
























LLM Knowledge Graph Builder ແມ່ນຫນຶ່ງໃນເຄື່ອງມືລະບົບນິເວດ GraphRAG ຂອງ Neo4j ທີ່ຊ່ວຍໃຫ້ທ່ານສາມາດປ່ຽນຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງໄປສູ່ກາຟຄວາມຮູ້ແບບເຄື່ອນໄຫວ. ມັນໄດ້ຖືກລວມເຂົ້າກັບ chatbot Retrieval-Augmented Generation (RAG), ເຮັດໃຫ້ການສອບຖາມພາສາທໍາມະຊາດແລະຄວາມເຂົ້າໃຈທີ່ອະທິບາຍໄດ້ໃນຂໍ້ມູນຂອງທ່ານ.
Neo4j LLM Knowledge Graph Builder ແມ່ນຫຍັງ?
Neo4j LLM Knowledge Graph Builder ເປັນຄໍາຮ້ອງສະຫມັກອອນໄລນ໌ທີ່ມີນະວັດກໍາສໍາລັບການປ່ຽນຂໍ້ຄວາມທີ່ບໍ່ມີໂຄງສ້າງເຂົ້າໄປໃນເສັ້ນສະແດງຄວາມຮູ້ທີ່ບໍ່ມີລະຫັດແລະບໍ່ມີ Cypher, ສະຫນອງປະສົບການການປ່ຽນຂໍ້ຄວາມທີ່ມະຫັດສະຈັນ. ມັນໃຊ້ແບບຈໍາລອງ ML (LLMs: OpenAI, Gemini, Diffbot) ເພື່ອຫັນປ່ຽນ PDFs, ຫນ້າເວັບ, ແລະວິດີໂອ YouTube ເຂົ້າໄປໃນຕາຕະລາງຄວາມຮູ້ຂອງຫນ່ວຍງານແລະຄວາມສໍາພັນຂອງພວກເຂົາ.
ສ່ວນດ້ານໜ້າແມ່ນແອັບພລິເຄຊັນ React ໂດຍອີງໃສ່ ຊຸດເຄື່ອງເລີ່ມເຂັມ ຂອງພວກເຮົາ, ແລະດ້ານຫຼັງແມ່ນແອັບພລິເຄຊັນ Python FastAPI. ມັນໃຊ້ ໂມດູນ llm-graph-transformer ທີ່ Neo4j ປະກອບສ່ວນເຂົ້າໃນ LangChain.
ຄໍາຮ້ອງສະຫມັກສະຫນອງປະສົບການ seamless, ປະຕິບັດຕາມສີ່ຂັ້ນຕອນງ່າຍດາຍ:
- ການປ້ອນຂໍ້ມູນ — ສະຫນັບສະຫນູນແຫຼ່ງຂໍ້ມູນຕ່າງໆ, ລວມທັງເອກະສານ PDF, ຫນ້າ Wikipedia, ວິດີໂອ YouTube, ແລະອື່ນໆອີກ.
- Entity Recognition - ໃຊ້ LLMs ເພື່ອກໍານົດແລະສະກັດຫນ່ວຍງານແລະຄວາມສໍາພັນອອກຈາກຂໍ້ຄວາມທີ່ບໍ່ມີໂຄງສ້າງ.
- ການສ້າງກຣາບ - ແປງຫົວໜ່ວຍທີ່ຮັບຮູ້ ແລະຄວາມສໍາພັນເປັນຮູບແບບກຣາຟ, ໂດຍໃຊ້ຄວາມສາມາດຂອງກາຟ Neo4j.
- ການໂຕ້ຕອບຜູ້ໃຊ້ - ສະຫນອງການໂຕ້ຕອບເວັບໄຊຕ໌ intuitive ສໍາລັບຜູ້ໃຊ້ເພື່ອພົວພັນກັບຄໍາຮ້ອງສະຫມັກ, ອໍານວຍຄວາມສະດວກໃນການອັບໂຫລດແຫຼ່ງຂໍ້ມູນ, ການເບິ່ງເຫັນຂອງກາຟທີ່ສ້າງຂຶ້ນ, ແລະການພົວພັນກັບຕົວແທນ RAG. ຄວາມສາມາດນີ້ແມ່ນຫນ້າຕື່ນເຕັ້ນເປັນພິເສດຍ້ອນວ່າມັນອະນຸຍາດໃຫ້ມີການໂຕ້ຕອບ intuitive ກັບຂໍ້ມູນ, ຄ້າຍຄືກັບການສົນທະນາກັບກາຟຄວາມຮູ້ຕົວມັນເອງ - ບໍ່ຈໍາເປັນຕ້ອງມີຄວາມຮູ້ດ້ານວິຊາການ.


ໃຫ້ລອງມັນອອກ
ພວກເຮົາສະຫນອງຄໍາຮ້ອງສະຫມັກໃນ ສະພາບແວດລ້ອມ Neo4j-hosted ຂອງພວກເຮົາທີ່ບໍ່ມີບັດເຄຣດິດທີ່ຕ້ອງການແລະບໍ່ມີກະແຈ LLM — ບໍ່ມີ friction.
ອີກທາງເລືອກ, ເພື່ອດໍາເນີນການມັນຢູ່ໃນທ້ອງຖິ່ນຫຼືພາຍໃນສະພາບແວດລ້ອມຂອງທ່ານ, ໄປຢ້ຽມຢາມ GitHub repo ສາທາລະນະແລະປະຕິບັດຕາມຄໍາແນະນໍາຂັ້ນຕອນໂດຍຂັ້ນຕອນທີ່ພວກເຮົາຈະກວມເອົາໃນການຕອບນີ້.
ກ່ອນທີ່ພວກເຮົາຈະເປີດແລະນໍາໃຊ້ LLM Knowledge Graph Builder, ໃຫ້ສ້າງຖານຂໍ້ມູນ Neo4j ໃຫມ່. ສໍາລັບການນັ້ນ, ພວກເຮົາສາມາດນໍາໃຊ້ຖານຂໍ້ມູນ AuraDB ຟຣີໂດຍປະຕິບັດຕາມຂັ້ນຕອນເຫຼົ່ານີ້:
- ເຂົ້າສູ່ລະບົບ ຫຼືສ້າງບັນຊີຢູ່ https://console.neo4j.io .
- ພາຍໃຕ້ຕົວຢ່າງ, ສ້າງຖານຂໍ້ມູນ AuraDB ຟຣີໃຫມ່.
- ດາວໂຫລດໄຟລ໌ຂໍ້ມູນປະຈໍາຕົວ.
- ລໍຖ້າຈົນກ່ວາຕົວຢ່າງຈະເຮັດວຽກ.
ໃນປັດຈຸບັນທີ່ພວກເຮົາມີຖານຂໍ້ມູນ Neo4j ຂອງພວກເຮົາແລ່ນແລະຂໍ້ມູນປະຈໍາຕົວຂອງພວກເຮົາ, ພວກເຮົາສາມາດເປີດ LLM Knowledge Graph Builder, ແລະຄລິກໃສ່ ການເຊື່ອມຕໍ່ກັບ Neo4j ໃນມຸມຂວາເທິງ.


ວາງໄຟລ໌ຂໍ້ມູນປະຈໍາຕົວທີ່ດາວໂຫລດມາໃນກ່ອງໂຕ້ຕອບການເຊື່ອມຕໍ່. ຂໍ້ມູນທັງຫມົດຄວນຈະຖືກຕື່ມໃສ່ໂດຍອັດຕະໂນມັດ. ອີກທາງເລືອກ, ທ່ານສາມາດໃສ່ທຸກສິ່ງທຸກຢ່າງດ້ວຍຕົນເອງ.
ການສ້າງ Knowledge Graph
ຂະບວນການເລີ່ມຕົ້ນດ້ວຍການເອົາຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງຂອງທ່ານ, ເຊິ່ງຫຼັງຈາກນັ້ນໄດ້ຜ່ານ LLM ເພື່ອກໍານົດຫນ່ວຍງານທີ່ສໍາຄັນແລະຄວາມສໍາພັນຂອງພວກເຂົາ.
ທ່ານສາມາດ drag ແລະລົງ PDF ແລະໄຟລ໌ອື່ນໆເຂົ້າໄປໃນເຂດການປ້ອນຂໍ້ມູນທໍາອິດຢູ່ເບື້ອງຊ້າຍ. ການປ້ອນຂໍ້ມູນທີສອງຈະເຮັດໃຫ້ເຈົ້າຄັດລອກ/ວາງລິ້ງໄປຫາວິດີໂອ YouTube ທີ່ເຈົ້າຕ້ອງການໃຊ້, ໃນຂະນະທີ່ການປ້ອນຂໍ້ມູນທີສາມໃຊ້ລິ້ງໜ້າ Wikipedia.
ຕົວຢ່າງນີ້, ຂ້ອຍຈະໂຫລດ PDF ຈໍານວນຫນ້ອຍທີ່ຂ້ອຍມີກ່ຽວກັບບໍລິສັດລະບົບຕ່ອງໂສ້ການສະຫນອງທີ່ເອີ້ນວ່າ GraphACME, ບົດຄວາມຂ່າວຈາກ Forbes , ແລະ ວິດີໂອ YouTube ກ່ຽວກັບ Corporate Sustainability Due Diligence Directive (CSDDD), ເຊັ່ນດຽວກັນກັບສອງຫນ້າຈາກ Wikipedia: ຄໍາແນະນໍາຂອງບໍລິສັດຄວາມຍືນຍົງເນື່ອງຈາກຄວາມພາກພຽນ ແລະ ບັງກະລາເທດ .
ໃນຂະນະທີ່ການອັບໂຫລດໄຟລ໌, ແອັບພລິເຄຊັນຈະເກັບແຫຼ່ງທີ່ອັບໂຫລດໄວ້ເປັນຈຸດເອກະສານໃນກາຟໂດຍໃຊ້ LangChain Document Loaders ແລະຕົວແຍກວິເຄາະ YouTube. ເມື່ອໄຟລ໌ທັງຫມົດໄດ້ຖືກອັບໂຫລດ, ທ່ານຄວນເຫັນບາງສິ່ງບາງຢ່າງທີ່ຄ້າຍຄືກັນນີ້:


ທັງໝົດທີ່ພວກເຮົາຕ້ອງເຮັດຕອນນີ້ແມ່ນເລືອກຕົວແບບເພື່ອໃຊ້, ຄລິກ ສ້າງກຣາບ , ແລະປ່ອຍໃຫ້ເວດມົນເຮັດສ່ວນທີ່ເຫຼືອໃຫ້ກັບເຈົ້າ!
ຖ້າທ່ານຕ້ອງການສ້າງການເລືອກໄຟລ໌, ທ່ານສາມາດເລືອກໄຟລ໌ທໍາອິດ (ໂດຍມີກ່ອງກາເຄື່ອງຫມາຍຢູ່ໃນຖັນທໍາອິດຂອງຕາຕະລາງ) ແລະຄລິກ ສ້າງຕາຕະລາງ .
⚠️ ສັງເກດວ່າຖ້າທ່ານຕ້ອງການໃຊ້ແຜນຜັງທີ່ກໍານົດໄວ້ລ່ວງຫນ້າຫຼືຮູບແບບກາຟຂອງທ່ານເອງ, ທ່ານສາມາດຄລິກໃສ່ໄອຄອນການຕັ້ງຄ່າໃນມຸມຂວາເທິງແລະເລືອກ schema ທີ່ກໍານົດໄວ້ກ່ອນຈາກເມນູເລື່ອນລົງ, ໃຊ້ຂອງທ່ານເອງໂດຍການຂຽນລົງ. ປ້າຍຊື່ແລະການພົວພັນ, ດຶງ schema ທີ່ມີຢູ່ຈາກຖານຂໍ້ມູນ Neo4j ທີ່ມີຢູ່ແລ້ວ, ຫຼືຄັດລອກ / ວາງຂໍ້ຄວາມແລະຂໍໃຫ້ LLM ວິເຄາະມັນແລະອອກມາດ້ວຍ schema ທີ່ແນະນໍາ.
ໃນຂະນະທີ່ມັນກໍາລັງປະມວນຜົນໄຟລ໌ຂອງເຈົ້າ ແລະສ້າງ Knowledge Graph ຂອງເຈົ້າ, ໃຫ້ຂ້ອຍສະຫຼຸບສິ່ງທີ່ເກີດຂຶ້ນພາຍໃຕ້ຫົວ:
- ເນື້ອໃນແມ່ນແບ່ງອອກເປັນຕ່ອນ.
- Chunks ຖືກເກັບໄວ້ໃນກາຟແລະເຊື່ອມຕໍ່ກັບ node ເອກະສານແລະເຊິ່ງກັນແລະກັນສໍາລັບຮູບແບບ RAG ຂັ້ນສູງ.
- chunks ທີ່ຄ້າຍຄືກັນສູງແມ່ນເຊື່ອມຕໍ່ກັບຄວາມສໍາພັນ SIMILAR ເພື່ອປະກອບເປັນ K-Nearest Neighbors graph.
- ການຝັງຕົວໄດ້ຖືກຄິດໄລ່ແລະເກັບໄວ້ໃນ chunks ແລະ vector index.
- ການນໍາໃຊ້ llm-graph-transformer ຫຼື diffbot-graph-transformer, ຫນ່ວຍງານແລະຄວາມສໍາພັນແມ່ນຖືກສະກັດອອກຈາກຂໍ້ຄວາມ.
- ຫນ່ວຍງານຖືກເກັບໄວ້ໃນກາຟແລະເຊື່ອມຕໍ່ກັບ chunks ຕົ້ນກໍາເນີດ.
ສຳຫຼວດ Knowledge Graph ຂອງທ່ານ
ຂໍ້ມູນທີ່ຖືກແຍກອອກຈາກເອກະສານຂອງທ່ານແມ່ນມີໂຄງສ້າງເປັນຮູບແບບກຣາຟ, ບ່ອນທີ່ຫົວຫນ່ວຍກາຍເປັນ nodes, ແລະຄວາມສໍາພັນໄດ້ກາຍເປັນຂອບການເຊື່ອມຕໍ່ຂໍ້ເຫຼົ່ານີ້. ຄວາມງາມຂອງການນໍາໃຊ້ Neo4j ແມ່ນຢູ່ໃນຄວາມສາມາດໃນການເກັບຮັກສາແລະສອບຖາມເຄືອຂ່າຍຂໍ້ມູນທີ່ສັບສົນເຫຼົ່ານີ້ຢ່າງມີປະສິດທິພາບ, ເຮັດໃຫ້ເສັ້ນສະແດງຄວາມຮູ້ທີ່ສ້າງຂຶ້ນທັນທີເປັນປະໂຫຍດສໍາລັບຫຼາຍໆຄໍາຮ້ອງສະຫມັກ.
ກ່ອນທີ່ພວກເຮົາຈະໃຊ້ຕົວແທນ RAG ເພື່ອຖາມຄໍາຖາມກ່ຽວກັບຂໍ້ມູນຂອງພວກເຮົາ, ພວກເຮົາສາມາດເລືອກເອກະສານຫນຶ່ງ (ຫຼືຫຼາຍ) ດ້ວຍກ່ອງກາເຄື່ອງຫມາຍແລະຄລິກ Show Graph . ນີ້ຈະສະແດງຫນ່ວຍງານທີ່ສ້າງຂຶ້ນສໍາລັບເອກະສານທີ່ທ່ານເລືອກ; ນອກນັ້ນທ່ານຍັງສາມາດສະແດງເອກະສານແລະ chunks node ໃນມຸມເບິ່ງນັ້ນ:
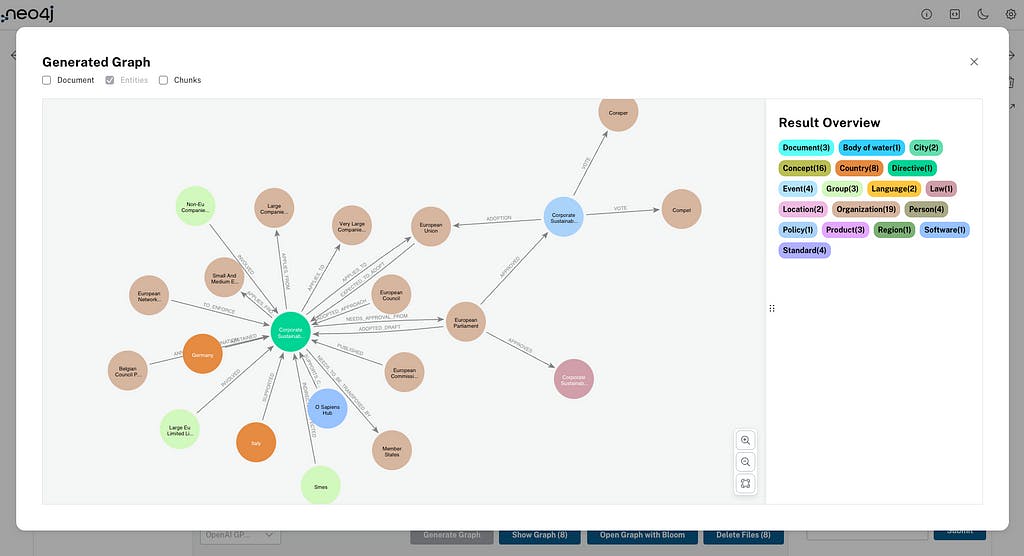
ປຸ່ມ Open Graph with Bloom ຈະເປີດ Neo4j Bloom ເພື່ອຊ່ວຍໃຫ້ທ່ານເຫັນພາບ ແລະນຳທາງກາຟຄວາມຮູ້ທີ່ສ້າງຂຶ້ນໃໝ່ຂອງເຈົ້າ. ການດໍາເນີນການຕໍ່ໄປ — ລຶບໄຟລ໌ — ລຶບເອກະສານທີ່ເລືອກ ແລະ chunks ຈາກກາຟ (ແລະຫນ່ວຍງານຖ້າຫາກວ່າທ່ານເລືອກມັນຢູ່ໃນທາງເລືອກ).
ສົນທະນາກັບຄວາມຮູ້ຂອງເຈົ້າ
ຕອນນີ້ມາຮອດສ່ວນສຸດທ້າຍ: ຕົວແທນ RAG ທີ່ເຈົ້າສາມາດເຫັນໄດ້ໃນກະດານທີ່ຖືກຕ້ອງ.
ຂະບວນການດຶງຂໍ້ມູນ - ມັນເຮັດວຽກແນວໃດ?
ຮູບພາບຂ້າງລຸ່ມນີ້ສະແດງໃຫ້ເຫັນທັດສະນະທີ່ງ່າຍດາຍຂອງຂະບວນການ GraphRAG.


ເມື່ອຜູ້ໃຊ້ຖາມຄໍາຖາມ, ພວກເຮົາໃຊ້ Neo4j vector index ດ້ວຍການສອບຖາມຂໍ້ມູນເພື່ອຄົ້ນຫາ chunks ທີ່ກ່ຽວຂ້ອງທີ່ສຸດສໍາລັບຄໍາຖາມແລະຫນ່ວຍງານທີ່ເຊື່ອມຕໍ່ຂອງພວກເຂົາເຖິງຄວາມເລິກຂອງ 2 hops. ພວກເຮົາຍັງສະຫຼຸບປະຫວັດການສົນທະນາ ແລະໃຊ້ມັນເປັນອົງປະກອບເພື່ອເສີມສ້າງບໍລິບົດ.
ວັດສະດຸປ້ອນແລະແຫຼ່ງຂໍ້ມູນຕ່າງໆ (ຄໍາຖາມ, ຜົນໄດ້ຮັບ vector, ປະຫວັດການສົນທະນາ) ທັງຫມົດຖືກສົ່ງໄປຫາຕົວແບບ LLM ທີ່ເລືອກໃນການກະຕຸ້ນເຕືອນທີ່ກໍາຫນົດເອງ, ຂໍໃຫ້ສະຫນອງແລະຈັດຮູບແບບຄໍາຕອບຕໍ່ຄໍາຖາມທີ່ຖາມໂດຍອີງໃສ່ອົງປະກອບແລະສະພາບການທີ່ສະຫນອງໃຫ້. ແນ່ນອນ, ການກະຕຸ້ນເຕືອນມີ magic ຫຼາຍ, ເຊັ່ນ: ການຈັດຮູບແບບ, ຂໍໃຫ້ອ້າງເຖິງແຫຼ່ງຂໍ້ມູນ, ເພື່ອບໍ່ໃຫ້ຄາດເດົາວ່າຄໍາຕອບແມ່ນບໍ່ຮູ້, ແລະອື່ນໆ. ການເຕືອນແລະຄໍາແນະນໍາຢ່າງເຕັມທີ່ສາມາດພົບໄດ້ເປັນ FINAL_PROMPT ໃນ QA_integration.py .
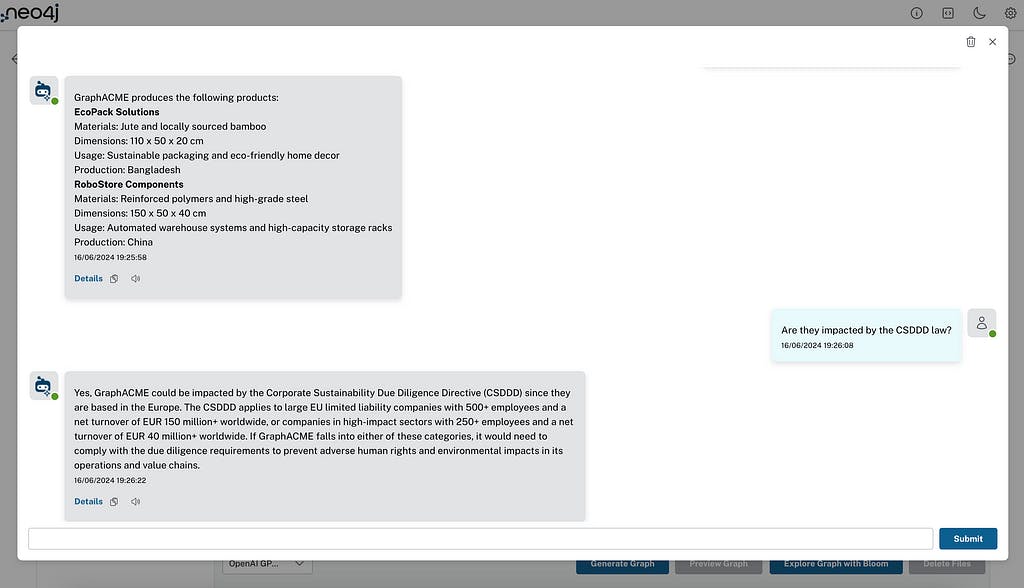
ຖາມຄໍາຖາມທີ່ກ່ຽວຂ້ອງກັບຂໍ້ມູນຂອງທ່ານ
ໃນຕົວຢ່າງນີ້, ຂ້າພະເຈົ້າໄດ້ໂຫລດເອກະສານພາຍໃນກ່ຽວກັບບໍລິສັດປອມທີ່ມີຊື່ວ່າ GraphACME (ຢູ່ໃນເອີຣົບ), ການຜະລິດແລະເອກະສານຍຸດທະສາດຕ່ອງໂສ້ການສະຫນອງແລະຜະລິດຕະພັນທັງຫມົດຂອງພວກເຂົາ. ຂ້ອຍຍັງໄດ້ໂຫລດບົດຄວາມຂ່າວແລະວິດີໂອ YouTube ທີ່ອະທິບາຍ CSDDD ໃຫມ່, ຜົນກະທົບຂອງມັນ, ແລະກົດລະບຽບ. ຕອນນີ້ພວກເຮົາສາມາດຖາມຄໍາຖາມ chatbot ກ່ຽວກັບຄວາມຮູ້ຂອງບໍລິສັດພາຍໃນ (ປອມ) ຂອງພວກເຮົາ - ຄໍາຖາມກ່ຽວກັບກົດຫມາຍ CSDDD, ຫຼືແມ້ກະທັ້ງຄໍາຖາມໃນທົ່ວທັງສອງ, ເຊັ່ນ: ການຮ້ອງຂໍບັນຊີລາຍຊື່ຂອງຜະລິດຕະພັນ GraphACME ຜະລິດ, ຖ້າພວກເຂົາໄດ້ຮັບຜົນກະທົບຈາກກົດລະບຽບ CSDDD, ແລະ. ຖ້າເປັນດັ່ງນັ້ນ, ມັນຈະສົ່ງຜົນກະທົບຕໍ່ບໍລິສັດແນວໃດ.

ຄຸນສົມບັດການສົນທະນາ
ຢູ່ເບື້ອງຂວາຂອງໜ້າຈໍຫຼັກ, ທ່ານຈະສັງເກດເຫັນສາມປຸ່ມທີ່ຕິດຢູ່ກັບໜ້າຕ່າງສົນທະນາ:
- Close ຈະປິດການໂຕ້ຕອບ chatbot.
- ລຶບປະຫວັດການສົນທະນາ ຈະລຶບປະຫວັດການສົນທະນາຂອງເຊດຊັນປັດຈຸບັນ.
- Maximize window ຈະເປີດການໂຕ້ຕອບ chatbot ໃນໂໝດເຕັມຈໍ.
ໃນຄໍາຕອບຂອງຕົວແທນ RAG, ທ່ານຈະພົບເຫັນສາມລັກສະນະຫຼັງຈາກການຕອບສະຫນອງ:
- ລາຍລະອຽດ ຈະເປີດຂໍ້ມູນການດຶງຂໍ້ມູນທີ່ສະແດງໃຫ້ເຫັນວ່າຕົວແທນ RAG ເກັບກໍາແລະນໍາໃຊ້ແຫຼ່ງ (ເອກະສານ) chunks, ແລະຫນ່ວຍງານ. ຂໍ້ມູນກ່ຽວກັບຮູບແບບການນໍາໃຊ້ແລະການບໍລິໂພກ token ແມ່ນລວມ.
- ການຄັດລອກ ຈະຄັດລອກເນື້ອໃນຂອງການຕອບສະຫນອງກັບ clipboard.
- Text-to-Speech ຈະອ່ານເນື້ອໃນການຕອບຮັບດັງໆ.


ສະຫຼຸບ
ເພື່ອລົງເລິກເຂົ້າໄປໃນ LLM Knowledge Graph Builder, GitHub Repository ສະຫນອງຂໍ້ມູນຈໍານວນຫລາຍ, ລວມທັງລະຫັດແຫຼ່ງແລະເອກະສານ. ນອກຈາກນັ້ນ, ເອກະສານ ຂອງພວກເຮົາໃຫ້ຄໍາແນະນໍາຢ່າງລະອຽດກ່ຽວກັບການເລີ່ມຕົ້ນ, ແລະ ລະບົບນິເວດ GenAI ສະເຫນີຄວາມເຂົ້າໃຈຕື່ມອີກກ່ຽວກັບເຄື່ອງມືແລະຄໍາຮ້ອງສະຫມັກທີ່ກວ້າງຂວາງ.
ແມ່ນຫຍັງຕໍ່ໄປ — ການປະກອບສ່ວນ ແລະຄວາມສາມາດຂະຫຍາຍ
ປະສົບການຂອງທ່ານກັບ LLM Knowledge Graph Builder ແມ່ນບໍ່ມີຄ່າ. ຖ້າຫາກທ່ານພົບຂໍ້ບົກພ່ອງ, ມີຄໍາແນະນໍາສໍາລັບຄຸນນະສົມບັດໃຫມ່, ຕ້ອງການທີ່ຈະປະກອບສ່ວນ, ຫຼືຕ້ອງການທີ່ຈະເບິ່ງການປັບປຸງບາງຢ່າງ, ເວທີຊຸມຊົນແມ່ນບ່ອນທີ່ດີເລີດທີ່ຈະແບ່ງປັນຄວາມຄິດຂອງທ່ານ. ສໍາລັບຜູ້ທີ່ມີຄວາມຊໍານານໃນການຂຽນລະຫັດ, ການປະກອບສ່ວນໂດຍກົງໃນ GitHub ສາມາດເປັນວິທີທີ່ດີທີ່ຈະຊ່ວຍພັດທະນາໂຄງການ. ການປ້ອນຂໍ້ມູນ ແລະ ການປະກອບສ່ວນຂອງທ່ານບໍ່ພຽງແຕ່ຊ່ວຍປັບປຸງເຄື່ອງມືເທົ່ານັ້ນ ແຕ່ຍັງສົ່ງເສີມຊຸມຊົນທີ່ມີການຮ່ວມມື ແລະ ນະວັດຕະກໍາ:
ຊັບພະຍາກອນ
ສຶກສາເພີ່ມເຕີມກ່ຽວກັບຊັບພະຍາກອນໃໝ່ສຳລັບແອັບພລິເຄຊັນ GenAI: Neo4j GraphRAG Ecosystem Tools . ເຄື່ອງມືແຫຼ່ງເປີດເຫຼົ່ານີ້ເຮັດໃຫ້ມັນງ່າຍທີ່ຈະເລີ່ມຕົ້ນດ້ວຍຄໍາຮ້ອງສະຫມັກ GenAI ພື້ນຖານທີ່ມີເສັ້ນສະແດງຄວາມຮູ້, ເຊິ່ງຊ່ວຍປັບປຸງຄຸນນະພາບການຕອບສະຫນອງແລະການອະທິບາຍແລະເລັ່ງການພັດທະນາແລະການຮັບຮອງເອົາ app.
ວິດີໂອ
ລິ້ງຄ໌
- ເລີ່ມຕົ້ນດ້ວຍ GraphRAG: ເຄື່ອງມືລະບົບນິເວດຂອງ Neo4j
- GitHub – neo4j-labs/llm-graph-builder: ການສ້າງກຣາຟ Neo4j ຈາກຂໍ້ມູນທີ່ບໍ່ມີໂຄງສ້າງ
- Neo4j LLM Knowledge Graph Builder – Extract nodes and Relationships from Unstructured Text (PDF, YouTube, Webpages) – Neo4j Labs
- ລະບົບນິເວດ GenAI – Neo4j Labs
- Needle StarterKit 2.0: ແມ່ແບບ, Chatbot, ແລະອື່ນໆອີກ!








