

























The LLM Knowledge Graph Builder is one of Neo4j’s GraphRAG Ecosystem Tools that empowers you to transform unstructured data into dynamic knowledge graphs. It is integrated with a Retrieval-Augmented Generation (RAG) chatbot, enabling natural language querying and explainable insights into your data.
What Is the Neo4j LLM Knowledge Graph Builder?
The Neo4j LLM Knowledge Graph Builder is an innovative online application for turning unstructured text into a knowledge graph with no code and no Cypher, providing a magical text-to-graph experience. It uses ML models (LLMs: OpenAI, Gemini, Diffbot) to transform PDFs, web pages, and YouTube videos into a knowledge graph of entities and their relationships.
The front end is a React application based on our Needle Starter Kit, and the back end is a Python FastAPI application. It uses the llm-graph-transformer module that Neo4j contributed to LangChain.
The application provides a seamless experience, following four simple steps:
- Data Ingestion — Supports various data sources, including PDF documents, Wikipedia pages, YouTube videos, and more.
- Entity Recognition — Uses LLMs to identify and extract entities and relationships from unstructured text.
- Graph Construction — Converts recognized entities and relationships into a graph format, using Neo4j graph capabilities.
- User Interface — Provides an intuitive web interface for users to interact with the application, facilitating the upload of data sources, visualization of the generated graph, and interaction with a RAG agent. This capability is particularly exciting as it allows for intuitive interaction with the data, akin to having a conversation with the knowledge graph itself — no technical knowledge is required.


Let’s Try It Out
We provide the application on our Neo4j-hosted environment with no credit cards required and no LLM keys — friction-free.
Alternatively, to run it locally or within your environment, visit the public GitHub repo and follow the step-by-step instructions we will cover in this post.
Before we open and use the LLM Knowledge Graph Builder, let’s create a new Neo4j database. For that, we can use a free AuraDB database by following these steps:
- Log in or create an account at https://console.neo4j.io.
- Under Instances, create a new AuraDB Free Database.
- Download the credentials file.
- Wait until the instance is running.
Now that we have our Neo4j database running and our credentials, we can open the LLM Knowledge Graph Builder, and click Connect to Neo4j in the top-right corner.


Drop the previously downloaded credentials file on the connection dialog. All the information should be automatically filled. Alternatively, you can enter everything manually.
Creating the Knowledge Graph
The process begins with the ingestion of your unstructured data, which is then passed through the LLM to identify key entities and their relationships.
You can drag and drop PDFs and other files into the first input zone on the left. The second input will let you copy/paste the link to a YouTube video you want to use, while the third input takes a Wikipedia page link.
For this example, I will load a few PDFs I have about a supply-chain company called GraphACME, a press article from Forbes, and a YouTube video about the Corporate Sustainability Due Diligence Directive (CSDDD), as well as two pages from Wikipedia: Corporate Sustainability Due Diligence Directive and Bangladesh.
While uploading the files, the application will store the uploaded sources as document nodes in the graph using LangChain Document Loaders and YouTube parsers. Once all files have been uploaded, you should see something similar to this:


All we need to do now is select the model to use, click Generate Graph, and let the magic do the rest for you!
If you only want to generate a file selection, you can select the files first (with the checkbox in the first column of the table) and click Generate Graph.
⚠️ Note that if you want to use a pre-defined or your own graph schema, you can click on the setting icon in the top-right corner and select a pre-defined schema from the drop-down, use your own by writing down the node labels and relationships, pull the existing schema from an existing Neo4j database, or copy/paste text and ask the LLM to analyze it and come up with a suggested schema.
While it is processing your files and creating your Knowledge Graph, let me summarize what is happening under the hood:
- The content is split into chunks.
- Chunks are stored in the graph and connected to the document node and to each other for advanced RAG patterns.
- Highly similar chunks are connected with a SIMILAR relationship to form a K-Nearest Neighbors graph.
- Embeddings are computed and stored in the chunks and vector index.
- Using the llm-graph-transformer or diffbot-graph-transformer, entities and relationships are extracted from the text.
- Entities are stored in the graph and connected to the originating chunks.
Explore Your Knowledge Graph
The information extracted from your document is structured into a graph format, where entities become nodes, and relationships turn into edges connecting these nodes. The beauty of using Neo4j lies in its ability to efficiently store and query these complex data networks, making the generated knowledge graph immediately useful for a variety of applications.
Before we use the RAG agent to ask questions about our data, we can select one document (or many) with the checkbox and click Show Graph. This will display the entities created for the document(s) you selected; you can also display the document and chunks node in that view:
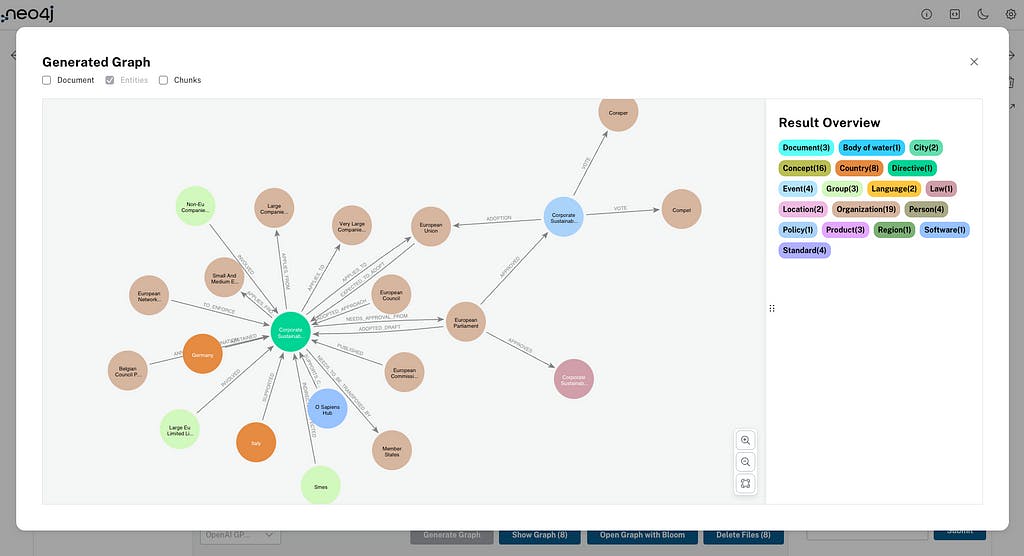
The Open Graph with Bloom button will open Neo4j Bloom to help you visualize and navigate your newly created knowledge graph. The next action — Delete files — deletes the selected documents and chunks from the graph (and entities if you select it in the options).
Talk to Your Knowledge
Now comes the last part: the RAG agent you can see in the right panel.
The Retrieval Process — How Does It Work?
The image below shows a simplified view of the GraphRAG process.


When the user asks a question, we use the Neo4j vector index with a retrieval query to find the most relevant chunks for the question and their connected entities up to a depth of 2 hops. We also summarize the chat history and use it as an element to enrich the context.
The various inputs and sources (the question, vector results, chat history) are all sent to the selected LLM model in a custom prompt, asking to provide and format a response to the question asked based on the elements and context provided. Of course, the prompt has more magic, such as formatting, asking to cite sources, to not speculate if an answer is not known, etc. The full prompt and instructions can be found as FINAL_PROMPT in QA_integration.py.
Ask Questions Related to Your Data
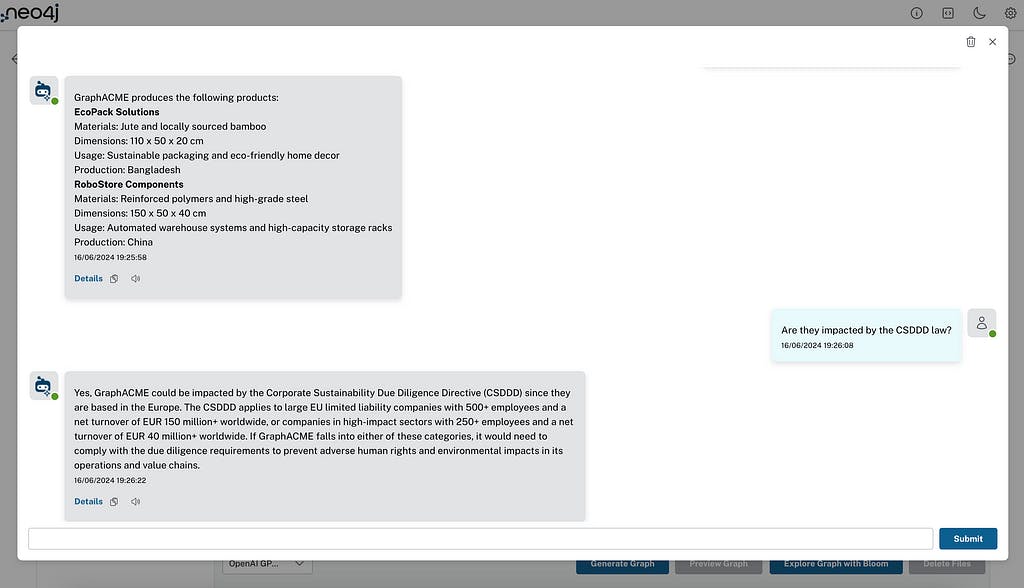
In this example, I loaded internal documents about a fake company named GraphACME (based in Europe), producing and documenting their whole supply-chain strategy and products. I also loaded a press article and YouTube video explaining the new CSDDD, its impact, and regulation. We can now ask the chatbot questions about our internal (fake) company knowledge — questions about the CSDDD law, or even questions across both, such as asking for the list of products GraphACME produces, if they will be affected by the CSDDD regulation, and if so, how it will impact the company.

Chat Features
On the right side of the home screen, you will notice three buttons attached to the chat window:
- Close will close the chatbot interface.
- Clear chat history will delete the current session’s chat history.
- Maximize window will open the chatbot interface in a full-screen mode.
On the RAG agent’s answers, you will find three features after the response:
- Details will open a retrieval information pop-up showing how the RAG agent collected and used sources (documents), chunks, and entities. Information about the model used and the token consumption is also included.
- Copy will copy the content of the response to the clipboard.
- Text-to-Speech will read the response content aloud.


Wrap-up
To dive deeper into the LLM Knowledge Graph Builder, the GitHub Repository offers a wealth of information, including source code and documentation. Additionally, our Documentation provides detailed guidance on getting started, and GenAI Ecosystem offers further insights into the broader tools and applications available.
What’s Next — Contributing and Extension Capabilities
Your experience with the LLM Knowledge Graph Builder is invaluable. If you encounter bugs, have suggestions for new features, want to contribute, or wish to see certain enhancements, the community platform is the perfect place to share your thoughts. For those adept in coding, contributing directly on GitHub can be a rewarding way to help evolve the project. Your input and contributions not only help improve the tool but also foster a collaborative and innovative community:
Resources
Learn more about new resources for GenAI applications: Neo4j GraphRAG Ecosystem Tools. These open-source tools make it easy to get started with GenAI applications grounded with knowledge graphs, which help improve response quality and explainability and accelerate app development and adoption.
Video
Links
- Get Started With GraphRAG: Neo4j’s Ecosystem Tools
- GitHub – neo4j-labs/llm-graph-builder: Neo4j graph construction from unstructured data
- Neo4j LLM Knowledge Graph Builder – Extract Nodes and Relationships from Unstructured Text (PDF, YouTube, Webpages) – Neo4j Labs
- GenAI Ecosystem – Neo4j Labs
- Needle StarterKit 2.0: Templates, Chatbot, and More!












