veux dire.
Aperçu du contenu
-
Cumulative Sum -
Ranking Window Functions -
Use cases -
Offset window functions -
Key Takeaways
Somme cumulée
Nous avons déjà considéré des exemples où l'expression over() n'avait aucun paramètre ou avait une partition par paramètre. Maintenant, nous allons examiner le deuxième paramètre possible pour l'expression over() : trier par.
Demandons le numéro d'identification de l'employé, le nom de l'employé, le service, le salaire et la somme de tous les salaires :
select employee_id, employee_name, department, salary, sum(salary) over() from salary


Maintenant, nous allons ajouter le paramètre order by à l'expression over() :
select employee_id, employee_name, department, salary, sum(salary) over(order by employee_id desc) from salary 

Je suppose que nous devons examiner de plus près ce qui s'est passé ici :
Tout d’abord, Employee_id est désormais trié par ordre décroissant.
Dans la colonne résultant de l'application de la fonction fenêtre, on trouve désormais une somme cumulée.
Je pense que vous connaissez la somme cumulée. Son essence est simple : la somme cumulée ou total cumulé signifie « combien jusqu’à présent ». La définition de la somme cumulée est la somme d’une séquence donnée qui augmente ou s’agrandit avec plus d’ajouts.
Voici ce que nous avons dans notre exemple : pour l'employé avec la valeur Employee_id la plus élevée, le salaire est de 3700, et la somme cumulée est également de 3700. Le deuxième employé a un salaire de 1500, et la somme cumulée est de 5200. Le troisième employé a un salaire de 1500, et la somme cumulée est de 5200. , avec un salaire de 2900, a une somme cumulée de 8100, et ainsi de suite.
Le paramètre order by dans l’expression over() spécifie l’ordre. Dans le cas des fonctions de fenêtre d'agrégation, il détermine l'ordre du total cumulé.
Dans l'expression over() , les attributs partition by et order by peuvent être spécifiés.
select employee_id, employee_name, department, salary, sum(salary) over(partition by department order by employee_id desc) from salary


Dans ce cas, le total cumulé sera calculé par tranches.
Attention ! Si les deux attributs sont spécifiés dans l'expression over() , la partition by vient toujours en premier, suivie de l' ordre by . Par exemple : over(partition by Department Order by Employee_id) .
Après avoir discuté de la somme cumulée, nous devons dire que c'est peut-être le seul type de total cumulé fréquemment utilisé. La moyenne cumulée et le décompte cumulé sont, au contraire, rarement utilisés.
Néanmoins, nous allons donner un exemple de calcul de la moyenne cumulative — il nous indique la moyenne d'une série de valeurs jusqu'à un certain point :
select employee_id, employee_name, department, salary, avg(salary) over(order by employee_id desc) from salary


Fonctions de la fenêtre de classement
Nous utilisons les fonctions de fenêtre de classement pour déterminer la position d'une valeur dans un ensemble de valeurs. L'expression ORDER BY dans la clause OVER dicte la base du classement, chaque valeur étant affectée d'un rang dans sa partition désignée. Lorsque les lignes partagent des valeurs identiques pour les critères de classement, le même classement leur est attribué.
Pour voir comment fonctionnent les fonctions de la fenêtre de classement, demandons les colonnes suivantes du tableau des salaires : ID d'employé, nom de l'employé, service et salaire :
select employee_id, employee_name, department, salary from salary 

Maintenant, nous ajoutons une colonne supplémentaire avec la fonction window row_number() over() :
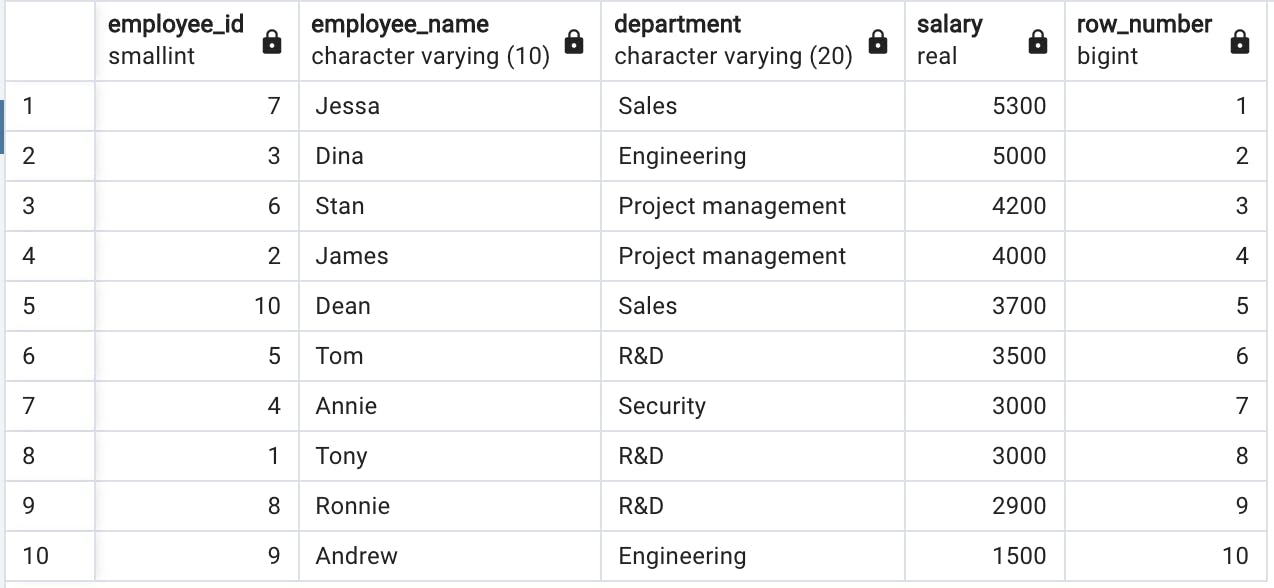
select employee_id, employee_name, department, salary, row_number() over() from salary


La fonction de fenêtre row_number() over() a attribué des numéros aux lignes sans modifier leur ordre. Jusqu’à présent, cela ne nous apporte pas beaucoup de valeur, n’est-ce pas ?
Mais que se passe-t-il si l’on veut numéroter les lignes par ordre décroissant de salaire ? Pour y parvenir, nous devons spécifier l’ordre de tri, c’est-à-dire passer le paramètre order by à l’expression over().
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary

Nous ajouterons les fonctions de classement restantes à la requête à des fins de comparaison :
select employee_id, employee_name, department, salary, row_number() over(order by salary desc), rank() over(order by salary desc), dense_rank() over(order by salary desc), percent_rank() over(order by salary desc), ntile(5) over(order by salary desc) from salary
Passons en revue chaque fonction de la fenêtre de classement :
La fonction de fenêtre row_number() over(order by salaire desc) classe les lignes par ordre décroissant de salaire et attribue des numéros de ligne. Notez qu'Annie et Tony ont le même salaire, mais ils se voient attribuer des numéros différents.
La fonction de fenêtre Rank() over(order by salaire desc ) attribue des rangs par ordre décroissant de salaire. Il attribue le même rang pour des valeurs identiques, mais la valeur suivante obtient un nouveau numéro de ligne.
La fonction de fenêtre dense_rank() over(order by salaire desc) attribue des rangs par ordre décroissant de salaire. Il attribue le même rang pour des valeurs identiques.
La fonction de fenêtre percent_rank() over(order by salaire desc) est le rang relatif (en pourcentage) de la ligne actuelle, calculé par la formule : (rang - 1) / (nombre total de lignes dans la partition - 1).
La fonction de fenêtre ntile(5) over(order by salaire desc) divise le nombre de lignes en 5 parties égales et attribue un numéro à chaque partie. Le nombre de parties est spécifié dans la fonction ntile(5) .
Attention ! Contrairement aux fonctions d'agrégation, par exemple sum(salary), les fonctions de classement, par exemple row_number(), ne prennent pas de colonne à l'intérieur. Cependant, dans la fonction ntile(5), le nombre de parties est spécifié.
Cas d'utilisation
Il est temps d'explorer des tâches pratiques à l'aide des fonctions de la fenêtre de classement. Nous afficherons le numéro d'identification de l'employé, son nom, son service et son salaire, et attribuerons des numéros de ligne par ordre décroissant de salaire.
select employee_id, employee_name, department, salary, row_number() over(order by salary desc) from salary


Parfois, vous devrez peut-être numéroter les lignes par ordre décroissant de salaire au sein des départements (sections). Cela peut être fait en ajoutant l'attribut partition by à l'expression over() :
select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) from salary

Rendons la tâche plus difficile. Nous devons retenir un seul employé par département ayant le salaire le plus élevé. Ceci peut être réalisé en utilisant une sous-requête :
select * from ( select employee_id, employee_name, department, salary, row_number() over(partition by department order by salary desc) as rn from salary ) as t2 where rn = 1


Et encore un exemple, si nous devons afficher trois employés dans chaque ville avec le salaire le plus élevé, nous ferons ce qui suit :
select * from ( select employee_id, employee_name, city, salary, row_number() over(partition by city order by salary desc) as rn from salary ) as t2 where rn <= 3


Ces types de tâches sont très courants, en particulier lorsque vous devez afficher un nombre spécifique de lignes dans des sections (groupes) par ordre croissant ou décroissant d'un attribut. En pratique, j'utilise systématiquement la fonction de fenêtre row_number() over() et, bien sûr, dense_rank() over() également.
Fonctions de fenêtre de décalage
Ces fonctions vous permettent de renvoyer les données d'autres lignes en fonction de leur distance par rapport à la ligne actuelle. Pour le rendre plus visuel, passons en revue les fonctions first_value(), last_value() et nth_value().
select t1.*, first_value(salary)over(partition by department), last_value(salary)over(partition by department), nth_value(salary,2)over(partition by department) from salary as t1 order by department 

Attention ! Dans les trois fonctions de fenêtre, c'est
select t1.*, first_value(salary)over(partition by department order by salary decs), last_value(salary)over(partition by department order by salary decs), nth_value(salary,2)over(partition by department order by salary decs) from salary as t1 order by departmentLes fonctions first_value(salary) over(partition by Department) et last_value(salary) over(Partition by Department) affichent la première et la dernière valeur de salaire dans la section (département).
À son tour, la fonction nth_value(salary, 2) over(partition by Department) affiche la deuxième valeur du salaire au sein de la section (département). Veuillez noter que dans nth_value() , un argument supplémentaire est spécifié : le numéro de ligne dans la section. Dans notre cas, le numéro de ligne est 2, la fonction affiche donc la deuxième valeur du salaire.
Outre ce qui précède, il existe également des fonctions lag() et lead() . La fonction lag() est utilisée pour obtenir la valeur de la ligne qui précède la ligne actuelle. La fonction lead() est utilisée pour obtenir la valeur d’une ligne qui succède à la ligne actuelle.
select t1.*, lag(salary)over(order by salary), lead(salary)over(order by salary) from salary as t1
Comme vous pouvez le voir, la fonction lag (salary) over (order by salaire) décale les salaires vers le bas d'une ligne, et la fonction lead(salary) over (order by salaire) déplace les salaires vers le haut d'une ligne. Bien que ces fonctions soient assez similaires, je trouve plus pratique d'utiliser lag() .


Attention ! Pour ces fonctions, il est obligatoire de préciser le paramètre order by dans l'expression over(). Vous pouvez également spécifier le partitionnement en utilisant partition by, mais ce n'est pas obligatoire.
select t1.*, lag(salary)over(partition by department order by salary) from salary as t1 order by department
Ici, lag() remplit la même fonction qu'auparavant, mais désormais spécifiquement au sein des sections (départements).


Points clés à retenir
Et enfin, un bref aperçu de ce que nous avons couvert aujourd’hui :
La somme cumulée représente le total cumulé d’une séquence, s’accumulant à chaque ajout ultérieur.
Les fonctions de la fenêtre de classement sont utilisées pour déterminer la position d'une valeur dans un ensemble de valeurs, l'expression d'ordre par spécifiant la base du classement.
Les fonctions de fenêtre de décalage incluent first_value() , last_value() et nth_value() , permettant la récupération de données d'autres lignes en fonction de leur distance par rapport à la ligne actuelle. N'oubliez pas les fonctions lag() et lead() . La fonction lag() peut être pratique pour obtenir la valeur de la ligne qui précède la ligne actuelle, tandis que la fonction lead() est utilisée pour obtenir la valeur d'une ligne qui succède à la ligne actuelle.
Merci de m'avoir rejoint. J'espère que cet article vous aidera à mieux comprendre les capacités des fonctions de fenêtre dans SQL et vous rendra plus confiant et plus rapide dans les tâches de routine.








