






















Autori :
Korišćenje(1) Aman Madaan, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
Korišćenje(2) Shuyan Zhou, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
Korišćenje(3) Uri Alon, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
Korišćenje(4) Yiming Yang, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
KorišćenjeGraham Neubig, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]).
KorišćenjeAuthors:
(1) Aman Madaan, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
(2) Shuyan Zhou, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
(3) Uri Alon, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
(4) Yiming Yang, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]);
Graham Neubig, Institut za jezične tehnologije, Carnegie Mellon University, SAD ([email protected]).
Levo od stola
2 COCOGEN: Predstavljanje Commonsense struktura sa kodom i 2.1 Konvertiranje (T,G) u Python kod
2.2 Nekoliko prompting za generisanje G
3 Evaluacija i 3.1 Eksperimentalno postavljanje
3.2 Generacija scenarija: Proscript
3.3 Pratenje stanja entiteta: PROPARA
3.4 Generiranje grafika argumenta: EXPLAGRAPHS
6 Zaključak, priznanja, ograničenja i reference
A Few-shot modeli procjene veličine
G Dizajn Python klase za strukturirani zadatak
Abstrakcija
Da bismo upotrijebili velike jezikovne modele (LM) za ovaj zadatak, postojeće pristupe “serializiraju” izlazni graf kao ravnu listu čvorova i rubova: iako je moguće, ovi serializirani grafovi snažno odstupaju od prirodnog jezikovnog korpusa na kojem su LM-ovi bili prethodno obučeni, sprečavajući LM-ove da ih ispravno generiraju. U ovom članku pokazujemo da kada umesto da okvirizujemo strukturirane zajedničke jezikovne zadatke kao zadatke za generiranje koda, prethodno obučeni LM-ovi koda su bolji strukturirani zajednički jezikovni razlozi od LM-ova za prirodni jezik, čak i kada zadatak u daljnjem toku uopšte ne uključuje izvorni kod. Pokazujemo naš pristup kroz tri različHTTPS://github.com/madaan/CoCoGen Preduzeće za zaštitu podatakaNaši
1 Uvod
Sve veće mogućnosti velikih predtreniranih jezičnih modela (LLM) za generisanje teksta omogućile su njihovu uspješnu primjenu u raznim zadacima, uključujući sažetak, prevođenje i odgovaranje na pitanja (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
Ipak, dok je zapošljavanje LLM-ova za zadatke prirodnog jezika (NL) jednostavno, jedan od glavnih preostalih izazova je kako iskoristiti LLM-ove za strukturirano razmatranje zajedničkog razuma, uključujući zadatke kao što su generiranje grafikona događaja (Tandon et al., 2019), grafikoni razmatranja (Madaan et al., 2021a), skripti (Sakaguchi et al., 2021), i grafikoni objašnjenja argumenata (Saha et al., 2021). Za razliku od tradicionalnih zadataka razmatranja zajedničkog razuma kao što su razumevanje čitanja ili odgovor na pitanje, strukturirani zajednički razum ima za cilj generisanje strukturiranog izlaza s obzirom na unos prirodnog jezika. Ova porodica zadataka se oslanja na prirodno znanje jezika koje je naučio LL
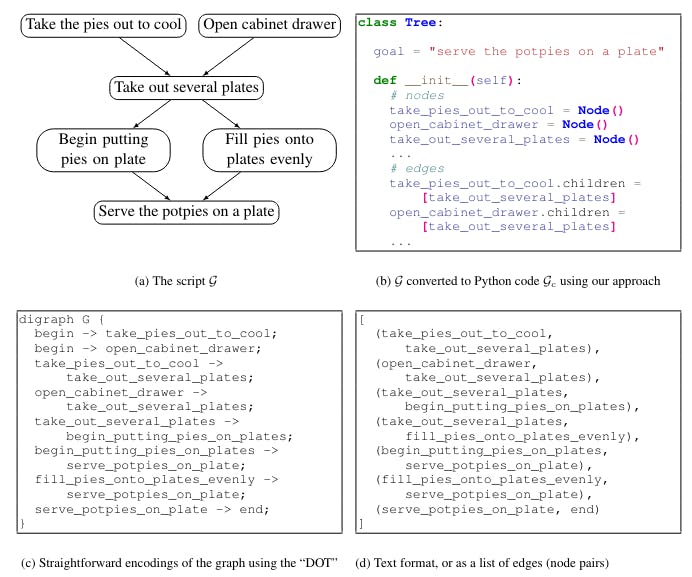
Konkretno, struktura koja se generira (npr, grafikon ili tabela) se konvertuje, ili "serializuje", u tekst. Takve konverzije uključuju "flattening" grafikon u listu pari čvorova (slika 1d), ili u jezik specifikacije kao što je DOT (slika 1c; Gansner et al., 2006).
Dok je pretvaranje strukturiranog izlaza u tekst pokazalo obećavajuće rezultate (Rajagopal et al., 2021; Madaan i Yang, 2021), LLM-ovi se bore da generišu ove „neprijatne“ izlaze: LM-ovi su prvenstveno prethodno obučeni na tekst u slobodnom obliku, a ovi serializirani strukturirani izlazi snažno se razlikuju od većine pre-trening podataka.
Stoga, korištenje LLM-ova za generaciju grafova obično zahtijeva veliku količinu podataka o obuci specifičnih za zadatke, a njihovi generisani izlazi pokazuju strukturne greške i semantičke nedosljednosti, koje treba dodatno popraviti ili ručno ili pomoću sekundarnog modela u daljnjem toku (Madaan et al., 2021b).
Unatoč ovim borbama, nedavni uspjeh velikih jezičnih modela koda (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) za zadatke kao što su generacija koda iz prirodnog jezika (Austin et al., 2021; Nijkamp et al., 2022), dovršetak koda (Fried et al., 2022), i prevođenje koda (Wang et al., 2021), pokazuje da su Code-LLMs u stanju izvoditi složeno razmatranje na strukturiranim podacima kao što su programi. Tako, umesto da prisiljavaju LLMs iz prirodnog jezika (NL-LLMs) da budu fino prilagođeni na strukturirane podatke o zajedničkom razumu, lakši način da se zatvori neusklađenost između pre-treninga podataka (slobodni tekst

Dakle, naš glavni uvid je da su veliki jezični modeli koda dobri strukturirani razmatrači zdravog razuma. Nadalje, pokazujemo da Code-LLM-ovi mogu biti još bolje strukturirani razmatrači od NL-LLM-ova, kada pretvaraju željeni izlazni grafikon u format sličan onome koji se promatra u podacima pre-treninga koda.CoZaCobesmislicaGenerekciju, a to je prikazano na slici 1.
Naši doprinosi su sledeći:
- Korišćenje
- Naglašavamo uvid da su Code-LLM-ovi bolje strukturirani razumni rasuđivači od NL-LLM-ova, kada predstavljaju željeni graf predviđanja kao kod. Korišćenje
- Predlažemo COCOGEN: metoda za iskorištavanje LLM-ova koda za strukturiranu generaciju zdravog razuma. Korišćenje
- Izvršavamo opsežnu evaluaciju u tri strukturirana zadatka za generiranje zdravog razuma i pokazujemo da COCOGEN znatno nadmašuje NL-LLM-ove, bilo da su fine-tuned ili malo-shot testirani, dok kontroliraju broj uzastopnih primjera zadataka. Korišćenje
- Izvodimo temeljitu studiju ablacije, koja pokazuje ulogu oblikovanja podataka, veličinu modela i broj nekoliko primjera. Korišćenje
Ovaj dokument je dostupan na archiv pod licencom CC BY 4.0 DEED.
KorišćenjeOvaj dokument je dostupan na archiv pod licencom CC BY 4.0 DEED.




