






















Авторы:
(1) Гийом Стаерман, INRIA, CEA, Univ. Париж-Сакле, Франция;
(2) Марта Кампи, CERIAH, Институт прослушивания, Институт Пастера, Франция;
(3) Гарет В. Питерс, кафедра статистики и прикладной теории вероятностей, Калифорнийский университет в Санта-Барбаре, США.
Таблица ссылок
2. Предыстория и предварительные сведения
2.1. Функционально-изоляционный лес
3. Метод леса сигнатурной изоляции
4.1 Анализ чувствительности параметров
4.2 Преимущества (К-)SIF перед FIF
4.3. Тест обнаружения аномалий в реальных данных
5. Обсуждение и заключение, заявления о влиянии и ссылки
Приложение
А. Дополнительная информация о подписи
C. Дополнительные численные эксперименты
4.1 Анализ чувствительности параметров
Мы исследуем поведение K-SIF и SIF относительно их двух основных параметров: глубины сигнатуры k и числа разделенных окон ω. Для экономии места эксперимент по глубине отложен в разделе C.1 в Приложении.
Роль окна разделения подписи. Количество окон разделения позволяет извлекать информацию по определенным интервалам (случайно выбранным) базовых данных. Таким образом, в каждом узле дерева фокус будет сосредоточен на определенной части данных, которая одинакова для всех выборочных кривых в целях сравнения. Такой подход гарантирует, что анализ выполняется на сопоставимых участках данных, предоставляя систематический способ изучения и сравнения различных интервалов или характеристик по выборочным кривым.
Мы исследуем роль этого параметра с двумя различными наборами данных, которые воспроизводят два типа сценариев аномалий. Первый рассматривает изолированные аномалии в небольшом интервале, тогда как второй содержит постоянные аномалии во всей параметризации функции. Таким образом, мы наблюдаем поведение K-SIF и SIF в отношении различных типов аномалий.
Первый набор данных строится следующим образом. Мы моделируем 100 постоянных функций. Затем мы выбираем случайным образом 90% этих кривых и гауссовский шум на подынтервале; для оставшихся 10% кривых мы добавляем гауссовский шум на другом подынтервале, отличном от первого. Точнее:
• 90% кривых, считающихся нормальными, генерируются в соответствии с


где ε(t) ∼ N (0, 1), b ∼ U([0, 100]) и U представляет равномерное распределение.
• 10% кривых, считающихся ненормальными, генерируются в соответствии с


где ε(t) ∼ N (0, 1) и b ∼ U([0, 100]).


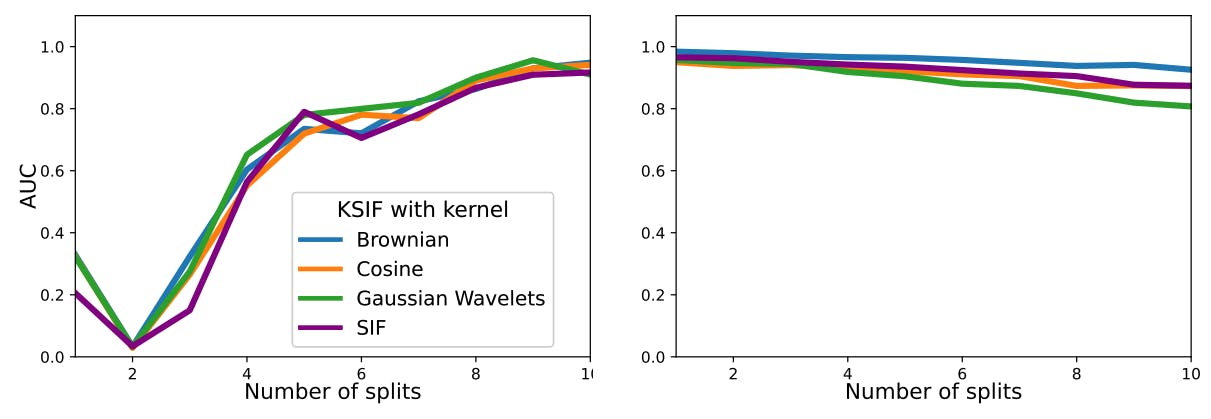
Мы моделируем случайным образом 90% путей с µ = 0, σ = 0,5 и считаем их нормальными данными. Затем оставшиеся 10% моделируются с дрейфом µ = 0,2, стандартным отклонением σ = 0,4 и считаются аномальными данными. Мы вычисляем K-SIF с различным количеством окон разделения, варьирующимся от 1 до 10, с уровнем усечения, равным 2, и N = 1000 — количеством деревьев. Эксперимент повторяется 100 раз, и мы сообщаем усредненную AUC под кривыми ROC на рисунке 1 для обоих наборов данных и трех предварительно выбранных словарей.
Для первого набора данных, где аномалии проявляются в небольшой части функций, увеличение количества разделений значительно повышает производительность алгоритма при обнаружении аномалий. Улучшение производительности показывает плато после девяти разделенных окон. В случае второго набора данных с постоянными аномалиями большее количество разделенных окон оказывает незначительное влияние на производительность алгоритма, поддерживая удовлетворительные результаты. Поэтому без предварительного знания данных выбор относительно большого количества разделенных окон, например 10, обеспечит надежную производительность в обоих сценариях. Кроме того, большее количество разделенных окон позволяет вычислять сигнатуру на меньшей части функций, что приводит к повышению вычислительной эффективности.

Данная статья доступна на arxiv по лицензии CC BY 4.0 DEED.








