























लेखक:
(1) मिंगजी लियू, एनवीडिया {समान योगदान};
(2) टेओडोर-डुमित्रु एने, एनवीडिया {समान योगदान};
(3) रॉबर्ट किर्बी, एनवीडिया {समान योगदान};
(4) क्रिस चेंग, एनवीडिया {समान योगदान};
(5) नाथनियल पिंकनी, एनवीडिया {समान योगदान};
(6) रोंगजियान लियांग, एनवीडिया {समान योगदान};
(7) जोना अल्बेन, एनवीडिया;
(8) हिमांशु आनंद, एनवीडिया;
(9) संमित्रा बनर्जी, एनवीडिया;
(10) इस्मेट बेराकटारोग्लू, एनवीडिया;
(11) बोनिता भास्करन, एनवीडिया;
(12) ब्रायन कैटनज़ारो, एनवीडिया;
(13) अर्जुन चौधरी, एनवीडिया;
(14) शेरोन क्ले, एनवीडिया;
(15) बिल डैली, एनवीडिया;
(16) लौरा डांग, एनवीडिया;
(17) परीक्षित देशपांडे, एनवीडिया;
(18) सिद्धनाथ ढोढ़ी, एनवीडिया;
(19) समीर हालेपेट, एनवीडिया;
(20) एरिक हिल, एनवीडिया;
(21) जियाशांग हू, एनवीडिया;
(22) सुमित जैन, एनवीडिया;
(23) ब्रुसेक खैलानी, एनवीडिया;
(24) जॉर्ज कोकाई, एनवीडिया;
(25) किशोर कुणाल, एनवीडिया;
(26) ज़ियाओवेई ली, एनवीडिया;
(27) चार्ली लिंड, एनवीडिया;
(28) हाओ लियू, एनवीडिया;
(29) स्टुअर्ट ओबरमैन, एनवीडिया;
(30) सुजीत उमर, एनवीडिया;
(31) श्रीधर प्रट्टी, एनवीडिया;
(23) जोनाथन रायमन, एनवीडिया;
(33) अंबर सरकार, एनवीडिया;
(34) झेंगजियांग शाओ, एनवीडिया;
(35) हनफ़ेई सन, एनवीडिया;
(36) प्रतीक पी सुथार, एनवीडिया;
(37) वरुण तेज, एनवीडिया;
(38) वॉकर टर्नर, एनवीडिया;
(39) कैझे जू, एनवीडिया;
(40) हॉक्सिंग रेन, एनवीडिया.
लिंक की तालिका
- सार और परिचय
- डेटासेट
- चिपनेमो डोमेन अनुकूलन विधियाँ
- एलएलएम अनुप्रयोग
- मूल्यांकन
- बहस
- संबंधित काम
- निष्कर्ष
- आभार, योगदान और संदर्भ
- अनुबंध
IV. एलएलएम आवेदन
हमने अपनी डिजाइन टीमों के भीतर संभावित एलएलएम अनुप्रयोगों का एक सर्वेक्षण किया और उन्हें चार श्रेणियों में वर्गीकृत किया: कोड जनरेशन, प्रश्न और उत्तर, विश्लेषण और रिपोर्टिंग , और ट्राइएज । कोड जनरेशन का अर्थ है एलएलएम जो डिजाइन कोड, टेस्टबेंच, दावे, आंतरिक टूल स्क्रिप्ट आदि उत्पन्न करता है; प्रश्न और उत्तर का अर्थ है एक एलएलएम जो डिजाइन, उपकरण, अवसंरचना आदि के बारे में सवालों के जवाब देता है; विश्लेषण और रिपोर्टिंग का अर्थ है एक एलएलएम डेटा का विश्लेषण करता है और रिपोर्ट प्रदान करता है; ट्राइएज का अर्थ है एक एलएलएम जो लॉग और रिपोर्ट दिए जाने पर डिजाइन या टूल की समस्याओं को डीबग करने में मदद करता है। हमने इस कार्य में अध्ययन करने के लिए प्रत्येक श्रेणी से एक प्रमुख अनुप्रयोग का चयन किया, ट्राइएज श्रेणी को छोड़कर जिसे हम आगे के शोध के लिए छोड़ते हैं
ए. इंजीनियरिंग सहायक चैटबॉट
इस एप्लिकेशन का उद्देश्य डिज़ाइन इंजीनियरों को उनके आर्किटेक्चर, डिज़ाइन, सत्यापन और निर्माण प्रश्नों के उत्तर देने में मदद करना है, जो दूसरों की उत्पादकता को प्रभावित किए बिना उनकी समग्र उत्पादकता में उल्लेखनीय सुधार कर सकते हैं। यह देखा गया है कि डिज़ाइन इंजीनियर अक्सर विचार-मंथन, हार्डवेयर डिज़ाइन करना और कोड लिखना पसंद करते हैं, लेकिन डिज़ाइन ज्ञान के उत्तरों की प्रतीक्षा में धीमे हो सकते हैं, जिसकी उन्हें कमी है। डिज़ाइन उत्पादकता को इंजीनियरों को गलत धारणाओं या डिबगिंग कोड के आधार पर कोड लिखने से बचाकर भी बढ़ाया जा सकता है, जिससे वे अपरिचित हैं। आंतरिक अध्ययनों से पता चला है कि एक सामान्य चिप डिज़ाइनर का 60% समय डिज़ाइन विनिर्देशों, टेस्टबेंच निर्माण, आर्किटेक्चर परिभाषा और उपकरण या बुनियादी ढाँचे सहित कई विषयों पर डिबग या चेकलिस्ट से संबंधित कार्यों में व्यतीत होता है। इन मुद्दों पर विशेषज्ञ अक्सर एक बहुराष्ट्रीय कंपनी में दुनिया भर में फैले होते हैं, जिससे तुरंत मदद पाना हमेशा सुविधाजनक नहीं होता है। इसलिए, आंतरिक डिज़ाइन दस्तावेज़ों, कोड, डिज़ाइन और तकनीकी संचार जैसे ईमेल और कॉर्पोरेट इंस्टेंट संचार आदि से निकाले गए ज्ञान पर आधारित एक इंजीनियरिंग सहायक चैटबॉट डिज़ाइन उत्पादकता को बेहतर बनाने में महत्वपूर्ण रूप से मदद कर सकता है। हमने इस एप्लिकेशन को सेक्शन III-D में उल्लिखित डोमेन-अनुकूलित RAG विधि के साथ लागू किया।
बी. ईडीए स्क्रिप्ट जनरेशन
औद्योगिक चिप डिजाइन प्रवाह में एक अन्य सामान्य कार्य विभिन्न प्रकार के कार्यों को पूरा करने के लिए EDA स्क्रिप्ट लिखना है

डिज़ाइन कार्यान्वयन, आत्मनिरीक्षण और परिवर्तन के रूप में। ये स्क्रिप्ट अक्सर उपकरण-विशिष्ट और कस्टम आंतरिक स्क्रिप्ट लाइब्रेरी दोनों का लाभ उठाती हैं। इन लाइब्रेरी को सीखना, उपकरण दस्तावेज़ीकरण को नेविगेट करना, और इन स्क्रिप्ट को लिखना और डीबग करना, इंजीनियरिंग समय की एक महत्वपूर्ण राशि ले सकता है।
एलएलएम ने कई तरह के कार्यों पर छोटे पैमाने पर कोड जनरेशन में महारत हासिल की है [32] और इसलिए इस डोमेन विशिष्ट कार्य में इंजीनियर उत्पादकता में तेजी लाने के लिए इन मॉडलों को अनुकूलित करना एक स्वाभाविक फिट है। इस काम में हम प्राकृतिक भाषा कार्य विवरणों से दो अलग-अलग प्रकार की स्क्रिप्ट बनाने पर ध्यान केंद्रित करते हैं। पहली स्क्रिप्ट हैं जो टूल 1 का लाभ उठाती हैं, जो डिज़ाइन संपादन और विश्लेषण के लिए एक आंतरिक पायथन लाइब्रेरी है। दूसरी Tcl स्क्रिप्ट हैं जो Tool2 द्वारा प्रदान किए गए कमांड इंटरफ़ेस का उपयोग करती हैं, जो एक प्रमुख औद्योगिक स्थिर समय विश्लेषण उपकरण है।
इस कार्य के लिए हमारे डोमेन-विशिष्ट फ़ाइन-ट्यूनिंग डेटासेट का निर्माण करने के लिए, डिज़ाइन विशेषज्ञों से दोनों उपकरणों के लिए उत्पादन स्क्रिप्ट एकत्र की गई थी। हमने देखा कि हमारे DAPT मॉडल कोड के लिए उचित इनलाइन टिप्पणियाँ उत्पन्न कर सकते हैं। इसने हमें अतिरिक्त इनलाइन टिप्पणियाँ उत्पन्न करके एकत्रित स्क्रिप्ट की गुणवत्ता में सुधार करने के लिए इन मॉडलों का उपयोग करने में सक्षम बनाया। मानव विशेषज्ञों ने बाद में इन टिप्पणियों को सत्यापित और सही किया और एक संबद्ध प्रॉम्प्ट बनाया। ये प्रॉम्प्ट और कोड जोड़े अनुभाग III-C में चर्चा किए गए प्रारूप में DSFT के लिए उपयोग किए जाने वाले डेटा को बनाते हैं।
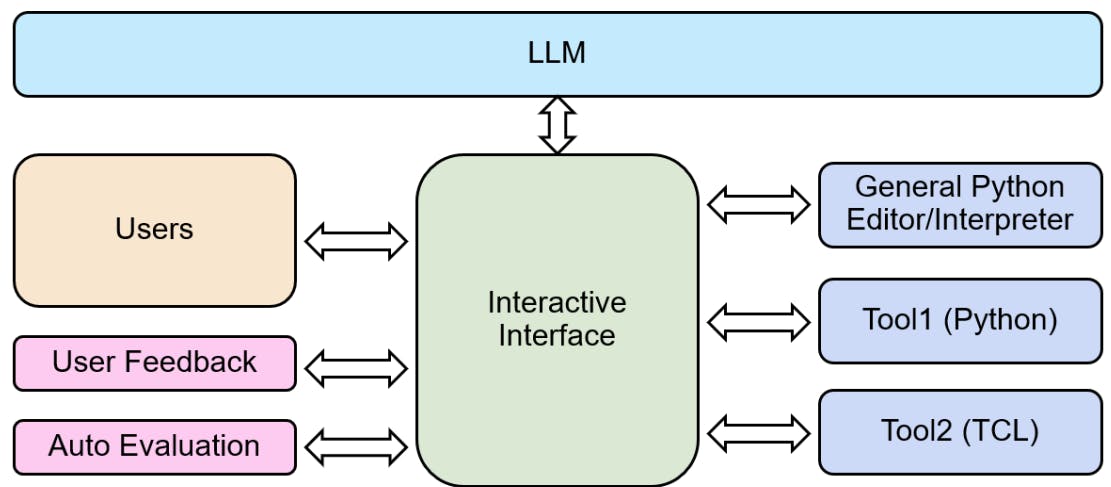
सबसे सार्थक तरीके से फीडबैक प्रदान करने और एकत्र करने के लिए, हमने चित्र 4 में दिखाए गए प्रवाह को बनाने में महत्वपूर्ण प्रयास किया, जहाँ इंजीनियर मॉडल को क्वेरी कर सकते हैं और उसी इंटरफ़ेस के माध्यम से जेनरेट किए गए कोड को चला सकते हैं। यह हमें जेनरेट किए गए कोड की शुद्धता के बारे में आश्वस्त होने के साथ-साथ इंजीनियरों को यह देखने की अनुमति देकर सटीक फीडबैक प्रदान करने की अनुमति देता है कि एक कार्यशील स्क्रिप्ट प्राप्त करने के लिए उन्हें कितने सुधारों की आवश्यकता हो सकती है। हम टूल सर्वर से इंटरैक्टिव कनेक्शन स्थापित करके टूल 1 और टूल 2 एकीकरण का समर्थन करते हैं।
इसके अतिरिक्त, हम एक उपयोगकर्ता फ़ीडबैक फ़ॉर्म प्रदान करते हैं, जिससे हम विभिन्न मॉडलों की तुलना कर सकते हैं और उपयोगकर्ता फ़ीडबैक से मूल्यवान जानकारी प्राप्त कर सकते हैं। यह मूल्यवान जानकारी हमें अपने मॉडलों को और बेहतर बनाने में सहायता कर सकती है।
सी. बग सारांशीकरण और विश्लेषण
उत्पादन प्रवाह के विभिन्न चरणों में विभिन्न सुविधाओं और बगों की रिपोर्टिंग, ट्राइएज, डीबग और समाधान को ट्रैक करना एक समय लेने वाली प्रक्रिया है। इंजीनियरिंग प्रबंधक परियोजना की स्थिति को समझने और उनके निष्पादन में तेजी लाने में मदद करने के लिए आंतरिक समस्या ट्रैकिंग डेटाबेस की समीक्षा करने में बहुत समय बिताते हैं। इसलिए, एक ऐसा उपकरण जो सभी सहायक सूचनाओं को देखने और तकनीकी और प्रबंधकीय डेटा दोनों को जल्दी से सारांशित करने के साथ-साथ अगले चरणों का सुझाव देने में सक्षम हो, टीम की उत्पादकता को बढ़ाएगा। हम तीन अलग-अलग आउटपुट उत्पन्न करने के लिए LLM का उपयोग करने पर ध्यान केंद्रित करते हैं - एक तकनीकी विवरण पर केंद्रित, एक प्रबंधकीय विवरण पर और एक कार्य असाइनमेंट की सिफारिश करता है।
इन कार्यों का अध्ययन करने के लिए हमने NVIDIA के आंतरिक बग डेटाबेस, NVBugs का उपयोग किया। इस डेटाबेस का उपयोग बग रिपोर्टिंग, ट्रैकिंग और समाधान के साथ-साथ कंपनी भर में सामान्य कार्य और फीचर ट्रैकिंग के लिए किया जाता है। हमें उम्मीद है कि ChipNeMo मॉडल इस कार्य पर अच्छा प्रदर्शन करेंगे क्योंकि DAPT डेटासेट में बड़ी मात्रा में बग डेटा शामिल था। इसके अतिरिक्त, हमने इस कार्य के लिए एक डोमेन-विशिष्ट SFT डेटासेट बनाया जिसमें बग सारांश और कार्य असाइनमेंट कार्यों के उदाहरण शामिल हैं।
अक्सर, बग विवरण में लॉग फ़ाइलों या कोड डंप के बड़े स्निपेट के साथ-साथ लंबी टिप्पणी इतिहास शामिल होते हैं। ऐसे मामलों में, बग टेक्स्ट हमारे LLM संदर्भ विंडो के लिए बहुत बड़ा होता है। इस पर काम करने के लिए, हमने दो समाधान लागू किए। सबसे पहले, हमने लंबे पथ नामों को पाया और उन्हें छोटे उपनामों से बदल दिया ताकि मॉडल बग में कई जगहों पर होने वाले पथों को संबद्ध कर सके, बिना पूरी स्ट्रिंग को संसाधित किए। दूसरा, हमने सारांश कार्य को एक वृद्धिशील कार्य में विभाजित किया, जहाँ मॉडल को कई सारांश और बग डेटा खंडों में डेटा संचित करने का काम सौंपा गया है। हम एक पदानुक्रमित दृष्टिकोण का उपयोग करते हैं जहाँ बग को पहले उन खंडों में विभाजित किया जाता है जो संदर्भ विंडो में फिट होते हैं। फिर उन खंडों को सारांशित किया जाता है और सारांशों को संचित किया जाता है और फिर खंडों में अलग किया जाता है। यह प्रक्रिया तब तक दोहराई जाती है जब तक कि सारांशों का पूरा सेट एक एकल संदर्भ विंडो में फिट न हो जाए और एक एकल सारांश उत्पन्न न हो जाए। हम सारांश के लिए उपयोग किए जाने वाले LLM से स्वतंत्र इसी दृष्टिकोण का उपयोग करते हैं।
यह पेपर CC 4.0 लाइसेंस के अंतर्गत arxiv पर उपलब्ध है।








