






















Waandishi:
(1) Guillaume Staerman, INRIA, CEA, Univ. Paris-Saclay, Ufaransa;
(2) Marta Campi, CERIAH, Institut de l'Audition, Institut Pasteur, Ufaransa;
(3) Gareth W. Peters, Idara ya Takwimu na Uwezekano Uliotumika, Chuo Kikuu cha California Santa Barbara, Marekani.
Jedwali la Viungo
2.1. Msitu wa Kutengwa wa Kitendaji
3. Njia ya Msitu ya Kutengwa kwa Sahihi
4.1. Uchambuzi wa Unyeti wa Vigezo
4.2. Manufaa ya (K-)SIF zaidi ya FIF
4.3. Kigezo cha Utambuzi wa Ukosefu wa Data halisi
5. Majadiliano na Hitimisho, Taarifa za Athari, na Marejeleo
Nyongeza
A. Maelezo ya Ziada Kuhusu Sahihi
C. Majaribio ya ziada ya Nambari
4.1. Uchambuzi wa Unyeti wa Vigezo
Tunachunguza tabia ya K-SIF na SIF kwa kuzingatia vigezo vyao viwili kuu: kina cha saini k na idadi ya madirisha yaliyogawanyika ω. Kwa ajili ya mahali, jaribio la kina limeahirishwa katika Sehemu ya C.1 katika Kiambatisho.
Jukumu la Dirisha la Kugawanya Sahihi. Idadi ya madirisha yaliyogawanyika inaruhusu uchimbaji wa habari kwa vipindi maalum (vilivyochaguliwa bila mpangilio) vya data ya msingi. Kwa hivyo, katika kila nodi ya mti, mkazo utakuwa kwenye sehemu fulani ya data, ambayo ni sawa katika mikondo yote ya sampuli kwa madhumuni ya kulinganisha. Mbinu hii inahakikisha kuwa uchanganuzi unafanywa kwa sehemu zinazoweza kulinganishwa za data, ikitoa njia ya kimfumo ya kuchunguza na kulinganisha vipindi au vipengele tofauti katika mikondo ya sampuli.
Tunachunguza jukumu la kigezo hiki na seti mbili tofauti za data zinazozalisha aina mbili za matukio ya hitilafu. Ya kwanza inazingatia hitilafu zilizojitenga katika muda mdogo, ilhali ya pili ina zinazoendelea katika vigezo vyote vya utendakazi. Kwa njia hii, tunaona tabia ya K-SIF na SIF kuhusiana na aina tofauti za hitilafu.
Hifadhidata ya kwanza imeundwa kama ifuatavyo. Tunaiga kazi 100 za mara kwa mara. Kisha tunachagua bila mpangilio 90% ya mikunjo hii na kelele ya Gaussian kwenye muda mdogo; kwa 10% iliyobaki ya curves, tunaongeza kelele ya Gaussian kwenye muda mwingine mdogo, tofauti na wa kwanza. Kwa usahihi zaidi:
• 90% ya curves, kuchukuliwa kama kawaida, ni yanayotokana na


na ε(t) ∼ N (0, 1), b ∼ U([0, 100]) na U inayowakilisha mgawanyo sawa.
• 10% ya mikunjo, inayochukuliwa kuwa isiyo ya kawaida, hutolewa kulingana na


ambapo ε(t) ∼ N (0, 1) na b ∼ U([0, 100]).


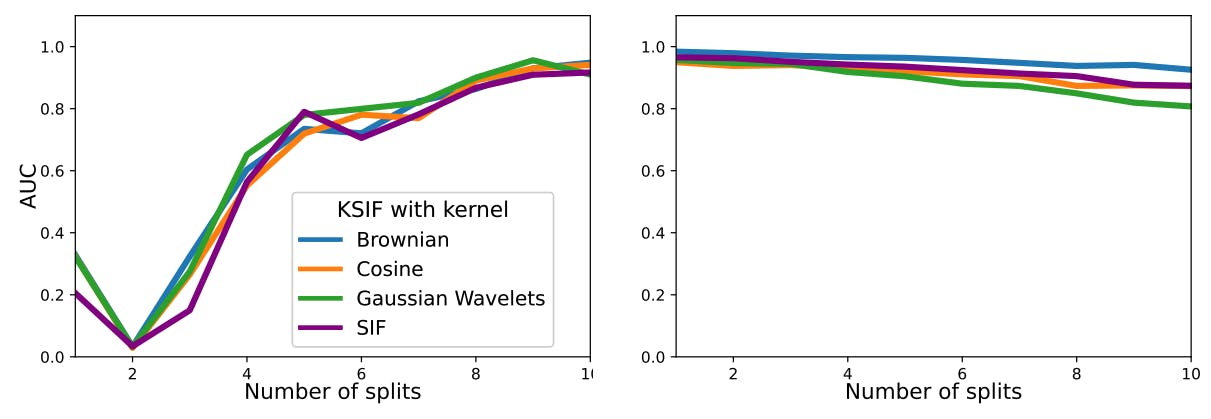
Tunaiga bila mpangilio 90% ya njia na µ = 0, σ = 0.5, na kuzizingatia kama data ya kawaida. Kisha, 10% iliyobaki inaigwa na drift µ = 0.2, mkengeuko wa kawaida σ = 0.4, na kuzingatiwa data isiyo ya kawaida. Tunahesabu K-SIF na nambari tofauti za madirisha yaliyogawanyika, tofauti kutoka 1 hadi 10, na kiwango cha kukata kilichowekwa sawa na 2 na N = 1, 000 idadi ya miti. Jaribio linarudiwa mara 100, na tunaripoti wastani wa AUC chini ya mikondo ya ROC kwenye Mchoro wa 1 kwa seti zote mbili za data na kamusi tatu zilizochaguliwa mapema.
Kwa mkusanyiko wa data wa kwanza, ambapo hitilafu hujitokeza katika sehemu ndogo ya chaguo za kukokotoa, kuongeza idadi ya migawanyiko huongeza utendaji wa algoriti katika kugundua hitilafu. Uboreshaji wa utendakazi unaonyesha uwanda baada ya madirisha tisa yaliyogawanyika. Katika kesi ya mkusanyiko wa pili wa data wenye hitilafu zinazoendelea, idadi kubwa ya madirisha yaliyogawanyika huwa na athari ya kando kwenye utendakazi wa algoriti, ikidumisha matokeo ya kuridhisha. Kwa hivyo, bila maarifa ya awali kuhusu data, kuchagua idadi kubwa ya madirisha yaliyogawanyika, kama vile 10, kungehakikisha utendakazi thabiti katika hali zote mbili. Zaidi ya hayo, idadi kubwa zaidi ya madirisha yaliyogawanyika huwezesha ukokotoaji wa saini kwenye sehemu ndogo ya kazi, hivyo basi kuboresha ufanisi wa hesabu.

Karatasi hii inapatikana kwenye arxiv chini ya leseni ya CC BY 4.0 DEED.








