






















Autores:
(1) Guillaume Staerman, INRIA, CEA, Univ. París-Saclay, Francia;
(2) Marta Campi, CERIAH, Institut de l'Audition, Institut Pasteur, Francia;
(3) Gareth W. Peters, Departamento de Estadística y Probabilidad Aplicada, Universidad de California en Santa Bárbara, EE.UU.
Tabla de enlaces
2. Antecedentes y preliminares
2.1. Bosque de aislamiento funcional
3. Método de bosque de aislamiento de firmas
4.1. Análisis de sensibilidad de parámetros
4.2. Ventajas del (K-)SIF sobre el FIF
4.3. Punto de referencia para la detección de anomalías con datos reales
5. Discusión y conclusión, declaraciones de impacto y referencias
Apéndice
A. Información adicional sobre la firma
C. Experimentos numéricos adicionales
4.1. Análisis de sensibilidad de parámetros
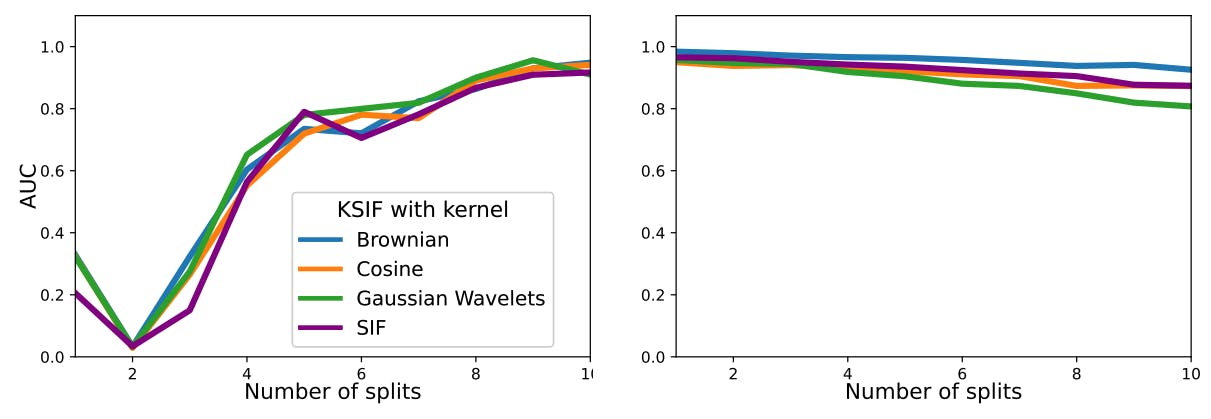
Investigamos el comportamiento de K-SIF y SIF con respecto a sus dos parámetros principales: la profundidad de la firma k y el número de ventanas divididas ω. Por razones de espacio, el experimento sobre la profundidad se pospone en la Sección C.1 del Apéndice.
La función de la ventana dividida de firmas. La cantidad de ventanas divididas permite la extracción de información en intervalos específicos (seleccionados aleatoriamente) de los datos subyacentes. De este modo, en cada nodo del árbol, el enfoque estará en una porción particular de los datos, que es la misma en todas las curvas de muestra para fines de comparación. Este enfoque garantiza que el análisis se realice en secciones comparables de los datos, lo que proporciona una forma sistemática de examinar y comparar diferentes intervalos o características en las curvas de muestra.
Exploramos el papel de este parámetro con dos conjuntos de datos diferentes que reproducen dos tipos de escenarios de anomalías. El primero considera anomalías aisladas en un intervalo pequeño, mientras que el segundo contiene anomalías persistentes a lo largo de toda la parametrización de la función. De esta manera, observamos el comportamiento de K-SIF y SIF con respecto a diferentes tipos de anomalías.
El primer conjunto de datos se construye de la siguiente manera. Simulamos 100 funciones constantes. Luego seleccionamos al azar el 90% de estas curvas y el ruido gaussiano en un subintervalo; para el 10% restante de las curvas, agregamos ruido gaussiano en otro subintervalo, diferente del primero. Más precisamente:
• El 90% de las curvas, consideradas como normales, se generan según


con ε(t) ∼ N (0, 1), b ∼ U([0, 100]) y U representando la distribución uniforme.
• El 10% de las curvas, consideradas como anormales, se generan de acuerdo a


donde ε(t) ∼ N (0, 1) y b ∼ U([0, 100]).


Simulamos aleatoriamente el 90% de las trayectorias con µ = 0, σ = 0,5 y las consideramos como datos normales. Luego, el 10% restante se simula con una desviación µ = 0,2, una desviación estándar σ = 0,4 y se considera como datos anormales. Calculamos K-SIF con diferentes números de ventanas divididas, que varían de 1 a 10, con un nivel de truncamiento establecido en 2 y N = 1000 el número de árboles. El experimento se repite 100 veces y reportamos el AUC promedio bajo las curvas ROC en la Figura 1 para ambos conjuntos de datos y tres diccionarios preseleccionados.
En el caso del primer conjunto de datos, en el que las anomalías se manifiestan en una pequeña parte de las funciones, aumentar el número de divisiones mejora significativamente el rendimiento del algoritmo en la detección de anomalías. La mejora del rendimiento muestra una meseta después de nueve ventanas divididas. En el caso del segundo conjunto de datos con anomalías persistentes, una mayor cantidad de ventanas divididas tiene un impacto marginal en el rendimiento del algoritmo, manteniendo resultados satisfactorios. Por lo tanto, sin conocimiento previo sobre los datos, optar por una cantidad relativamente alta de ventanas divididas, como 10, garantizaría un rendimiento sólido en ambos escenarios. Además, una cantidad más significativa de ventanas divididas permite el cálculo de la firma en una porción más pequeña de las funciones, lo que conduce a una mejor eficiencia computacional.

Este artículo está disponible en arxiv bajo la licencia CC BY 4.0 DEED.








