























Таблица с връзки
Предложен подход
3.2 Цифрови мрежи на SPD колектори
B. MLR в структурните пространства
C. Формулиране на MLR от гледна точка на разстоянията до хиперравнините
Г. Разпознаване на човешки действия
F. Ограничения на нашата работа
З. Изчисляване на канонично представяне
I. Доказателство на твърдение 3.2
J. Доказателство на твърдение 3.4
K. Доказателство на твърдение 3.5
L. Доказателство на твърдение 3.6
М. Доказателство на твърдение 3.11
Н. Доказателство за твърдение 3.12
4 ЕКСПЕРИМЕНТА
4.1 РАЗПОЗНАВАНЕ НА ЧОВЕШКИ ДЕЙСТВИЯ
Използваме три набора от данни, т.е. HDM05 (Muller et al., 2007), FPHA (Garcia-Hernando et al., 2018) и ¨ NTU RBG+D 60 (NTU60) (Shahroudy et al., 2016). Ние сравняваме нашите мрежи със следните най-съвременни модели: SPDNet (Huang & Gool, 2017)[1], SPDNetBN (Brooks et al., 2019)[2], SPSDAI (Nguyen, 2022a), GyroAI- HAUNet (Nguyen, 2022b) и MLR-AI (Nguyen & Yang, 2023).
4.1.1 ИЗСЛЕДВАНЕ НА АБЛАЦИЯ
Конволюционни слоеве в SPD невронни мрежи Нашата мрежа GyroSpd++ има MLR слой, подреден върху конволюционен слой (вижте Фиг. 1). Мотивацията за използване на конволюционен слой

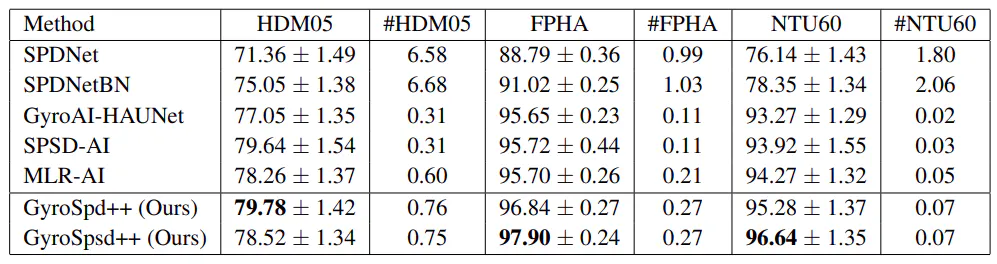


е, че може да извлича глобални характеристики от локални (ковариационни матрици, изчислени от съвместни координати в рамките на подпоследователности от последователност от действия). Използваме афинно-инвариантни метрики за конволюционния слой и лог-евклидови метрики за MLR слоя. Резултати в табл. 1 показват, че GyroSpd++ постоянно превъзхожда базовите линии на SPD по отношение на средна точност. Резултатите от GyroSpd++ с различни дизайни на римановите метрики за неговите слоеве са дадени в Приложение D.4.1.
MLR в структурните пространства Ние изграждаме GyroSpsd++, като заменяме MLR слоя на GyroSpd++ с MLR слой, предложен в раздел 3.3. Резултатите от GyroSpsd++ са дадени в табл. 1. С изключение на SPSDAI, GyroSpsd++ превъзхожда другите базови линии на набор от данни HDM05 по отношение на средна точност. Освен това GyroSpsd++ превъзхожда GyroSpd++ и всички базови линии на набори от данни FPHA и NTU60 по отношение на средна точност. Тези резултати показват, че MLR е ефективен, когато е проектиран в структурни пространства от гледна точка на жировекторното пространство.
4.2 КЛАСИФИКАЦИЯ НА ВЪЗЕЛИТЕ
Използваме три набора от данни, т.е. Airport (Zhang & Chen, 2018), Pubmed (Namata et al., 2012a) и Cora (Sen et al., 2008), като всеки от тях съдържа една графика с хиляди етикетирани възли. Ние сравняваме нашата мрежа Gr-GCN++ (вижте Фиг. 1) с нейния вариант Gr-GCN-ONB (вижте Приложение E.2.4) въз основа на перспективата на ONB. Резултатите са показани в табл. 2. И двете мрежи дават най-добра производителност за n = 14 и p = 7. Може да се види, че Gr-GCN++ превъзхожда Gr-GCN-ONB във всички случаи. Пропуските в производителността са значителни за наборите от данни Pubmed и Cora.
автори:
(1) Xuan Son Nguyen, ETIS, UMR 8051, CY Cergy Paris University, ENSEA, CNRS, Франция ([email protected]);
(2) Shuo Yang, ETIS, UMR 8051, CY Cergy Paris University, ENSEA, CNRS, Франция ([email protected]);
(3) Aymeric Histace, ETIS, UMR 8051, CY Cergy Paris University, ENSEA, CNRS, Франция ([email protected]).
Тази хартия е
[1] https://github.com/zhiwu-huang/SPDNet.
[2] https://papers.nips.cc/paper/2019/hash/6e69ebbfad976d4637bb4b39de261bf7-Абстракт. html.




