

























FIFO arabelleği, birçok kullanım durumu için yaygın olarak ihtiyaç duyulan bir veri yapısıdır. Öğeler ara belleğe konulur ve yerleştirildikleri sıraya göre alınır. Bu, Kuyruk ile benzer işlevselliğe sahiptir. Kuyruk ve Tampon arasındaki fark, ara belleğe eklenen verilerin hepsinin aynı veri türünde olmasıdır. Ayrıca isteğe bağlı miktarda veri eklenebilir ve alma miktarı da isteğe bağlıdır.
Aynı türden isteğe bağlı sayıda öğeyi koymak ve almak istediğiniz kullanım durumları nelerdir? Bilgi işlem dışındaki alanlara yönelmek: Banka hesaplarını düşünün: Para farklı miktarlarda konur ve ihtiyaç duyulan miktarlarda alınır. Aynı şey çiftlikteki tahıl depolama için de geçerlidir. Ama bunu bankalar ve tahıl ambarları yapar. BT'de bize kalan, çok hızlı ulaşan ancak duyulabilmesi için belirli bir hızda daha yavaş gitmesi gereken Ses Verileridir. Günümüzün suçlusu, etkileşimli makine/insan iletişimini kolaylaştıran Metin Okuma motorlarıdır. Makine, insanın duyabileceği belirli bir hızda insana gönderilmek üzere Ses baytlarına dönüştürdüğü metni (muhtemelen bir AI motorundan) alır. Beklendiği gibi, makine hızlı bir klipte ses baytları üretiyor ve bu baytların, insana iletimi çok daha yavaş bir hızda tutabilmek için arabelleğe alınması gerekiyor. Bir benzetme yerel benzin istasyonunuzdur. Konuşmaya Metin, büyük miktarda benzini hızlı bir şekilde pompalayan ve benzin istasyonunun içindeki benzin tanklarını dolduran benzin tankeridir. Bunlar daha sonra müşterinin arabalarına veya diğer araçlarına çok daha yavaş bir hızda teslim edilir.
Özetle, metnin konuşmaya (ses) dönüşümü çok daha hızlı gerçekleşebilir. Arabelleği doldurmak için metinden konuşmaya (tts) ses alan bir Ses Arabelleğine ihtiyaç vardır. Bu tampon daha sonra insan konuşması hızında boşaltılır ve insan tarafından anlaşılır hale gelir.
Ses verileri: Veriler, bir ses sinyalinin düzenli aralıklarla (örnekleme hızı olarak adlandırılır) değerlerini temsil eden bir dizi sayıdan oluşur. Ayrıca birden fazla ses sinyalinden oluşan ve birden fazla değer dizisiyle sonuçlanan kanal kavramı da vardır.
Bu makalenin amacı doğrultusunda giriş tarafında yalnızca bir kanalı ve çıkış tarafında bir kanalı ele alacağız.
Tasarım:
Gereksinimler şunlardır: ses sinyali değerlerinin sıralı bir dizisi olan isteğe bağlı sayıda ses veri çerçevesine (bir çerçeve, bir ses veri noktasını temsil eden sayıdır) girebilmek. Çıkış tarafında bu karelerin isteğe bağlı bir miktarını almak mümkün. Elbette, sınırlı arabellek boyutu (girişte arabellek dolu koşullara neden olur), mevcut ses verisi olmaması (çıkış tarafında arabellek boş) gibi sınırlamaların üstesinden gelmek için kullanışlı özellikler eklememiz gerekir. Diğer kolaylık özellikleri, arabellek alımında mevcut olandan daha fazla ses verisi talep edilmesi durumunda ses verilerinin sıfır doldurulmasını içerecektir.
Uygulama:
Aşağıda Python'da böyle bir tamponun uygulanması açıklanmaktadır:
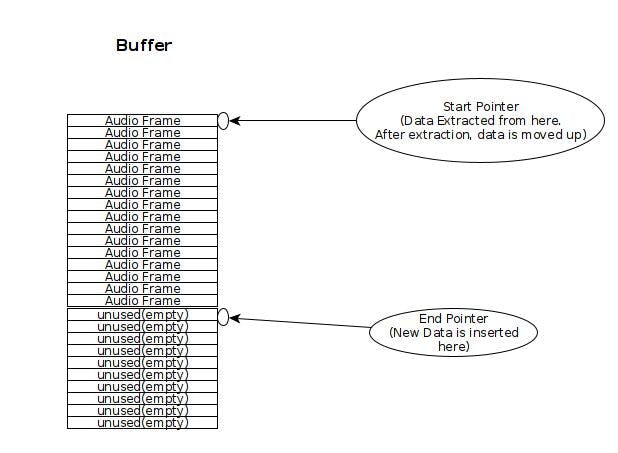
Gelen ses baytları Arabellekte saklanır. Tamponun, arabelleğin ne kadar dolu olduğunu gösteren bir 'alt' işaretçisi vardır. Ayrıca, yeni verilerin iletilebileceği arabelleğin başlangıcı olan bir 'başlangıç işaretçisi' de vardır. Başlatma işaretçisi arabelleğin başlangıcına sabitlenir. Alttaki işaretçi 'dinamiktir' ve 'yukarı ve aşağı' gider: veri çıkarıldığında yukarı ve veri eklendiğinde 'aşağı'. Veriler her zaman arabelleğin en üstüne (başlangıç işaretçisi) eklenir, bu da arabellekteki mevcut verilerin 'aşağıya' itilmesiyle sonuçlanır, böylece alt işaretçinin değeri artar.
Arabellek boş durumu, alt işaretçi başlangıç işaretçisine eşit olduğunda ortaya çıkar. Tampon dolu durumu, alt işaretçi arabelleğin uzunluğuna eşit olduğunda ortaya çıkar.
Tamponun dolu olduğu koşulları ele almak için 'zarif başarısızlıkları' da dahil edebiliriz.
Arabellek dolduğunda ve verilerin eklenmesi gerektiğinde bir İstisna oluşturun. Arabellek boş olduğunda (arabellekte mevcut olandan daha fazla verinin istendiği durum dahil) eksik veriler için 'sıfır' döndürün. Bu, hiçbir kelime söylenmediğinde 'sessizlik'in ses eşdeğeridir.
Bu tamponun diyagramı şöyledir:

Kodlama: (Sorumluluk reddi: Aşağıdaki kodu oluşturmak için hiçbir yapay zeka kullanılmamıştır. Tüm suçlamalar (övgü daha iyidir) Yazara aittir..)
Nesneye Dayalı ilkeler izlenerek kod bir sınıf/nesne olarak yazılır ve kullanımı kolaydır. Kodun tamamı şöyledir:
import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}')Çözüm:
Ses arabelleğe alma, çok sayıda ses işleme uygulaması nedeniyle artık çok önemli ve daha da önemli. Yukarıda sunulan ses arabellek algoritması kullanışlı bir python sınıfıdır.








