

























Um buffer FIFO é uma estrutura de dados comumente necessária para muitos casos de uso. Os itens são colocados no buffer e recuperados na ordem em que foram colocados. Esta é uma funcionalidade semelhante a uma Fila. A diferença entre uma Fila e um Buffer é que no buffer os dados inseridos são todos do mesmo tipo. Além disso, uma quantidade arbitrária de dados pode ser inserida e a quantidade de recuperação também é arbitrária.
Quais são os casos de uso em que você deseja colocar e recuperar itens numéricos arbitrários do mesmo tipo? Divergindo para outros campos que não o processamento de dados: Pense nas contas bancárias: O dinheiro é colocado em quantidades diferentes e retirado em quantidades conforme necessário.. O mesmo se aplica ao armazenamento de cereais numa quinta.. Mas os bancos e os celeiros fazem isto. O que nos resta em TI são os Dados de Áudio, que chegam muito rápido, mas precisam partir em uma velocidade específica mais lenta para que possam ser ouvidos. O culpado de hoje são os motores Text to Speech que facilitam a comunicação interativa entre máquina e humano. A máquina obtém texto (provavelmente de um mecanismo de IA) que converte em bytes de áudio para serem enviados ao ser humano em uma velocidade específica que o ser humano pode ouvir. Como esperado, a máquina gera bytes de áudio em um clipe rápido que precisa ser armazenado em buffer para poder manter a entrega ao ser humano em uma taxa muito mais lenta. Uma analogia é o seu posto de gasolina local. O texto para fala é o caminhão-tanque de gasolina que bombeia muita gasolina em ritmo acelerado, enchendo os tanques nas entranhas do posto de gasolina. Estes são então entregues a um ritmo muito mais lento nos carros ou outros veículos do cliente.
Em resumo, a conversão de texto em fala (áudio) pode ocorrer muito mais rapidamente. É necessário um buffer de áudio que receba áudio do texto para fala (tts) para preencher o buffer. Esse buffer é então drenado no ritmo da fala humana e é compreensível para o ser humano.
Dados de áudio: Os dados consistem em uma sequência de números que representam valores de um sinal de áudio em intervalos regulares (chamada taxa de amostragem). Existe também o conceito de canais, que são múltiplos sinais de áudio, que resultam em uma sequência de múltiplos valores.
Para os fins deste artigo consideraremos apenas um canal no lado de entrada e um canal no lado de saída.
Projeto:
Os requisitos são: ser capaz de inserir um número arbitrário de quadros de dados de áudio (um quadro é um número que representa um ponto de dados de áudio), que é uma matriz ordenada de valores de sinal de áudio. No lado da saída, será possível recuperar uma quantidade arbitrária desses quadros. É claro que temos que adicionar recursos convenientes para lidar com as limitações, que são um tamanho de buffer limitado (causa condições de buffer cheio na entrada), nenhum dado de áudio disponível (buffer vazio no lado de saída). Outros recursos convenientes incluirão o preenchimento zero de dados de áudio, caso sejam solicitados mais dados de áudio do que os disponíveis na recuperação do buffer.
Implementação:
O seguinte descreve uma implementação desse buffer em Python:
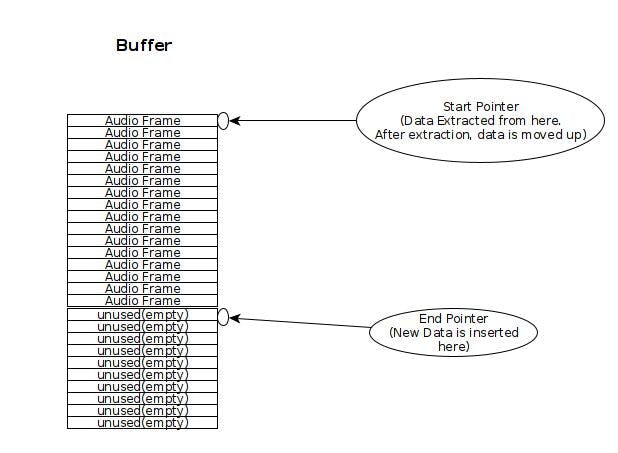
Os bytes de áudio recebidos são armazenados no Buffer. O Buffer possui um ponteiro 'inferior', que aponta até que ponto o buffer está preenchido. Ele também possui um 'ponteiro inicial' que é o início do buffer onde novos dados podem ser enviados. O ponteiro inicial é fixado no início do buffer. O ponteiro inferior é 'dinâmico' e vai 'para cima e para baixo': para cima quando os dados são extraídos e 'para baixo' quando os dados são inseridos. Os dados são sempre inseridos na parte superior (ponteiro inicial) do buffer, resultando em dados existentes no buffer sendo empurrados para 'baixo', aumentando assim o valor do ponteiro inferior.
A condição de buffer vazio ocorre quando o ponteiro inferior é igual ao ponteiro inicial. A condição de buffer cheio ocorre quando o ponteiro inferior é igual ao comprimento do buffer.
Também podemos incluir 'falhas normais' para lidar com as condições em que o buffer está cheio.
Quando o buffer estiver cheio e os dados precisarem ser inseridos, gere uma exceção. Quando o buffer está vazio (incluindo o caso em que são solicitados mais dados do que os disponíveis no buffer), retorne 'zeros' para os dados ausentes. Este é o equivalente sonoro do “silêncio” quando nenhuma palavra é dita.
Um diagrama deste buffer é:

Codificação: (Isenção de responsabilidade: nenhuma IA foi usada para gerar o código abaixo. Toda a culpa (elogio é melhor) deve ser atribuída ao autor..)
Seguindo os princípios de Orientação a Objetos, o código é escrito como uma classe/objeto e é fácil de usar. O código inteiro é:
import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}')Conclusão:
O buffer de áudio é essencial e mais importante agora devido a inúmeras aplicações de processamento de áudio. O algoritmo de buffer de áudio apresentado acima é uma classe Python conveniente.








