





















スレッド ダンプを読み取り、アプリケーションの実行時の動作を制御する方法を学習します。
Adobe Experience Manager (または一般的な JAVA アプリケーション) インスタンスに遅延の兆候が見られる場合は、袖をまくり上げてスレッド ダンプの世界に飛び込む必要があります。IBM Thread Analyzer (TDA) は、スレッドの網を解きほぐし、パフォーマンスのボトルネックを正確に特定するのに役立ちます。このガイドでは、IBM TDA を使用して AEM のパフォーマンスの問題をプロのように診断する方法について説明します。

ステップ1: IBM TDAをダウンロードしてインストールする
スレッド ダンプの分析を開始する前に、 IBM Thread Analyzer をダウンロードしてインストールする必要があります。IBM の公式 Web サイトまたは組織のリポジトリにアクセスして、最新バージョンを入手してください。ダウンロードしたら、オペレーティング システムのインストール手順に従ってください。これは迅速かつ簡単で、本格的なトラブルシューティングの準備を整えます。


ステップ 2: AEM インスタンスからスレッド ダンプをキャプチャする
スレッド ダンプは、特定の瞬間に AEM インスタンスで実行されているすべてのスレッドのスナップショットです。これをキャプチャするには、次の手順を実行します。
- AEM サーバーにアクセスします。
- スレッド ダンプを生成するには、
jstack、kill -3などのツールや、AEM の組み込み機能を使用します。Adobe Docsに、詳細に説明されたページがあります。 - スレッド ダンプ ファイルをローカル マシンに保存します。


プロのヒント: 長期にわたる問題をより明確に把握するには、一定の間隔 (たとえば、10 秒ごと) で複数のスレッド ダンプをキャプチャします。
ステップ3: IBM TDAでスレッドダンプを開く
IBM TDA を起動し、キャプチャしたスレッド ダンプ ファイルを開きます。ファイルをアプリケーションにドラッグ アンド ドロップするか、[開く] オプションを使用して読み込みます。読み込まれると、左側のパネルにスレッド ダンプのリストが表示されます。


ステップ4: スレッドの詳細を確認する
特定のスレッド ダンプを分析するには:
- リストからファイルを選択します。
- 上部のスレッド詳細ボタンをクリックします


これにより、そのダンプ内のすべてのスレッドの詳細が表示されます。次に、スタックの深さでスレッドを並べ替えて、最も長いスタックが一番上に表示されるようにします。なぜでしょうか? スタックが深いスレッドは、多くの場合、より複雑な操作を示しており、通常、パフォーマンスの問題が隠れている場所です。


ステップ5: 関心のあるスレッドを特定する
スタックの深さが 10 行以上のスレッドに注目してください。これらのスレッドは通常、最も多くのリソースを消費するスレッドです。名前、状態、スタック トレースなど、目立つスレッドがあればメモを取ります。
ステップ6: スレッドの状態による並べ替え
次に、スレッドを状態別に並べ替えます。下にスクロールして、実行可能なスレッドを表示します。これらは、ダンプが取得されたときに CPU 時間をアクティブに使用していたスレッドです。次のようなアプリケーション固有のスレッドに注意してください。
- バックグラウンド ジョブ スレッド: インデックス作成やレプリケーションなどのタスクを処理します。
- リクエストスレッド:
127.0.0.1 [timestamp] GET /path HTTP/1.1のように名前が付けられます。


ステップ7: リクエストタイムスタンプをデコードする
各リクエスト スレッドについて、その名前からタイムスタンプを抽出します (例: 1347028187737 )。この Unix エポック タイムスタンプは、ユーザーのブラウザーがリクエストを行った時刻を示します。https ://www.epochconverter.com/などのツールを使用して、これを人間が判読できる日付/時刻に変換します。これをスレッド ダンプのタイムスタンプと比較して、リクエストがアクティブであった時間を計算します。
差が異常に大きい場合 (数秒または数分など)、アプリケーションのボトルネックが発生している可能性があります。
プロのヒント: パターンに注意してください。特定の種類のリクエストは一貫して時間がかかっていませんか? たとえば、複雑なクエリやリソースを大量に消費する操作を伴うリクエストは最適化する価値があるかもしれません。さらに、特定の URL またはエンドポイントが長時間実行されるスレッドに頻繁に関連付けられていることに気付いた場合は、コードベースのそれらの領域のプロファイリングを検討してください。
ステップ8: 待機中のスレッドを調査する
スレッド分析には、単純な待機状態を超えた微妙なアプローチが必要です。IBM Thread Analyzer (TDA) インターフェースはスレッドの関係に関する貴重な洞察を提供しますが、スレッドの動作のコンテキスト全体を理解することで、アプリケーションのパフォーマンス特性をより完全に把握できるようになります。
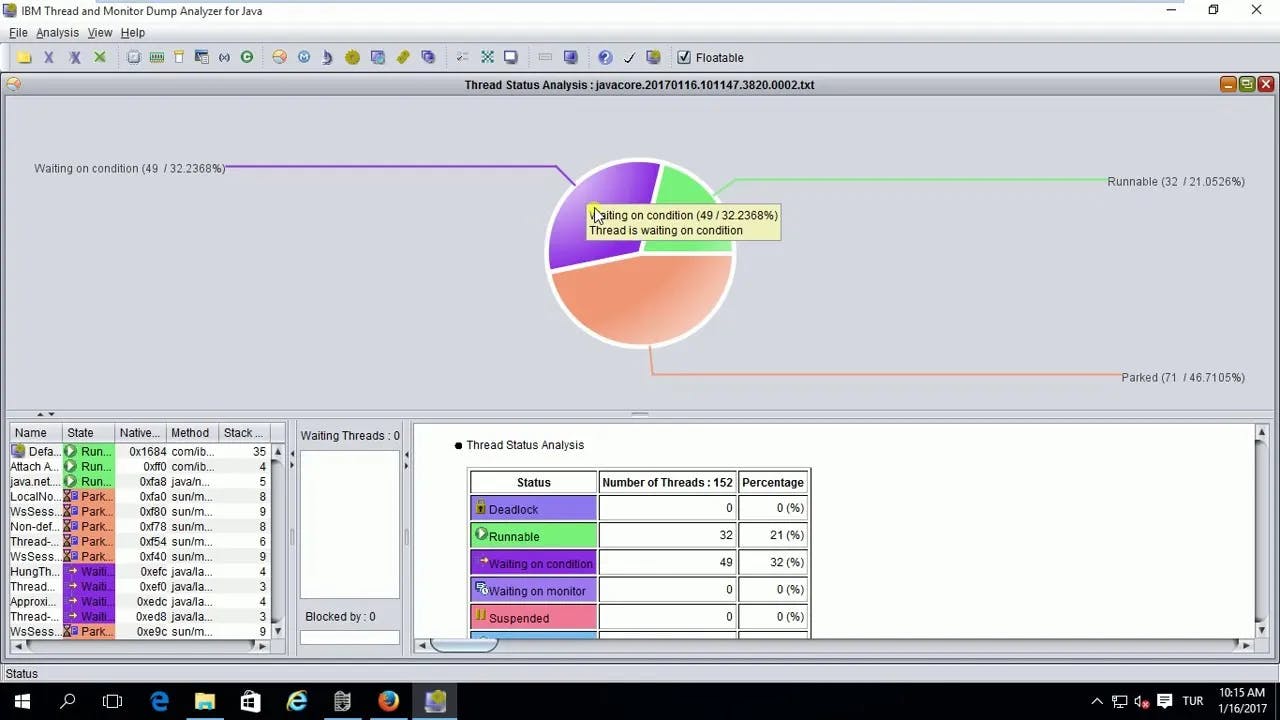
スレッドの状態を理解する
TDA でスレッドを調べると、いくつかの重要な状態に遭遇します。
実行可能: これらのスレッドは現在実行中であるか、CPU 時間が利用可能になったときに実行できる状態です。実行可能状態は必ずしも問題を示すわけではなく、アクティブに動作しているスレッドの自然な状態です。
待機中: これらのスレッドは、条件が満たされるのを待機している間、一時的に実行を一時停止しています。待機状態は、次のような多くの正当な理由で発生する可能性があります。
- リソースの可用性(データベース接続、ファイルハンドル)
- 他のスレッドでのタスクの完了
- 予定されている遅延
- ネットワークI/Oの完了
- メッセージキュー操作


ブロック: これらのスレッドは、特にモニターまたはロックを取得するために待機しています。待機に似ていますが、ブロック状態は特に同期関連の一時停止を示します。
スレッド関係の分析
興味のあるスレッドを特定したら、次の体系的なアプローチを使用して、他のスレッドとの関係を調べます。
- 直接ロック関係:
- 待機中のスレッドパネルで即時の依存関係を確認します
- 待機中のスレッドのスタックトレースを確認して、ブロックされている理由を理解する
- 待機状態が可能な場合は、その期間を記録します。
2. リソース使用パターン:
- リソースの獲得と解放のパターンを探す
- 潜在的なリソースのボトルネックを特定する
- 代替的なリソース管理戦略を検討する
3. 建築上の意味:
- 観察された動作がシステムの設計と一致しているかどうかを評価する
- 現在のスレッドモデルが適切かどうか検討する
- スケーラビリティへの影響を評価する
ロックの種類と可視性を理解する
スレッド ダンプにはすべてのタイプの競合が表示されない場合があります。最新の Java アプリケーションでは、さまざまな同期メカニズムが使用されています。
- 固有ロック(同期キーワード):
- スレッドダンプに表示される
- オーナーとウェイターの関係を明確に示す
- スタックトレースは同期ポイントを示します
2. 明示的なロック (java.util.concurrent):
- 再入ロック
- 読み取り書き込みロック
- スタンプロック
- 視覚化には追加のツールが必要になる場合があります
3. 非ブロッキング メカニズム (従来のロックのようには表示されませんが、パフォーマンスに影響を与える可能性があります)。
- 原子変数
- 同時ハッシュマップ
- 完了可能な未来
最適化戦略
真の競合問題を特定した場合は、次のアプローチを検討してください。
- コードレベルの改善
- ロック範囲を縮小する
- より細かいロックを実装する
- 非ブロッキングの代替案を検討する
2. リソース管理
- プールサイズを最適化する
- バックオフ戦略を実装する
- キャッシュソリューションを検討する
3. アーキテクチャの変更
- 非同期処理を評価する
- 並列実行パスを考慮する
- キューベースのアプローチを実装する
スレッド分析は反復的なプロセスであることに注意してください。 1 つのスレッド ダンプで出現するパターンは、一貫した動作を表していない可能性があります。 アプリケーションに大幅な変更を加える前に、必ず複数のダンプとさまざまな期間にわたって結果を検証してください。
ステップ 9: 長時間実行スレッドの複数のスレッド ダンプを比較する
スレッド ダンプを時間経過に沿って比較すると、AEM インスタンスの重要なパフォーマンス パターンが明らかになります。まず、ピーク使用期間やメンテナンス期間など、通常の操作中にベースラインを確立します。このベースラインは、異常なスレッド動作を識別するためのコンテキストを提供します。
スレッドが時間を超えて永続的であるかどうかを判断するには:
- 異なる時点からの複数のスレッド ダンプを選択します。
- IBM TDA の「スレッドの比較」ボタンをクリックします。
- すべてのダンプにわたって実行可能状態のままになっているスレッド、特にスタック トレースが一貫して長いスレッドを探します。


IBM TDA のスレッド比較機能を使用して、異なる時点のダンプを分析します。複数のダンプ間で存続するスレッドに注目し、その状態、スタックの深さ、リソースの使用状況を調べます。スレッドの存続だけでは、必ずしも問題が示されるわけではないことに注意してください。バックグラウンド サービスは当然継続的に実行されますが、要求スレッドは予想される時間枠内で完了するはずです。
永続的な実行可能スレッドを分析する場合は、その動作を CPU 使用率、メモリ消費量、応答時間などのシステム メトリックと相関させます。スレッドの目的を考慮します。バックグラウンド サービス、要求処理、またはメンテナンス タスクにはそれぞれ異なるパターンが予想されます。要求スレッドの場合は、定義されたサービス レベル アグリーメントおよびビジネス要件と継続時間を比較します。
疑わしいスレッド パターンが見つかりましたか? まだ結論に飛びつかないでください。まずはテスト環境で問題を再現してみてください。本番前のリハーサルのようなものです。コードをよく調べ、構成設定を再確認し、環境内で他に何が問題を引き起こしている可能性があるかを検討してください。実際のパフォーマンス数値とテスト結果で発見した内容を追跡してください。後で感謝することになるでしょう。
パフォーマンスの本当の原因を突き止めたら (もちろん、確固たる証拠に基づいて)、それを修正します。
ステップ10: モニターの詳細を調べてアイドルスレッドを特定する
スレッドを分析しても実用的な洞察が得られない場合は、モニターの詳細ビューに切り替えます。
- スレッド一覧に戻ります。
- スレッド ダンプを選択し、[詳細の監視] ボタンをクリックします。
- IBM TDA は、モニターを所有するスレッドとその待機中のスレッドのツリー ビューを表示します。


このビューは、モニターを保持して競合を引き起こしているスレッドを識別するのに役立ちます。スレッド モニターを理解することは、アプリケーションの神経系を確認するようなものです。これらの同期メカニズムは、スレッドが共有リソースにアクセスする方法を制御し、潜在的な競合を防ぎ、スムーズな操作を保証します。


モニターのインタラクションにより、パフォーマンスに関する重要な洞察が得られます。一部のスレッドはリクエストをアクティブに処理していますが、他のスレッドはリソースの取得を待機したり、調整されたアクティビティに参加したりします。待機中またはアイドル状態のスレッドのすべてが問題を示しているわけではありません。多くの場合、これらはアプリケーションの自然なリソース管理戦略の一部です。
ただし、すべてのスレッドが同じように重要であるわけではありません。
- アイドル状態のスレッド プールのスレッドを無視します。これらのスレッドは通常、スタック行数が 10 以下で、サーブレット エンジンなどのスレッド プールの一部です。スレッド プールを占有しない限り、通常は無害です。
- アプリケーション固有のモニターに焦点を当てる: データベース接続、キャッシュ メカニズム、カスタム同期ブロックなど、アプリケーションのビジネス ロジックに関連付けられたモニターを探します。
スレッドとモニターの分析は芸術であると同時に科学でもあることを忘れないでください。各アプリケーションには独自の特性があるため、パフォーマンスの最適化には好奇心と全体的な視点を持って取り組みます。目標は、待機中のスレッドをすべて排除することではなく、それらの相互作用を理解して最適化することです。
高度なヒント: 特定のモニターが頻繁に競合していることに気付いた場合は、ロックの粒度を下げるようにコードをリファクタリングすることを検討してください。例:
- 粗粒度のロックを細粒度のロックに置き換えます。
- 可能な場合は、非ブロッキング アルゴリズムまたは並行データ構造を使用します。
- データベース クエリを最適化して、スレッドがロックを待機する時間を短縮します。
ボーナス情報: コレクターサービス
一部のスレッド ダンプでは、 Collector Service が頻繁に表示されることがあります。このサービスは、ガベージ コレクション、メモリ管理、リソースのクリーンアップなどのタスクを処理します。Collector Service は謎めいたバックグラウンド プロセスのように見えるかもしれませんが、その動作を理解することが最適なシステム パフォーマンスを維持する鍵となります。大規模なオフィス ビルの勤勉な清掃員のようなものだと考えてください。
コレクター サービスのアクティビティが頻繁に発生していることに気付いても、すぐに問題だと決めつけないでください。コレクター サービスがときどき発生するのは正常ですが、アクティビティが多すぎる場合は、根本的な問題が考えられます。
- メモリ リーク: ガベージ コレクションされていないオブジェクトにより、GC サイクルが頻繁に発生する可能性があります。
- オブジェクトの高い変動: オブジェクトの急速な作成と破棄により、ガベージ コレクターが圧倒される可能性があります。
- 不適切な JVM 設定: ヒープ サイズまたは GC アルゴリズムの構成が間違っていると、非効率になる可能性があります。
リソースの使用を最適化するための考慮事項は次のとおりです。
- JVM 設定の調整 (例: ヒープ サイズの増加、G1GC への切り替え)。
- Eclipse MATやYourKitなどのツールを使用してメモリ使用量をプロファイリングし、リークを特定します。
- アプリケーションのメモリ割り当てパターンを確認して、不要なオブジェクトの作成を減らします。
ガベージ コレクションは解決すべき問題ではなく、理解して最適化すべき動的なシステムです。各アプリケーションには固有の特性があり、普遍的な解決策はありません。
最後に
スレッド ダンプ分析は開発者のスーパーパワーであり、コード作成者からパフォーマンスの探偵へと変身させます。IBM Thread Analyzer (TDA) は、複雑なシステム動作を理解し、Java/AEM インスタンスのパフォーマンスに影響を与える隠れたボトルネックを明らかにするための鍵となります。
楽器を習得するのと同じように、スキルは練習すればするほど向上します。各スレッド ダンプはより明確になり、システム相互作用の複雑なパターンが明らかになります。分析すればするほど、パフォーマンスの最適化はより直感的になります。
覚えておいてください、練習すれば完璧になります。スレッド ダンプを分析すればするほど、診断スキルは磨かれていきます。📊💪
🛠 ️トラブルシューティングを楽しんでください。Java/AEM インスタンスをスムーズに実行し続けるために、発見した内容をチームと共有することを忘れないでください。








