
























O LLM Knowledge Graph Builder é unha das ferramentas do ecosistema GraphRAG de Neo4j que che permite transformar datos non estruturados en gráficos de coñecemento dinámicos. Está integrado cun chatbot de xeración aumentada por recuperación (RAG), que permite consultas en linguaxe natural e información explicable sobre os teus datos.
Que é o Neo4j LLM Knowledge Graph Builder?
O Neo4j LLM Knowledge Graph Builder é unha innovadora aplicación en liña para converter texto non estruturado nun gráfico de coñecemento sen código e sen Cypher, que ofrece unha experiencia máxica de texto a gráfico. Usa modelos de ML (LLM: OpenAI, Gemini, Diffbot) para transformar PDF, páxinas web e vídeos de YouTube nun gráfico de coñecemento de entidades e as súas relacións.
O front-end é unha aplicación React baseada no noso Needle Starter Kit , e o back-end é unha aplicación Python FastAPI. Usa o módulo llm-graph-transformer que Neo4j contribuíu a LangChain.
A aplicación ofrece unha experiencia perfecta, seguindo catro sinxelos pasos:
- Inxestión de datos: admite varias fontes de datos, incluíndo documentos PDF, páxinas de Wikipedia, vídeos de YouTube e moito máis.
- Recoñecemento de entidades: usa LLM para identificar e extraer entidades e relacións de texto non estruturado.
- Construción de gráficos: converte entidades e relacións recoñecidas nun formato gráfico, utilizando as capacidades de gráficos de Neo4j.
- Interface de usuario: ofrece unha interface web intuitiva para que os usuarios interactúen coa aplicación, facilitando a carga de fontes de datos, a visualización do gráfico xerado e a interacción cun axente RAG. Esta capacidade é particularmente emocionante xa que permite unha interacción intuitiva cos datos, como ter unha conversación co propio gráfico de coñecemento; non se requiren coñecementos técnicos.


Probámolo
Ofrecemos a aplicación no noso entorno aloxado en Neo4j sen necesidade de tarxetas de crédito e sen chaves LLM, sen friccións.
Alternativamente, para executalo localmente ou dentro do seu contorno, visite o repositorio público de GitHub e siga as instrucións paso a paso que trataremos nesta publicación.
Antes de abrir e usar o LLM Knowledge Graph Builder, imos crear unha nova base de datos Neo4j. Para iso, podemos usar unha base de datos AuraDB gratuíta seguindo estes pasos:
- Inicia sesión ou crea unha conta en https://console.neo4j.io .
- En Instancias, cree unha nova base de datos gratuíta AuraDB.
- Descarga o ficheiro de credenciais.
- Agarde ata que se execute a instancia.
Agora que temos a nosa base de datos Neo4j en execución e as nosas credenciais, podemos abrir o LLM Knowledge Graph Builder e facer clic en Conectar a Neo4j na esquina superior dereita.


Solta o ficheiro de credenciais descargado anteriormente no diálogo de conexión. Toda a información debe cubrirse automaticamente. Alternativamente, pode introducir todo manualmente.
Creación do gráfico de coñecemento
O proceso comeza coa inxestión dos teus datos non estruturados, que despois pasan polo LLM para identificar as entidades clave e as súas relacións.
Podes arrastrar e soltar PDF e outros ficheiros na primeira zona de entrada da esquerda. A segunda entrada permitirache copiar/pegar a ligazón a un vídeo de YouTube que queres usar, mentres que a terceira entrada leva unha ligazón á páxina de Wikipedia.
Para este exemplo, cargarei algúns PDF que teño sobre unha empresa da cadea de subministración chamada GraphACME, un artigo de prensa de Forbes e un vídeo de YouTube sobre a Directiva de Due Diligence de Sostibilidade Corporativa (CSDDD), así como dúas páxinas da Wikipedia: Directiva de Due Diligence de Sostibilidade Corporativa e Bangladesh .
Mentres carga os ficheiros, a aplicación almacenará as fontes cargadas como nodos de documentos no gráfico usando os cargadores de documentos LangChain e os analizadores de YouTube. Unha vez cargados todos os ficheiros, deberías ver algo semellante a isto:


Todo o que temos que facer agora é seleccionar o modelo a usar, facer clic en Xerar gráfico e deixar que a maxia faga o resto por ti.
Se só queres xerar unha selección de ficheiros, podes seleccionar primeiro os ficheiros (coa caixa de verificación da primeira columna da táboa) e facer clic en Xerar gráfico .
⚠️ Teña en conta que se quere utilizar un esquema gráfico predefinido ou o seu propio, pode facer clic na icona de configuración na esquina superior dereita e seleccionar un esquema predefinido no menú despregable, utilizar o seu propio escribindo as etiquetas e as relacións dos nodos, tire o esquema existente dunha base de datos Neo4j existente ou copie/pegue texto e solicite ao LLM que o analice e dea un esquema suxerido.
Mentres procesa os teus ficheiros e crea o teu Knowledge Graph, permíteme resumir o que está a suceder baixo o capó:
- O contido divídese en anacos.
- Os anacos almacénanse no gráfico e conéctanse ao nodo do documento e entre si para patróns RAG avanzados.
- Os anacos moi similares están conectados cunha relación SIMILAR para formar un gráfico K-Nearest Neighbors.
- As incorporacións calcúlanse e almacénanse nos fragmentos e no índice vectorial.
- Usando o llm-graph-transformer ou diffbot-graph-transformer, extráense entidades e relacións do texto.
- As entidades almacénanse no gráfico e conéctanse aos anacos orixinarios.
Explora o teu gráfico de coñecemento
A información extraída do documento estrutúrase nun formato gráfico, onde as entidades convértense en nós e as relacións convértense en bordos que conectan estes nodos. A beleza de usar Neo4j reside na súa capacidade para almacenar e consultar de forma eficiente estas complexas redes de datos, o que fai que o gráfico de coñecemento xerado sexa inmediatamente útil para unha variedade de aplicacións.
Antes de usar o axente RAG para facer preguntas sobre os nosos datos, podemos seleccionar un documento (ou moitos) coa caixa de verificación e facer clic en Mostrar gráfico . Isto mostrará as entidades creadas para o(s) documento(s) que seleccionou; tamén pode mostrar o documento e o nodo de anacos nesa vista:
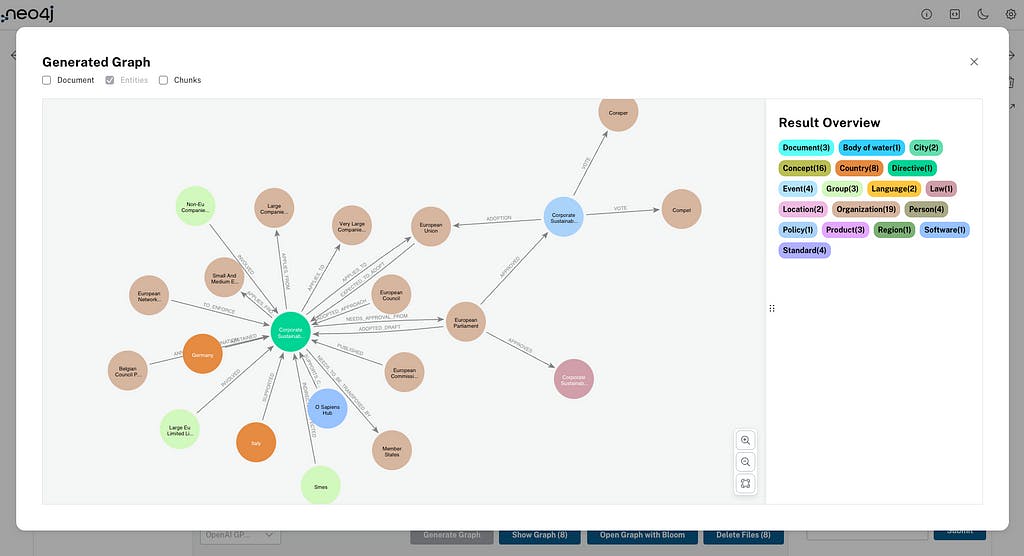
O botón Abrir gráfico con Bloom abrirá Neo4j Bloom para axudarche a visualizar e navegar polo teu gráfico de coñecemento recentemente creado. A seguinte acción - Eliminar ficheiros - elimina os documentos e anacos seleccionados do gráfico (e entidades se o seleccionas nas opcións).
Fale co teu coñecemento
Agora vén a última parte: o axente RAG que podes ver no panel dereito.
O proceso de recuperación: como funciona?
A imaxe de abaixo mostra unha vista simplificada do proceso GraphRAG.


Cando o usuario fai unha pregunta, utilizamos o índice vectorial Neo4j cunha consulta de recuperación para atopar os fragmentos máis relevantes para a pregunta e as súas entidades conectadas ata unha profundidade de 2 saltos. Tamén resumimos o historial de chat e usámolo como elemento para enriquecer o contexto.
As distintas entradas e fontes (a pregunta, os resultados do vector, o historial de chat) envíanse ao modelo de LLM seleccionado nun aviso personalizado, solicitando que proporcione e formatee unha resposta á pregunta feita en función dos elementos e do contexto proporcionados. Por suposto, o aviso ten máis maxia, como formatar, pedir que se citen fontes, non especular se non se coñece unha resposta, etc. A solicitude completa e as instrucións pódense atopar como FINAL_PROMPT en QA_integration.py .
Fai preguntas relacionadas cos teus datos
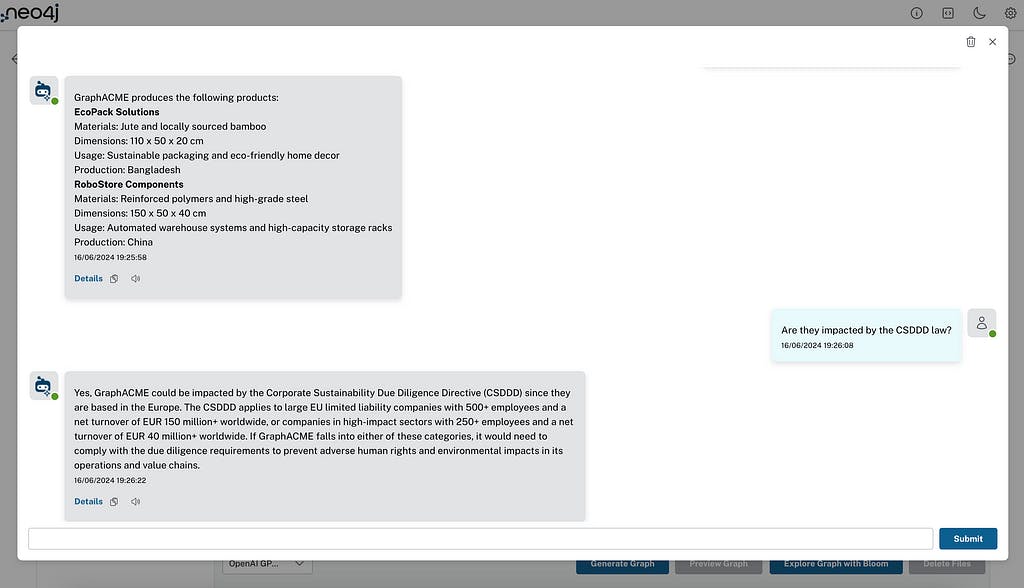
Neste exemplo, carguei documentos internos sobre unha empresa falsa chamada GraphACME (con sede en Europa), producindo e documentando toda a súa estratexia e produtos da cadea de subministración. Tamén carguei un artigo de prensa e un vídeo de YouTube explicando o novo CSDDD, o seu impacto e a normativa. Agora podemos facerlle preguntas ao chatbot sobre o noso coñecemento interno (falso) da empresa: preguntas sobre a lei CSDDD, ou incluso preguntas sobre ambas, como pedir a lista de produtos que produce GraphACME, se se verán afectados pola regulación CSDDD, e se é así, como afectará á empresa.

Funcións de chat
No lado dereito da pantalla de inicio, verás tres botóns anexos á xanela de chat:
- Pechar pechará a interface do chatbot.
- Borrar o historial de chat eliminará o historial de chat da sesión actual.
- A xanela de maximizar abrirá a interface do chatbot nun modo de pantalla completa.
Nas respostas do axente da RAG, atoparás tres funcións despois da resposta:
- Os detalles abrirán unha ventá emerxente de información de recuperación que mostra como o axente de RAG recompilou e utilizou fontes (documentos), anacos e entidades. Tamén se inclúe información sobre o modelo utilizado e o consumo de token.
- Copy copiará o contido da resposta no portapapeis.
- Text-to-Speech lerá o contido da resposta en voz alta.


Conclusión
Para mergullarse máis no LLM Knowledge Graph Builder, o repositorio de GitHub ofrece unha gran cantidade de información, incluíndo código fonte e documentación. Ademais, a nosa documentación ofrece orientacións detalladas para comezar, e GenAI Ecosystem ofrece máis información sobre as ferramentas e aplicacións máis amplas dispoñibles.
O que segue: capacidades de contribución e extensión
A túa experiencia co LLM Knowledge Graph Builder é inestimable. Se atopas erros, tes suxestións para novas funcións, queres contribuír ou desexas ver certas melloras, a plataforma da comunidade é o lugar perfecto para compartir as túas opinións. Para aqueles expertos na codificación, contribuír directamente en GitHub pode ser unha forma gratificante de axudar a desenvolver o proxecto. As túas achegas e contribucións non só axudan a mellorar a ferramenta senón que tamén fomentan unha comunidade colaborativa e innovadora:
Recursos
Máis información sobre novos recursos para aplicacións GenAI: Neo4j GraphRAG Ecosystem Tools . Estas ferramentas de código aberto facilitan comezar coas aplicacións GenAI baseadas en gráficos de coñecemento, que axudan a mellorar a calidade das respostas e a explicabilidade e acelerar o desenvolvemento e adopción de aplicacións.
Vídeo
Ligazóns
- Comeza a usar GraphRAG: ferramentas do ecosistema de Neo4j
- GitHub - neo4j-labs/llm-graph-builder: construción de gráficos Neo4j a partir de datos non estruturados
- Neo4j LLM Knowledge Graph Builder - Extrae nodos e relacións de texto non estruturado (PDF, YouTube, páxinas web) - Neo4j Labs
- Ecosistema GenAI - Neo4j Labs
- Needle StarterKit 2.0: modelos, chatbot e moito máis!








