























Авторы:
(1) Минцзе Лю, NVIDIA {Равный вклад};
(2) Теодор-Думитру Эне, NVIDIA {Равный вклад};
(3) Роберт Кирби, NVIDIA {Равный вклад};
(4) Крис Ченг, NVIDIA {Равный вклад};
(5) Натаниэль Пинкни, NVIDIA {Равный вклад};
(6) Жунцзянь Лян, NVIDIA {Равный вклад};
(7) Джона Албен, NVIDIA;
(8) Химьяншу Ананд, NVIDIA;
(9) Санмитра Банерджи, NVIDIA;
(10) Исмет Байрактароглу, NVIDIA;
(11) Бонита Бхаскаран, NVIDIA;
(12) Брайан Катандзаро, NVIDIA;
(13) Арджун Чаудхури, NVIDIA;
(14) Шэрон Клэй, NVIDIA;
(15) Билл Далли, NVIDIA;
(16) Лаура Данг, NVIDIA;
(17) Парикшит Дешпанде, NVIDIA;
(18) Сиддхант Дходхи, NVIDIA;
(19) Самир Халепет, NVIDIA;
(20) Эрик Хилл, NVIDIA;
(21) Цзяшан Ху, NVIDIA;
(22) Сумит Джайн, NVIDIA;
(23) Брюсек Хайлани, NVIDIA;
(24) Джордж Кокаи, NVIDIA;
(25) Кишор Кунал, NVIDIA;
(26) Сяовэй Ли, NVIDIA;
(27) Чарли Линд, NVIDIA;
(28) Хао Лю, NVIDIA;
(29) Стюарт Оберман, NVIDIA;
(30) Суджит Омар, NVIDIA;
(31) Сридхар Пратти, NVIDIA;
(23) Джонатан Райман, NVIDIA;
(33) Амбар Саркар, NVIDIA;
(34) Чжэнцзян Шао, NVIDIA;
(35) Ханфэй Сан, NVIDIA;
(36) Пратик П. Сутар, NVIDIA;
(37) Варун Тедж, NVIDIA;
(38) Уокер Тернер, NVIDIA;
(39) Кайжэ Сюй, NVIDIA;
(40) Хаосин Рен, NVIDIA.
Таблица ссылок
- Аннотация и введение
- Набор данных
- Методы адаптации домена ChipNemo
- Приложения LLM
- Оценки
- Обсуждение
- Сопутствующие работы
- Выводы
- Благодарности, вклад и ссылки
- Приложение
IV. ПРИМЕНЕНИЯ LLM
Мы провели исследование потенциальных приложений LLM внутри наших проектных групп и разделили их на четыре группы: генерация кода, вопросы и ответы, анализ и отчетность и сортировка . Генерация кода относится к LLM, генерирующему проектный код, тестовые стенды, утверждения, сценарии внутренних инструментов и т. д.; Вопросы и ответы относятся к LLM, отвечающему на вопросы о проектах, инструментах, инфраструктуре и т. д.; Анализ и отчетность относятся к LLM, анализирующему данные и предоставляющему отчеты; сортировка относится к LLM, помогающему отлаживать проблемы проектирования или инструментов с учетом журналов и отчетов. Мы выбрали по одному ключевому приложению из каждой категории для изучения в этой работе, за исключением категории сортировки , которую мы оставляем для дальнейшего исследования. Мотивация и технические подробности каждого приложения приведены ниже.
А. Чат-бот «Помощник инженера»
Это приложение призвано помочь инженерам-проектировщикам найти ответы на вопросы по архитектуре, проектированию, проверке и сборке, что может значительно повысить их общую производительность, не влияя на производительность других. Замечено, что инженерам-конструкторам часто нравится проводить мозговые штурмы, проектировать аппаратное обеспечение и писать код, но они могут медлить в ожидании ответов на недостающие им знания в области проектирования. Производительность проектирования также можно повысить, если избегать написания инженерами кода на основе ошибочных предположений или отладки кода, с которым они незнакомы. Внутренние исследования показали, что до 60 % времени типичного разработчика микросхем тратится на задачи, связанные с отладкой или контрольными списками по ряду тем, включая спецификации проекта, построение испытательного стенда, определение архитектуры, а также инструменты или инфраструктуру. Эксперты по этим вопросам часто разбросаны по всему миру в транснациональной компании, поэтому не всегда удобно получить немедленную помощь. Таким образом, чат-бот-помощник инженера, основанный на знаниях, извлеченных из внутренних проектных документов, кода, любых записанных данных о проектах и технических коммуникациях, таких как электронные письма, корпоративные мгновенные коммуникации и т. д., может помочь значительно повысить производительность проектирования. Мы реализовали это приложение с помощью адаптированного к предметной области метода RAG, упомянутого в разделе III-D.
Б. Генерация сценария EDA
Еще одна распространенная задача в процессе проектирования промышленных микросхем — написание сценариев EDA для выполнения различных задач, таких как

как реализация дизайна, самоанализ и трансформация. Эти сценарии часто используют как специфичные для инструмента, так и пользовательские внутренние библиотеки сценариев. Изучение этих библиотек, работа с документацией по инструментам, а также написание и отладка этих сценариев могут занять значительное количество инженерного времени.
LLM доказали свою эффективность в мелкомасштабной генерации кода для широкого спектра задач [32], и поэтому настройка этих моделей для повышения производительности инженеров в этой конкретной задаче является естественным подходом. В этой работе мы фокусируемся на создании двух разных типов сценариев на основе описаний задач на естественном языке. Первые — это скрипты, использующие Tool1, внутреннюю библиотеку Python для редактирования и анализа дизайна. Вторые — это сценарии Tcl, использующие командный интерфейс Tool2, ведущего промышленного инструмента статического временного анализа.
Чтобы создать набор данных для точной настройки для этой задачи, производственные сценарии для обоих инструментов были собраны у экспертов по дизайну. Мы заметили, что наши модели DAPT могут генерировать разумные встроенные комментарии к коду. Это позволило нам использовать эти модели для улучшения качества собранных скриптов за счет создания дополнительных встроенных комментариев. Позже эксперты-люди проверили и исправили эти комментарии и создали соответствующую подсказку. Эти подсказки и пары кодов составляют данные, используемые для DSFT в формате, описанном в разделе III-C.
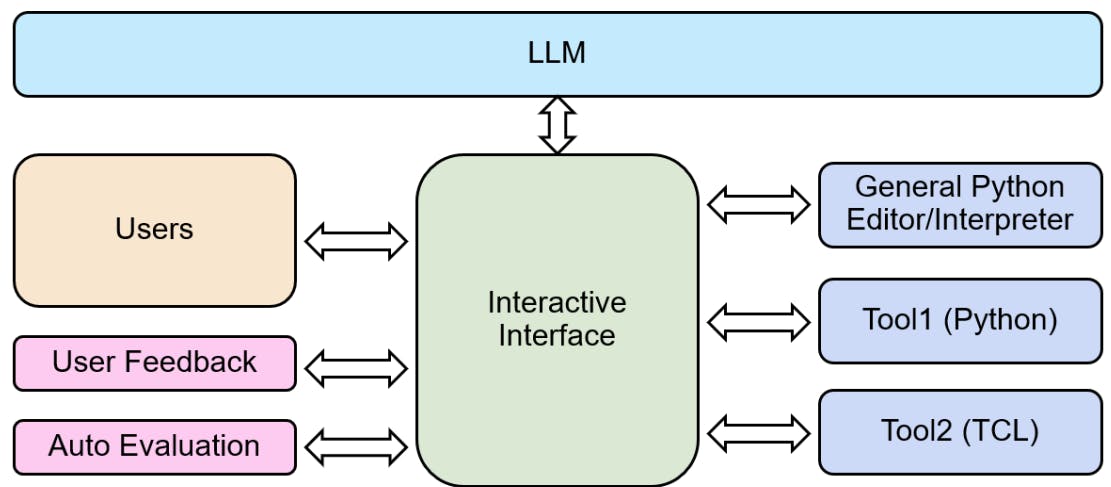
Чтобы предоставлять и собирать обратную связь наиболее содержательным способом, мы потратили значительные усилия на создание потока, показанного на рис. 4, где инженеры могут как запрашивать модель, так и запускать сгенерированный код через один и тот же интерфейс. Это позволяет нам быть уверенными в правильности сгенерированного кода, а также предоставлять точную обратную связь, позволяя инженерам видеть, сколько исправлений им может потребоваться, чтобы получить работающий скрипт. Мы поддерживаем интеграцию Tool1 и Tool2, устанавливая интерактивные соединения с серверами инструментов.
Кроме того, мы предоставляем форму обратной связи с пользователями, позволяющую нам сравнивать различные модели и получать ценную информацию из отзывов пользователей. Эта ценная информация может помочь нам в дальнейшем совершенствовании наших моделей.
C. Обобщение и анализ ошибок
Отслеживание отчетов, сортировка, отладка и устранение различных функций и ошибок на этапах производственного процесса — трудоемкий процесс. Инженерные менеджеры тратят много времени на просмотр внутренних баз данных отслеживания проблем, чтобы получить представление о состоянии проекта и ускорить его выполнение. Таким образом, инструмент, который способен просмотреть всю вспомогательную информацию и быстро обобщить как технические, так и управленческие данные, а также предложить следующие шаги, повысит производительность команды. Мы фокусируемся на использовании LLM для получения трех различных результатов: один посвящен техническим деталям, один - управленческим деталям и один - рекомендациям по назначению задач.
Для изучения этих задач мы использовали внутреннюю базу данных ошибок NVIDIA NVBugs. Эта база данных используется для отчетов об ошибках, отслеживания и устранения ошибок, а также для общего отслеживания задач и функций во всей компании. Мы ожидаем, что модели ChipNeMo хорошо справятся с этой задачей, поскольку в набор данных DAPT было включено большое количество данных об ошибках. Кроме того, для этой задачи мы создали набор данных SFT для конкретной предметной области, который включает примеры задач суммирования ошибок и назначения задач.
Часто описания ошибок содержат большие фрагменты файлов журналов или дампов кода, а также длинную историю комментариев. В таких случаях текст ошибки слишком велик для наших контекстных окон LLM. Чтобы обойти эту проблему, мы реализовали два решения. Во-первых, мы нашли и заменили длинные имена путей более короткими псевдонимами, чтобы позволить модели связывать пути, которые встречаются в нескольких местах ошибки, без необходимости обрабатывать всю строку. Во-вторых, мы разделяем задачу суммирования на инкрементальную задачу, в которой перед моделью ставится задача накапливать данные по нескольким фрагментам сводных данных и данных об ошибках. Мы используем иерархический подход, при котором ошибка сначала разделяется на фрагменты, которые помещаются в контекстное окно. Затем эти фрагменты суммируются, а сводные данные накапливаются и разделяются на фрагменты. Этот процесс повторяется до тех пор, пока весь набор сводок не поместится в одно контекстное окно и не будет создано одно резюме. Мы используем тот же подход независимо от LLM, используемого для обобщения.
Этот документ доступен на arxiv под лицензией CC 4.0.








