






















Die skrywers:
die(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
die(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
die(3) Uri Alon, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
die(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
die(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]).
dieAuthors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]);
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon Universiteit, VSA ([email protected]).
Tabel van links
2 COCOGEN: Verteenwoordig Commonsense strukture met kode en 2.1 Omskep (T,G) in Python kode
2.2 Vele-skot prompting vir die genereer van G
3 Beoordeling en 3.1 Eksperimentele instelling
3.2 Script generasie: PROSCRIPT
3.3 Entity state tracking: PROPARA
3.4 Argument graf generasie: verduidelikings
6 Conclusie, erkennings, beperkings en verwysings
A Few-shot modelle grootte ramings
G Ontwerp Python-klas vir 'n gestruktureerde taak
H Impact van die model grootte
abstrakte
Ons spreek die algemene taak van gestruktureerde algemene rede: Gegewe 'n natuurlike taal invoer, is die doel om 'n graaf soos 'n gebeurtenis of 'n rede-graaf te genereer. Om groot taalmodelle (LM's) vir hierdie taak te gebruik, sal bestaande benaderings die uitvoergraaf as 'n plat lys van nodes en rande "serialiseer". Alhoewel dit haalbaar is, verskil hierdie geserialiseerde grafieke sterk van die natuurlike taalkorpora waarop LM's vooroplei is, wat LM's belemmer om hulle korrek te genereer. In hierdie artikel toon ons dat wanneer ons in plaas daarvan gestruktureerde gemeenskaplike rede-takke as kode-generasie-takke raam, vooropleide LM's van kode beter gestruktureHTTPS://github.com/madaan/CoCoGen in die Verenigde StateDie
1 Inleiding
Die groeiende vermoëns van groot vooraf opgeleide taalmodelle (LLM's) vir die genereer van teks het hulle suksesvol toegepas in 'n verskeidenheid take, insluitend samestelling, vertaling en vraag-answering (Wang et al., 2019; Raffel et al., 2019; Brown et al., 2020; Chowdhery et al., 2022).
Tog, terwyl die gebruik van LLM's vir natuurlike taal (NL) take is eenvoudig, is 'n groot oorblywende uitdaging is hoe om LLM's te benut vir gestruktureerde gemeenskaplike redevoering, insluitend take soos die genereer van gebeurtenis grafieke (Tandon et al., 2019), redevoering grafieke (Madaan et al., 2021a), skripte (Sakaguchi et al., 2021), en argument verduideliking grafieke (Saha et al., 2021). In teenstelling met tradisionele gemeenskaplike redevoering take soos lees begrip of vrae antwoord, gestruktureerde gemeenskaplike bedoel om gestruktureerde output te genereer gegee 'n natuurlike taal invoer. Hierdie familie van take is afhanklik van die natuurlike taal kennis geleer deur die LLM, maar dit vereis ook komplekse
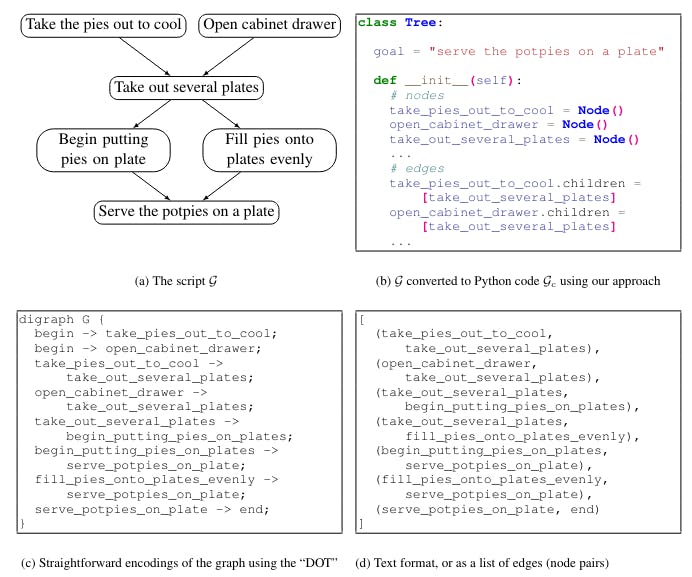
Om LLM's te benut, verander bestaande gestruktureerde gemeenskaplike generasie modelle die uitvoerformaat van 'n probleem. Spesifiek, die struktuur wat gegenereer moet word (bv, 'n grafiek of 'n tabel) word omskep, of "serialiseer", in teks. Sulke omskepings sluit in die "flattening" van die grafiek in 'n lys van knooppare (Figuur 1d), of in 'n spesifikasie taal soos DOT (Figuur 1c; Gansner et al., 2006).
Terwyl die omskeping van die gestruktureerde output in teks veelbelovende resultate getoon het (Rajagopal et al., 2021; Madaan en Yang, 2021), streef LLMs om hierdie "onnatuurlike" outputs te genereer: LMs word hoofsaaklik vooroplei op vrye vormtekst, en hierdie seriale gestruktureerde outputs verskil sterk van die meerderheid van die vooropleiding data.
As gevolg hiervan vereis die gebruik van LLM's vir grafiese generasie tipies 'n groot hoeveelheid taak-spesifieke opleiding data, en hul gegenereerde uitkomste toon strukturele foute en semantiese inkonsistensies, wat verder gefixeer moet word, óf handmatig of deur gebruik te maak van 'n sekondêre downstream model (Madaan et al., 2021b).
Ten spyte van hierdie stryd, die onlangse sukses van groot-taal modelle van kode (Code-LLMs; Chen et al., 2021b; Xu et al., 2022) vir take soos kode generasie uit natuurlike taal (Austin et al., 2021; Nijkamp et al., 2022), kode voltooiing (Fried et al., 2022), en kode vertaling (Wang et al., 2021), toon dat Code-LLMs in staat is om komplekse redewerk op gestruktureerde data soos programme uit te voer.

So, ons primêre insig is dat groot taal modelle van kode is goeie gestruktureerde gesamentlike redevoerder. Verder, ons wys dat Code-LLMs kan selfs beter gestruktureerde redevoerder as NL-LLMs, wanneer die gewenste output grafiek omskep in 'n formaat soortgelyk aan wat waargeneem word in die kode voor-opleiding data. Ons noem ons metode COCOGEN: modelle vanCovan dieCoMonsoonGenvervaardiging, en dit word in Figuur 1 getoon.
Ons bydraes is die volgende:
- die
- Ons beklemtoon die insig dat Code-LLM's beter gestruktureerde gemeenskaplike redevaarders as NL-LLM's is, wanneer die gewenste grafieksvoorspelling as kode verteenwoordig word. die
- Ons voorstel COCOGEN: 'n metode vir die benutting van LLMs van kode vir gestruktureerde gesamentlike generasie. die
- Ons voer 'n omvattende evaluering uit oor drie gestruktureerde gesinsgenererende take en wys dat COCOGEN aansienlik die NL-LLM's oorskry, of dit goed aangepas of min-skot getesteer is, terwyl die aantal downstream taakvoorbeelde beheer word. die
- Ons voer 'n gedetailleerde ablasie studie uit, wat die rol van data-formatering, modelgrootte en die aantal paar-shoot voorbeelde toon. die
Hierdie artikel is beskikbaar op archiv onder CC BY 4.0 DEED lisensie.
dieHierdie artikel is beskikbaar op archiv onder CC BY 4.0 DEED lisensie.








