

























Буфер FIFO — это обычно необходимая структура данных для многих случаев использования. Элементы помещаются в буфер и извлекаются в том порядке, в котором они были помещены. Это аналогично функции очереди. Разница между очередью и буфером заключается в том, что в буфер вставляются данные одного и того же типа. Далее может быть вставлен произвольный объем данных, и объем извлечения также является произвольным.
В каких случаях вы хотите поместить и получить произвольное количество элементов одного и того же типа? Расхождение в областях, отличных от обработки данных: подумайте о банковских счетах: деньги кладутся в разных количествах и вынимаются в тех количествах, которые необходимы. То же самое относится и к хранению зерна на ферме.. Но этим занимаются банки и зернохранилища. Что нам остается в ИТ, так это аудиоданные, которые поступают очень быстро, но должны отправляться с более медленной определенной скоростью, чтобы их можно было услышать. Сегодня виновниками этого являются механизмы преобразования текста в речь, которые облегчают интерактивное общение между машиной и человеком. Машина получает текст (вероятно, от механизма искусственного интеллекта), который преобразует в аудиобайты для отправки человеку с определенной скоростью, которую человек может услышать. Как и ожидалось, машина генерирует аудиобайты в быстром темпе, который затем необходимо буферизовать, чтобы обеспечить доставку человеку с гораздо меньшей скоростью. Аналогия – ваша местная заправочная станция. Текст в речь — это бензовоз, который с высокой скоростью перекачивает много бензина, заполняя бензобаки в недрах заправочной станции. Затем они гораздо медленнее доставляются в автомобили или другие транспортные средства клиента.
Таким образом, преобразование текста в речь (аудио) может происходить гораздо быстрее. Существует необходимость в аудиобуфере, который принимает звук из текста в речь (tts) для заполнения буфера. Этот буфер затем опустошается со скоростью человеческой речи и становится понятным для человека.
Аудиоданные: данные состоят из последовательности чисел, представляющих значения аудиосигнала через равные промежутки времени (называемые частотой дискретизации). Существует также концепция каналов, которая представляет собой несколько аудиосигналов, что приводит к последовательности нескольких значений.
Для целей этой статьи мы будем рассматривать только один канал на входе и один канал на выходе.
Дизайн:
Требования следующие: иметь возможность вводить произвольное количество кадров аудиоданных (кадр — это число, представляющее точку аудиоданных), которое представляет собой упорядоченный массив значений аудиосигнала. На выходе можно получить произвольное количество этих кадров. Нам, конечно, нужно добавить удобные функции для устранения ограничений, а именно: ограниченный размер буфера (вызывает состояние переполнения буфера на входе), отсутствие доступных аудиоданных (буфер пуст на выходной стороне). Другие удобные функции будут включать заполнение нулями аудиоданных в случае, если запрошено больше аудиоданных, чем доступно при извлечении из буфера.
Выполнение:
Ниже описана реализация такого буфера в Python:
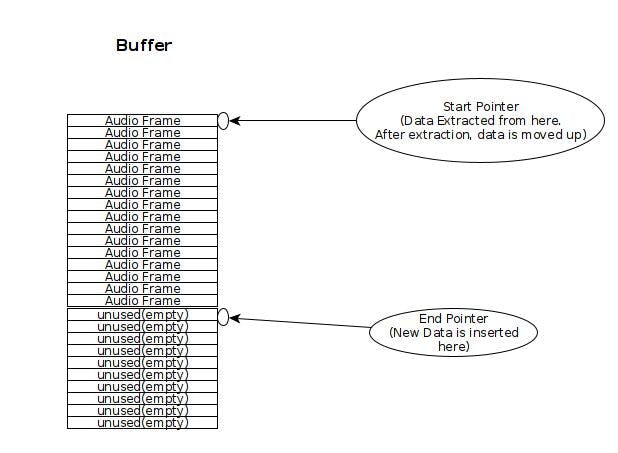
Входящие аудиобайты сохраняются в буфере. У буфера есть «нижний» указатель, который указывает на степень заполнения буфера. Он также имеет «указатель начала», который является началом буфера, куда можно отправить новые данные. Указатель начала фиксируется в начале буфера. Нижний указатель является «динамическим» и перемещается «вверх и вниз»: вверх, когда данные извлекаются, и «вниз», когда данные вставляются. Данные всегда вставляются вверху (начальный указатель) буфера, в результате чего существующие данные в буфере сдвигаются «вниз», тем самым увеличивая значение нижнего указателя.
Состояние пустого буфера возникает, когда нижний указатель равен начальному указателю. Условие заполнения буфера возникает, когда нижний указатель равен длине буфера.
Мы также можем включить «изящные сбои» для обработки условий, когда буфер заполнен.
Когда буфер заполнен и необходимо вставить данные, вызовите исключение. Когда буфер пуст (включая случай, когда запрошено больше данных, чем доступно в буфере), верните «нули» для отсутствующих данных. Это звуковой эквивалент «тишины», когда не произносится ни слова.
Схема этого буфера:

Кодирование: (Отказ от ответственности: для создания приведенного ниже кода не использовался искусственный интеллект. Вся вина (лучше похвала) возлагается на Автора..)
Следуя принципам объектно-ориентированного подхода, код пишется как класс/объект и прост в использовании. Весь код:
import numpy as np #numpy is the standard package or numerical array processing class AudioBuf: def __init__(self,bufSize:int,name:str='',dtype=np.int16): self.buffer = np.zeros((bufSize), dtype=dtype) self.bufSize=bufSize self.dtype=dtype self.idx=0 self.name=name #give a name to the buffer. def putInBuf(self,inData:np.ndarray[np.dtype[np.int16]]): inData=inData[:, 0] #Get the 1st col = channel 0 - mono remainder = self.bufSize - self.idx #space available for insertion if remainder < len(inData): msg=f'Error: Buffer {self.name} is full' print(msg) self.showBuf() raise ValueError(msg) self.buffer[self.idx:self.idx + len(inData)] = inData self.idx += len(inData) def getFromBuf(self,outDataLen:int = None)->np.ndarray: if not outDataLen: outDataLen=self.idx # return entire data of length is not specified if self.idx >= outDataLen: retVal = self.buffer[:outDataLen] self.buffer[0:self.idx-outDataLen]=self.buffer[outDataLen:self.idx] #move buffer up self.idx -= outDataLen else: retVal=np.zeros((outDataLen), dtype=self.dtype) retVal[0:self.idx] = self.buffer[0:self.idx] self.idx=0 return np.reshape(retVal,(-1,1)) #The -1 value automatically calculates to the number of elements def showBuf(self): print(f'AudioBuf : {self.name} has length= {self.idx} with capacity {self.bufSize}')Заключение:
Буферизация звука важна и более важна сейчас из-за многочисленных приложений для обработки звука. Представленный выше алгоритм аудиобуфера представляет собой удобный класс Python.








