

Forfattere:
(1) Guillaume Staerman, INRIA, CEA, Univ. Paris-Saclay, Frankrig;
(2) Marta Campi, CERIAH, Institut de l'Audition, Institut Pasteur, Frankrig;
(3) Gareth W. Peters, Department of Statistics & Applied Probability, University of California Santa Barbara, USA.
Tabel over links
2.1. Funktionel isolationsskov
3. Signatur isolation skov metode
4.1. Parametre Følsomhedsanalyse
4.2. Fordele ved (K-)SIF frem for FIF
4.3. Benchmark for registrering af anomalier med rigtige data
5. Diskussion og konklusion, konsekvenserklæringer og referencer
Tillæg
A. Yderligere oplysninger om signaturen
C. Yderligere numeriske eksperimenter
4.1. Parametre Følsomhedsanalyse
Vi undersøger adfærden af K-SIF og SIF med hensyn til deres to hovedparametre: dybden af signaturen k og antallet af opdelte vinduer ω. For stedets skyld er forsøget på dybden udsat i afsnit C.1 i bilaget.
Rollen af signaturopdelt vindue. Antallet af opdelte vinduer tillader udtrækning af information over specifikke intervaller (tilfældigt udvalgt) af de underliggende data. Ved hver træknude vil fokus således være på en bestemt del af dataene, som er ens på tværs af alle prøvekurverne til sammenligningsformål. Denne tilgang sikrer, at analysen udføres på sammenlignelige dele af dataene, hvilket giver en systematisk måde at undersøge og sammenligne forskellige intervaller eller funktioner på tværs af prøvekurverne.
Vi udforsker denne parameters rolle med to forskellige datasæt, der gengiver to typer af anomaliscenarier. Den første betragter isolerede anomalier i et lille interval, mens den anden indeholder vedvarende på tværs af al funktionsparametrisering. På denne måde observerer vi adfærden hos K-SIF og SIF med hensyn til forskellige typer af anomalier.
Det første datasæt er opbygget som følger. Vi simulerer 100 konstante funktioner. Vi vælger så tilfældigt 90% af disse kurver og Gaussisk støj på et underinterval; for de resterende 10 % af kurverne tilføjer vi Gaussisk støj på et andet underinterval, der er forskelligt fra det første. Mere præcist:
• 90% af kurverne, betragtet som normale, er genereret iflg


hvor ε(t) ~ N (0, 1), b ~ U([0, 100]) og U repræsenterer den ensartede fordeling.
• 10 % af kurverne, betragtet som unormale, genereres iflg


hvor ε(t) ~ N (0, 1) og b ~ U([0, 100]).


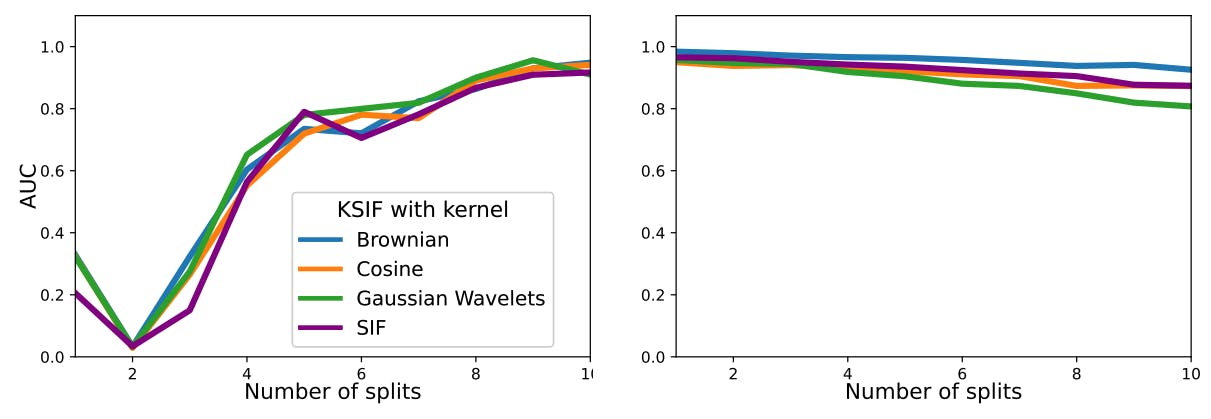
Vi simulerer tilfældigt 90 % af stierne med µ = 0, σ = 0,5, og betragter dem som normale data. Derefter simuleres de resterende 10 % med drift µ = 0,2, standardafvigelse σ = 0,4 og betragtes som unormale data. Vi beregner K-SIF med forskellige antal opdelte vinduer, varierende fra 1 til 10, med et trunkeringsniveau sat lig med 2 og N = 1.000 antallet af træer. Eksperimentet gentages 100 gange, og vi rapporterer den gennemsnitlige AUC under ROC-kurverne i figur 1 for både datasæt og tre forudvalgte ordbøger.
For det første datasæt, hvor uregelmæssigheder manifesterer sig i en lille del af funktionerne, forbedrer en forøgelse af antallet af opdelinger algoritmens ydeevne til at opdage uregelmæssigheder markant. Ydeevneforbedringen viser et plateau efter ni delte vinduer. I tilfælde af det andet datasæt med vedvarende anomalier, har et højere antal opdelte vinduer en marginal indvirkning på algoritmens ydeevne, hvilket bevarer tilfredsstillende resultater. Derfor, uden forudgående viden om dataene, vil et relativt højt antal opdelte vinduer, såsom 10, sikre robust ydeevne i begge scenarier. Derudover muliggør et mere betydeligt antal opdelte vinduer beregningen af signaturen på en mindre del af funktionerne, hvilket fører til forbedret beregningseffektivitet.

Dette papir er tilgængeligt på arxiv under CC BY 4.0 DEED-licens.