
























LLM Knowledge Graph Builder es una de las herramientas del ecosistema GraphRAG de Neo4j que le permite transformar datos no estructurados en gráficos de conocimiento dinámicos. Está integrado con un chatbot de recuperación y generación aumentada (RAG), lo que permite realizar consultas en lenguaje natural y obtener información explicable sobre sus datos.
¿Qué es el generador de gráficos de conocimiento Neo4j LLM?
Neo4j LLM Knowledge Graph Builder es una innovadora aplicación en línea para convertir texto no estructurado en un gráfico de conocimiento sin código ni Cypher, lo que proporciona una experiencia mágica de texto a gráfico. Utiliza modelos de aprendizaje automático (LLM: OpenAI, Gemini, Diffbot) para transformar archivos PDF, páginas web y videos de YouTube en un gráfico de conocimiento de entidades y sus relaciones.
El front-end es una aplicación React basada en nuestro Needle Starter Kit y el back-end es una aplicación Python FastAPI. Utiliza el módulo llm-graph-transformer que Neo4j contribuyó a LangChain.
La aplicación ofrece una experiencia perfecta, siguiendo cuatro sencillos pasos:
- Ingestión de datos: admite varias fuentes de datos, incluidos documentos PDF, páginas de Wikipedia, videos de YouTube y más.
- Reconocimiento de entidades: utiliza LLM para identificar y extraer entidades y relaciones de texto no estructurado.
- Construcción de gráficos: convierte entidades y relaciones reconocidas en un formato de gráfico, utilizando las capacidades de gráficos de Neo4j.
- Interfaz de usuario: proporciona una interfaz web intuitiva para que los usuarios interactúen con la aplicación, lo que facilita la carga de fuentes de datos, la visualización del gráfico generado y la interacción con un agente RAG. Esta capacidad es particularmente interesante, ya que permite una interacción intuitiva con los datos, similar a tener una conversación con el propio gráfico de conocimiento; no se requieren conocimientos técnicos.


Vamos a probarlo
Proporcionamos la aplicación en nuestro entorno alojado en Neo4j sin necesidad de tarjetas de crédito ni claves LLM, sin ningún tipo de inconvenientes.
Alternativamente, para ejecutarlo localmente o dentro de su entorno, visite el repositorio público de GitHub y siga las instrucciones paso a paso que cubriremos en esta publicación.
Antes de abrir y utilizar el generador de gráficos de conocimiento de LLM, vamos a crear una nueva base de datos Neo4j. Para ello, podemos utilizar una base de datos AuraDB gratuita siguiendo estos pasos:
- Inicie sesión o cree una cuenta en https://console.neo4j.io .
- En Instancias, cree una nueva base de datos gratuita de AuraDB.
- Descargue el archivo de credenciales.
- Espere hasta que la instancia se esté ejecutando.
Ahora que tenemos nuestra base de datos Neo4j ejecutándose y nuestras credenciales, podemos abrir LLM Knowledge Graph Builder y hacer clic en Conectar a Neo4j en la esquina superior derecha.


Coloque el archivo de credenciales descargado anteriormente en el cuadro de diálogo de conexión. Toda la información debería completarse automáticamente. También puede ingresar todo manualmente.
Creación del gráfico de conocimiento
El proceso comienza con la ingesta de sus datos no estructurados, que luego pasan a través del LLM para identificar entidades clave y sus relaciones.
Puede arrastrar y soltar archivos PDF y otros archivos en la primera zona de entrada a la izquierda. La segunda entrada le permitirá copiar y pegar el enlace a un video de YouTube que desee utilizar, mientras que la tercera entrada contiene un enlace a una página de Wikipedia.
Para este ejemplo, cargaré algunos archivos PDF que tengo sobre una empresa de cadena de suministro llamada GraphACME, un artículo de prensa de Forbes y un video de YouTube sobre la Directiva de debida diligencia de sostenibilidad corporativa (CSDDD), así como dos páginas de Wikipedia: Directiva de debida diligencia de sostenibilidad corporativa y Bangladesh .
Al cargar los archivos, la aplicación almacenará las fuentes cargadas como nodos de documentos en el gráfico mediante los cargadores de documentos LangChain y los analizadores de YouTube. Una vez que se hayan cargado todos los archivos, debería ver algo similar a esto:


¡Todo lo que tenemos que hacer ahora es seleccionar el modelo a usar, hacer clic en Generar gráfico y dejar que la magia haga el resto por usted!
Si solo desea generar una selección de archivos, puede seleccionar los archivos primero (con la casilla de verificación en la primera columna de la tabla) y hacer clic en Generar gráfico .
⚠️ Tenga en cuenta que si desea utilizar un esquema de gráfico predefinido o propio, puede hacer clic en el ícono de configuración en la esquina superior derecha y seleccionar un esquema predefinido del menú desplegable, usar el suyo anotando las etiquetas y relaciones de los nodos, extraer el esquema existente de una base de datos Neo4j existente o copiar/pegar texto y pedirle al LLM que lo analice y elabore un esquema sugerido.
Mientras procesa sus archivos y crea su Gráfico de conocimiento, permítame resumir lo que sucede en segundo plano:
- El contenido se divide en fragmentos.
- Los fragmentos se almacenan en el gráfico y se conectan al nodo del documento y entre sí para obtener patrones RAG avanzados.
- Los fragmentos muy similares se conectan con una relación SIMILAR para formar un gráfico de K vecinos más cercanos.
- Las incrustaciones se calculan y almacenan en los fragmentos y en el índice vectorial.
- Utilizando llm-graph-transformer o diffbot-graph-transformer, se extraen entidades y relaciones del texto.
- Las entidades se almacenan en el gráfico y se conectan a los fragmentos de origen.
Explora tu gráfico de conocimiento
La información extraída de su documento se estructura en un formato gráfico, donde las entidades se convierten en nodos y las relaciones se convierten en aristas que conectan estos nodos. La belleza de usar Neo4j radica en su capacidad para almacenar y consultar de manera eficiente estas redes de datos complejas, lo que hace que el gráfico de conocimiento generado sea inmediatamente útil para una variedad de aplicaciones.
Antes de utilizar el agente RAG para hacer preguntas sobre nuestros datos, podemos seleccionar un documento (o varios) con la casilla de verificación y hacer clic en Mostrar gráfico . Esto mostrará las entidades creadas para los documentos que seleccionó; también puede mostrar el documento y el nodo de fragmentos en esa vista:
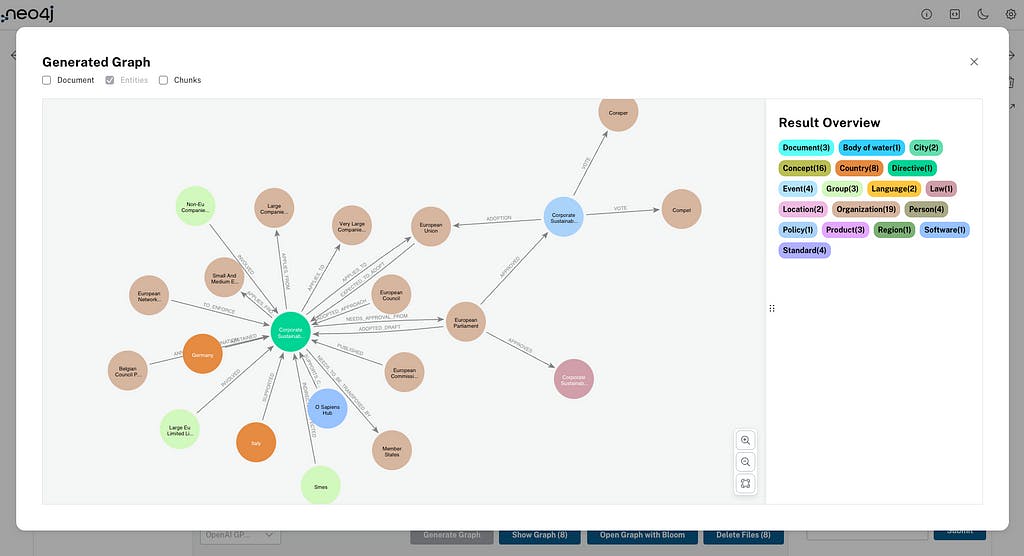
El botón Abrir gráfico con Bloom abrirá Neo4j Bloom para ayudarte a visualizar y navegar por el gráfico de conocimiento recién creado. La siguiente acción ( Eliminar archivos) elimina los documentos y fragmentos seleccionados del gráfico (y las entidades si lo seleccionas en las opciones).
Habla con tu conocimiento
Ahora viene la última parte: el agente RAG que puedes ver en el panel derecho.
El proceso de recuperación: ¿cómo funciona?
La siguiente imagen muestra una vista simplificada del proceso GraphRAG.


Cuando el usuario hace una pregunta, utilizamos el índice vectorial de Neo4j con una consulta de recuperación para encontrar los fragmentos más relevantes para la pregunta y sus entidades conectadas hasta una profundidad de 2 saltos. También resumimos el historial de chat y lo utilizamos como un elemento para enriquecer el contexto.
Las distintas entradas y fuentes (la pregunta, los resultados del vector, el historial de chat) se envían al modelo LLM seleccionado en un mensaje personalizado, en el que se solicita que se proporcione y se formatee una respuesta a la pregunta formulada en función de los elementos y el contexto proporcionados. Por supuesto, el mensaje tiene más magia, como el formato, la solicitud de citar fuentes, no especular si no se conoce una respuesta, etc. El mensaje completo y las instrucciones se pueden encontrar como FINAL_PROMPT en QA_integration.py .
Haga preguntas relacionadas con sus datos
En este ejemplo, cargué documentos internos sobre una empresa falsa llamada GraphACME (con sede en Europa), que produce y documenta toda su estrategia y productos de la cadena de suministro. También cargué un artículo de prensa y un video de YouTube que explican la nueva CSDDD, su impacto y regulación. Ahora podemos hacerle preguntas al chatbot sobre nuestro conocimiento interno (falso) de la empresa: preguntas sobre la ley CSDDD o incluso preguntas sobre ambas, como pedir la lista de productos que produce GraphACME, si se verán afectados por la regulación CSDDD y, de ser así, cómo afectará a la empresa.

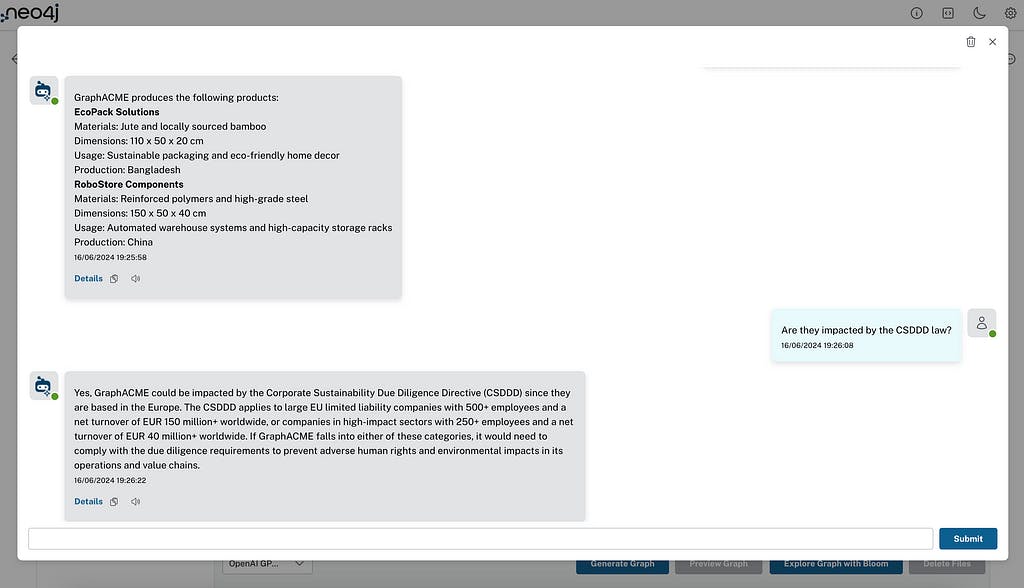
Funciones del chat
En el lado derecho de la pantalla de inicio, verá tres botones adjuntos a la ventana de chat:
- Cerrar cerrará la interfaz del chatbot.
- Borrar el historial de chat eliminará el historial de chat de la sesión actual.
- Maximizar la ventana abrirá la interfaz del chatbot en modo de pantalla completa.
En las respuestas del agente RAG, encontrará tres características después de la respuesta:
- Los detalles abrirán una ventana emergente con información de recuperación que muestra cómo el agente RAG recopiló y utilizó fuentes (documentos), fragmentos y entidades. También se incluye información sobre el modelo utilizado y el consumo de tokens.
- Copiar copiará el contenido de la respuesta al portapapeles.
- Text-to-Speech leerá el contenido de la respuesta en voz alta.


Resumen
Para profundizar en el LLM Knowledge Graph Builder, el repositorio de GitHub ofrece una gran cantidad de información, incluido el código fuente y la documentación. Además, nuestra documentación proporciona una guía detallada sobre cómo comenzar, y GenAI Ecosystem ofrece más información sobre las herramientas y aplicaciones más amplias disponibles.
¿Qué sigue? Capacidades de contribución y extensión
Su experiencia con LLM Knowledge Graph Builder es invaluable. Si encuentra errores, tiene sugerencias para nuevas funciones, desea contribuir o desea ver ciertas mejoras, la plataforma de la comunidad es el lugar perfecto para compartir sus ideas. Para aquellos expertos en codificación, contribuir directamente en GitHub puede ser una forma gratificante de ayudar a desarrollar el proyecto. Sus aportes y contribuciones no solo ayudan a mejorar la herramienta, sino que también fomentan una comunidad colaborativa e innovadora:
Recursos
Obtenga más información sobre los nuevos recursos para aplicaciones GenAI: Neo4j GraphRAG Ecosystem Tools . Estas herramientas de código abierto facilitan el inicio de las aplicaciones GenAI basadas en gráficos de conocimiento, que ayudan a mejorar la calidad y la explicabilidad de las respuestas y aceleran el desarrollo y la adopción de aplicaciones.
Video
Campo de golf
- Introducción a GraphRAG: herramientas del ecosistema de Neo4j
- GitHub – neo4j-labs/llm-graph-builder: construcción de gráficos con Neo4j a partir de datos no estructurados
- Neo4j LLM Knowledge Graph Builder: extracción de nodos y relaciones de texto no estructurado (PDF, YouTube, páginas web) – Neo4j Labs
- Ecosistema GenAI - Neo4j Labs
- Needle StarterKit 2.0: ¡Plantillas, Chatbot y más!








