

























FIFO 버퍼는 많은 사용 사례에 일반적으로 필요한 데이터 구조입니다. 항목은 버퍼에 저장되고 입력된 순서대로 검색됩니다. 이는 대기열과 유사한 기능입니다. 큐와 버퍼의 차이점은 버퍼에 삽입되는 데이터가 모두 동일한 데이터 유형이라는 것입니다. 또한 임의의 양의 데이터를 삽입할 수 있으며 검색량도 임의적입니다.
동일한 유형의 임의의 숫자 항목을 넣고 검색하려는 사용 사례는 무엇입니까? 데이터 처리 이외의 분야로 분기: 은행 계좌를 생각해 보세요. 돈은 필요한 만큼 넣기도 하고 필요에 따라 꺼내기도 합니다. 농장의 곡물 저장도 마찬가지입니다. 하지만 은행과 곡물창고가 이런 일을 합니다. IT 분야에 우리에게 남은 것은 매우 빠르게 도착하지만 들을 수 있도록 더 느린 특정 속도로 출발해야 하는 오디오 데이터입니다. 오늘날 이에 대한 주범은 대화형 기계/인간 의사소통을 촉진하는 텍스트 음성 변환 엔진입니다. 기계는 텍스트(아마도 AI 엔진에서)를 받아 오디오 바이트로 변환하여 인간이 들을 수 있는 특정 속도로 인간에게 전송됩니다. 예상한 대로 기계는 빠른 클립으로 오디오 바이트를 생성한 다음 훨씬 느린 속도로 사람에게 전달할 수 있도록 버퍼링해야 합니다. 비유는 지역 주유소입니다. 텍스트 투 스피치(Text to speech)는 많은 양의 휘발유를 빠른 속도로 펌핑하여 주유소 내부의 가스 탱크를 채우는 휘발유 탱크입니다. 그런 다음 이러한 것들은 훨씬 느린 속도로 고객의 자동차나 다른 차량으로 전달됩니다.
요약하면 텍스트를 음성(오디오)으로 변환하는 것이 훨씬 더 빠르게 이루어질 수 있습니다. 버퍼를 채우기 위해 텍스트에서 음성으로(tts) 오디오를 수신하는 오디오 버퍼가 필요합니다. 그런 다음 이 버퍼는 인간이 말하는 속도로 소모되며 인간이 이해할 수 있습니다.
오디오 데이터: 데이터는 일정한 간격(샘플링 속도라고 함)의 오디오 신호 값을 나타내는 일련의 숫자로 구성됩니다. 다중 오디오 신호인 채널이라는 개념도 있으며, 이는 다중 값의 시퀀스를 생성합니다.
이 기사의 목적에 따라 우리는 입력 측에 있는 채널 1개와 출력 측에 있는 채널 1개만 고려하겠습니다.
설계:
요구 사항은 오디오 신호 값의 정렬된 배열인 임의의 수의 오디오 데이터 프레임(프레임은 오디오 데이터 포인트를 나타내는 숫자)을 입력할 수 있어야 한다는 것입니다. 출력 측에서는 이러한 프레임 중 임의의 양을 검색할 수 있습니다. 물론 제한된 버퍼 크기(입력 시 버퍼 가득 참 조건 발생), 사용 가능한 오디오 데이터 없음(출력 측 버퍼 비어 있음) 등의 제한 사항을 처리하기 위해 편리한 기능을 추가해야 합니다. 다른 편의 기능에는 버퍼 검색에서 사용할 수 있는 것보다 더 많은 오디오 데이터가 요청되는 경우 오디오 데이터의 제로 채우기가 포함됩니다.
구현:
다음은 Python에서 이러한 버퍼의 구현을 설명합니다.
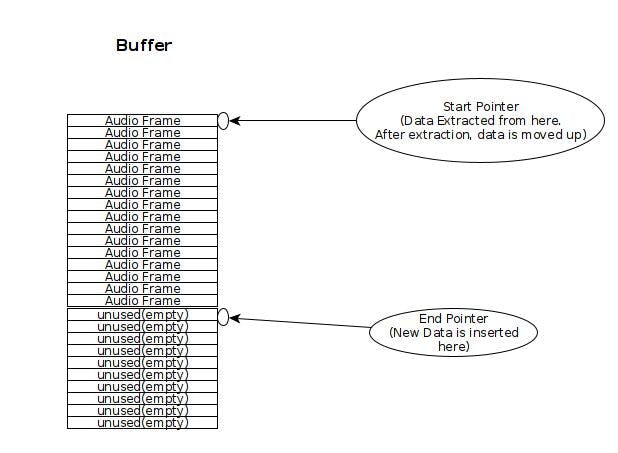
들어오는 오디오 바이트는 버퍼에 저장됩니다. 버퍼에는 버퍼가 채워지는 정도를 가리키는 '하단' 포인터가 있습니다. 또한 새 데이터를 푸시할 수 있는 버퍼의 시작 부분인 '시작 포인터'도 있습니다. 시작 포인터는 버퍼의 시작 부분에 고정됩니다. 하단 포인터는 '동적'이며 '위 및 아래'로 이동합니다. 즉, 데이터가 추출되면 위로 올라가고 데이터가 삽입되면 '아래로' 이동합니다. 데이터는 항상 버퍼의 상단(시작 포인터)에 삽입되어 버퍼의 기존 데이터가 '아래로' 푸시되어 하단 포인터의 값이 증가합니다.
버퍼 비어 있음 상태는 아래쪽 포인터가 시작 포인터와 같을 때 발생합니다. 버퍼 가득 참 조건은 아래쪽 포인터가 버퍼 길이와 같을 때 발생합니다.
버퍼가 가득 찬 조건을 처리하기 위해 'graceful failed'를 포함할 수도 있습니다.
버퍼가 가득 차서 데이터를 삽입해야 하는 경우 예외를 발생시킵니다. 버퍼가 비어 있는 경우(버퍼에서 사용할 수 있는 것보다 더 많은 데이터가 요청되는 경우 포함) 누락된 데이터에 대해 '0'을 반환합니다. 이는 아무 말도 하지 않을 때의 '침묵'에 해당하는 오디오입니다.
이 버퍼의 다이어그램은 다음과 같습니다.

코딩: (면책조항: 아래 코드를 생성하는 데 AI가 사용되지 않았습니다. 모든 비난(칭찬이 더 좋습니다)은 작성자에게 있습니다..)
객체 지향 원칙에 따라 코드는 클래스/객체로 작성되었으며 사용하기 쉽습니다. 전체 코드는 다음과 같습니다.
import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}')결론:
오디오 버퍼링은 필수적이며 수많은 오디오 처리 응용 프로그램으로 인해 이제 더욱 중요해졌습니다. 위에 제시된 오디오 버퍼 알고리즘은 편리한 Python 클래스입니다.








