























Ich habe die 7 beliebtesten AI-Modelle getestet, um zu sehen, wie gut sie Rechnungen aus der Box verarbeiten, ohne irgendwelche Feinabstimmungen.
Lesen, um zu lernen:
- ist
- Welches Modell alle anderen um mindestens 20% übertrifft ist
- Warum Google AI nicht mit strukturierten Daten arbeitet ist
- Sehen Sie, welche Modelle Low-Resolution-Scans am besten bewältigen ist
getestete Modelle
Um das Ziel dieses Tests zu erreichen, begann ich mit der Suche nach KI-Modellen unter Verwendung dieser Kriterien:
- ist
- Beliebtheit: Beliebte Modelle haben bessere Unterstützung und Dokumentation. ist
- Rechnungsverarbeitungsfähigkeit: Das Modell muss in der Lage sein, Rechnungen von Beginn an zu verarbeiten, ohne die API zu finanzieren oder zu trainieren. ist
- Integration: Da die Ergebnisse dieses Tests in der Praxis verwendet werden sollen, ist es wichtig, dass jedes Modell über API-Integrationskapazitäten verfügt, um die Integration zu erleichtern. ist
Ich habe auf 7 AI-Modellen gelandet, die unten aufgeführt sind. Ich habe jedem einen Spitznamen für Bequemlichkeit gegeben:
- ist
- Amazon Analyze Expense API oder „AWS“ ist
- Azure AI Document Intelligence – Invoice Prebuilt Model oder „Azure“ ist
- Google Document AI – Invoice Parser oder „Google“ ist
- GPT-4o API - Texteingabe mit OCR von Drittanbietern oder „GPTt“ ist
- GPT-4o API - Bildeingabe oder „GPTi“ ist
- Gemini 2.0 Pro Experimental oder „Gemini“ ist
- Deepseek v3 - text input, or “Deepseek-t” ist
Rechnungsdatensatz
Die Modelle wurden auf einem Datensatz von 20 Rechnungen verschiedener Layouts und Ausstellungsjahre (von 2006 bis 2020) getestet.
Rechnungsjahr
Anzahl der Rechnungen
Anzahl der Rechnungen
2006 bis 2010
6 zu
6 zu
2011 - 2015
4 zu
2016 bis 2020
Zehn
Zehn
Methodologie
Durch die Analyse jeder Rechnung habe ich eine Liste von 16 Schlüsselfeldern ermittelt, die bei allen Rechnungen üblich sind und die wichtigsten Daten enthalten:
Invoice Id, Invoice Date, Net Amount, Tax Amount, Total Amount, Due Date, Purchase Order, Payment Terms, Customer Address, Customer Name, Vendor Address, Vendor Name, Item: Description, Item: Quantity, Item: Unit Price, Item: Amount.
Die von den Modellen extrahierten Felder wurden zu einer gemeinsamen Namenskonvention gemappt, um Konsistenz zu gewährleisten. LLM-Modelle (GPT, DeepSeek und Gemini) wurden speziell aufgefordert, die Ergebnisse mithilfe dieser gemeinsamen Feldnamen zurückzugeben.
Detektion von Gegenständen
Für jede Rechnung habe ich ausgewertet, wie gut die Modelle die Schlüsselelementfelder extrahiert haben:
Description, Quantity, Unit Price, Total Price
Effizienzmetriken
Ich habe eine gewogene Effizienzmetrik (Eff, %) verwendet, um die Genauigkeit der Extraktion zu beurteilen.
Strenge wesentliche Felder: Genaue Übereinstimmungen wie Rechnungs-ID, Daten usw.
Nicht strenge wesentliche Felder: Teilmatches sind zulässig, wenn die Ähnlichkeit (RLD, %) eine Schwelle überschreitet.
Rechnungsgegenstände: Nur dann als korrekt bewertet, wenn alle Elementeigenschaften korrekt extrahiert werden.
Formeln
Allgemeine Effizienz (Eff, %): Eff, % = (COUNTIF(strict ess. Felder, positiv) + COUNTIF(non-strict ess. Felder, positiv, wenn RLD > RLD Schwelle) + COUNTIF(Elemente, positiv)) / ((COUNT(alle Felder) + COUNT(alle Elemente)) * 100
Effizienz auf Elementebene (Eff-I, %): Eff-I, % = Positiv IF (ALL (Quantität, Einheitspreis, Betrag - positiv) UND RLD (Beschreibung) > RLD Schwelle) * 100
Rechnung Anerkennung Ergebnisse
Effizienz der Datenextraktion (ausgenommen Elemente)


Effizienz der Datenextraktion (einschließlich der Elemente)


Note: Die Ergebnisse von Google werden hiervon ausgelassen, da Google keine Elemente ordnungsgemäß extrahiert hat.
Top Insights
Azure ist mit Elementbeschreibungen nicht das Beste.
In dieser Rechnung konnte Azure die vollständigen Elementnamen nicht erkennen und erkannte nur die ersten Namen, während andere Modelle die vollständigen Namen in allen 12 Elementen erfolgreich identifizierten.
Dieses Problem hatte einen signifikanten Einfluss auf die Effizienz von Azure bei dieser Rechnung, die im Vergleich zu den anderen Modellen deutlich niedriger war (33,3%).
💡 Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.
Die geringe Auflösung der Rechnungen wirkt sich praktisch nicht auf die Qualität der Erkennung aus.
Die niedrige Auflösung führt hauptsächlich zu geringfügigen Erkennungsfehlern, zum Beispiel verwechselt Deepseek in einer der Rechnungen eine Komma mit einem Punkt, was zu einem falschen numerischen Wert führt.
💡 Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.
Google erkennt keine Elemente.
Google kombiniert alle Elementefelder in einer einzigen Zeichenfolge, wodurch es unmöglich ist, die Ergebnisse mit anderen Modellen zu vergleichen.


Aktuelle Rechnung:


Alle anderen Dienste haben 100% korrekte Erkennung mit Abbau nach Attributen.
💡 Google’s AI is not capable of extracting structured data without fine-tuning.
Multi-Line-Artikelbeschreibungen haben die Qualität der Erkennung nicht beeinträchtigt.
💡 Except for Google AI’s case above, multi-line item descriptions did not negatively impact detection quality across all models.
Gemini hat die beste „Aufmerksamkeit fürs Detail“.
LLMs wie GPT, Gemini und DeepSeek können gebeten werden, mehr Daten als vorgefertigte Rechnungserkennungsmodelle zu extrahieren. Unter allen LLMs hat Gemini die beste Genauigkeit, wenn es darum geht, zusätzliche Daten aus Rechnungsartikeln zu extrahieren.
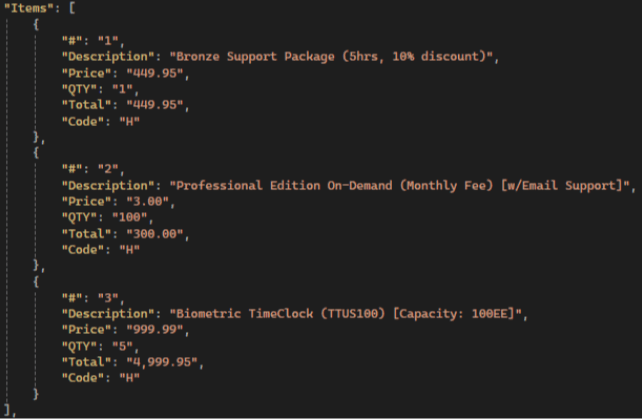
Beispiel für Rechnung:


Ergebnisse von Gemini:

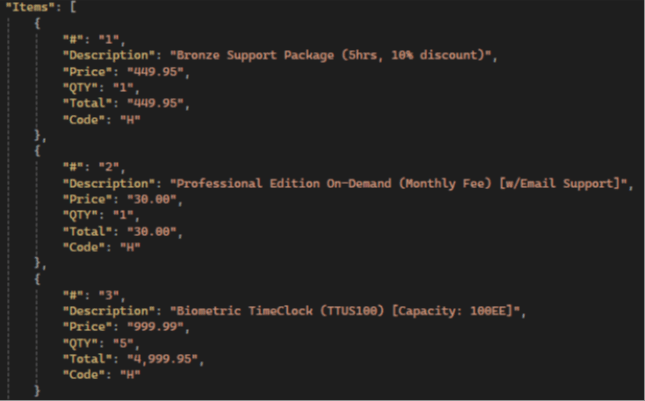
Ergebnisse der GPT:

DeepSeek Ergebnisse:


💡 Gemini has the highest items extraction accuracy compared to other LLMs: it extracts all fields, not just the standard ones, and has the highest accuracy in preserving text and numerical values.
Kosten vergleichen
Ich habe die Kosten für die Verarbeitung von 1000 Rechnungen pro Modell sowie die durchschnittlichen Kosten für die Verarbeitung einer Rechnung berechnet:
| „GPTT“: GPT-4o API, Textzugriff mit OCR von Drittanbietern | $2.50 / 1M Eingabetoken, $10.00 / 1M Ausgabetoken (2) | istfür 0,21 € | ist
| Das Gemini 2.0 Pro | istist $1.25, Eingabeprompts ≤ 128k Tokens$2.50, Eingabeprompts > 128k Tokens$5.00, Ausgabeprompts ≤ 128k Tokens$10.00, Ausgabeprompts > 128k Tokens | ist€ 0,0045 € | ist
Dienstleistung
Kosten
Kosten pro Seite (durchschnittlich)
Kosten pro Seite (durchschnittlich)
10 € / 1000 Seiten (1)
10 € / 1000 Seiten (1)
für 0,01 €
für 0,01 €
Azure AI Document Intelligence
Azure AI Dokumentenintelligenz10 € / 1000 Seiten
10 € / 1000 Seiten
für 0,01 €
10 € / 1000 Seiten
für 0,01 €
für 0,01 €
“GPTT”: GPT-4o API, text input with 3rd party OCR
Die „GPTT“:$2.50 / 1M Eingabetoken, $10.00 / 1M Ausgabetoken (2)
für 0,21 €
für 0,21 €
$2.50 / 1M Eingangs-Token, $10.00 / 1M Ausgabe-Token
€ 0,0087
$1.25, Eingabeprompts ≤ 128k Tokens$2.50, Eingabeprompts > 128k Tokens$5.00, Ausgabeprompts ≤ 128k Tokens$10.00, Ausgabeprompts > 128k Tokens
$1.25, Eingabeprompts ≤ 128k Tokens$2.50, Eingabeprompts > 128k Tokens$5.00, Ausgabeprompts ≤ 128k Tokens$10.00, Ausgabeprompts > 128k Tokens
€ 0,0045 €
€ 0,0045 €
$10 / 1000 pages + $0.27 / 1M input tokens, $1.10 / 1M output tokens
Die Deepseek v3 API
$10 / 1000 Seiten + $0.27 / 1M Eingabetoken, $1.10 / 1M Ausgabetoken
$10 / 1000 Seiten + $0.27 / 1M Eingabetoken, $1.10 / 1M Ausgabetoken
von 011
Notes:
(1) — $8 / 1000 Seiten nach einer Million pro Monat
(2) — Zusätzliche 10 US-Dollar pro 1000 Seiten für die Verwendung eines Texterkennungsmodells
Schlüsselfunde
Most EfficientGemini und GPT-4o sind führend in der Effizienz und Konsistenz der Extraktion auf allen Rechnungen.
️Worst performer: Google AI ist das Schlimmste von allen getesteten Modellen, wenn es um die Extraktion von Artikeln geht, wodurch die Gesamteffizienz-Score niedrig ist.
Least ReliableDeepSeek zeigte häufige Fehler in Text- und Zahlenwerten.
Welches Modell ist am besten für was?
✅ Gemini, AWS oder Azure für hochgenaue Datenerfassung.
✅ GPT-4o (Text-Eingabe mit OCR von Drittanbietern) für kosteneffiziente Rechnungserkennung und ein großartiges „Kosten-Effizienz“-Gleichgewicht.
Vermeiden Sie Google AI, wenn Sie Elemente mit hoher Genauigkeit extrahieren müssen.








