























Autores:
(1) Mingjie Liu, NVIDIA {Contribuição igual};
(2) Teodor-Dumitru Ene, NVIDIA {Contribuição igual};
(3) Robert Kirby, NVIDIA {Contribuição igual};
(4) Chris Cheng, NVIDIA {Contribuição igual};
(5) Nathaniel Pinckney, NVIDIA {Contribuição igual};
(6) Rongjian Liang, NVIDIA {Contribuição igual};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Tabela de links
- Resumo e introdução
- Conjunto de dados
- Métodos de adaptação de domínio ChipNemo
- Aplicações LLM
- Avaliações
- Discussão
- Trabalhos relacionados
- Conclusões
- Agradecimentos, Contribuições e Referências
- Apêndice
4. APLICAÇÕES LLM
Conduzimos uma pesquisa de possíveis aplicações LLM em nossas equipes de design e as categorizamos em quatro grupos: geração de código, perguntas e respostas, análise e relatórios e triagem . A geração de código refere-se ao LLM que gera código de design, testbenches, asserções, scripts de ferramentas internas, etc.; Perguntas e Respostas referem-se a um LLM que responde a perguntas sobre projetos, ferramentas, infraestruturas, etc.; Análise e relatórios referem-se a um LLM que analisa dados e fornece relatórios; triagem refere-se a um LLM que ajuda a depurar problemas de design ou ferramentas, dados registros e relatórios. Selecionamos uma aplicação-chave de cada categoria para estudar neste trabalho, exceto a categoria de triagem que deixamos para pesquisas futuras. A motivação e os detalhes técnicos de cada aplicação são apresentados abaixo.
A. Chatbot assistente de engenharia
Este aplicativo tem como objetivo ajudar os engenheiros de projeto com respostas às suas questões de arquitetura, projeto, verificação e construção, o que pode melhorar significativamente sua produtividade geral sem impactar a produtividade de terceiros. Observa-se que os engenheiros de design muitas vezes gostam de fazer brainstorming, projetar hardware e escrever código, mas podem ficar lentos esperando por respostas sobre o conhecimento de design que lhes falta. A produtividade do projeto também pode ser aprimorada evitando que os engenheiros escrevam códigos com base em suposições erradas ou depurem códigos com os quais não estão familiarizados. Estudos internos mostraram que até 60% do tempo típico de um projetista de chips é gasto em tarefas relacionadas à depuração ou lista de verificação em uma variedade de tópicos, incluindo especificações de design, construção de testbench, definição de arquitetura e ferramentas ou infraestrutura. Os especialistas nestas questões estão frequentemente espalhados por todo o mundo numa empresa multinacional, pelo que nem sempre é conveniente encontrar ajuda imediata. Portanto, um chatbot assistente de engenharia baseado no conhecimento extraído de documentos internos de projeto, código, quaisquer dados registrados sobre projetos e comunicações técnicas, como e-mails e comunicações corporativas instantâneas, etc., poderia ajudar a melhorar significativamente a produtividade do projeto. Implementamos esta aplicação com o método RAG adaptado ao domínio mencionado na Seção III-D.
B. Geração de script EDA
Outra tarefa comum em um fluxo de design de chip industrial é escrever scripts EDA para realizar uma variedade de tarefas, como

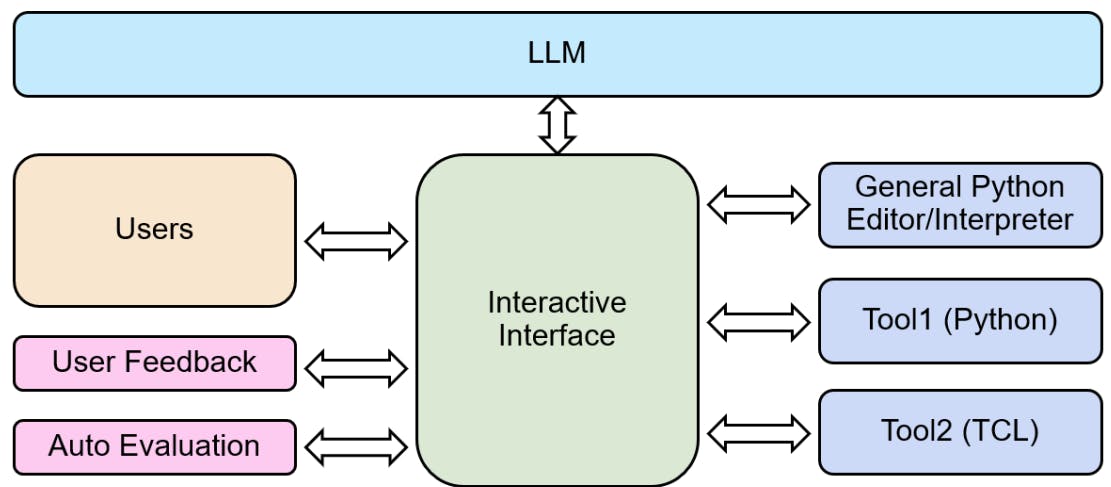
como implementação de design, introspecção e transformação. Esses scripts geralmente aproveitam bibliotecas de scripts internas específicas da ferramenta e personalizadas. Aprender essas bibliotecas, navegar na documentação da ferramenta e escrever e depurar esses scripts pode consumir uma quantidade significativa de tempo de engenharia.
Os LLMs provaram ser adeptos da geração de código em pequena escala em uma ampla gama de tarefas [32] e, portanto, personalizar esses modelos para acelerar a produtividade do engenheiro nesta tarefa específica de domínio é uma escolha natural. Neste trabalho nos concentramos na geração de dois tipos diferentes de scripts a partir de descrições de tarefas em linguagem natural. Os primeiros são scripts que aproveitam a Tool1, uma biblioteca python interna para edição e análise de projetos. O segundo são scripts Tcl que usam a interface de comando fornecida pelo Tool2, que é uma ferramenta líder de análise de tempo estático industrial.
Para construir nosso conjunto de dados de ajuste fino específico de domínio para esta tarefa, scripts de produção para ambas as ferramentas foram coletados de especialistas em design. Observamos que nossos modelos DAPT podem gerar comentários embutidos razoáveis para o código. Isso nos permitiu usar esses modelos para melhorar a qualidade dos scripts coletados, gerando comentários adicionais em linha. Posteriormente, especialistas humanos verificaram e corrigiram esses comentários e criaram um prompt associado. Esses prompts e pares de códigos constituem os dados usados para DSFT no formato discutido na Seção III-C.
Para fornecer e coletar feedback da maneira mais significativa, despendemos um esforço significativo na construção do fluxo mostrado na Figura 4, onde os engenheiros podem consultar o modelo e executar o código gerado por meio da mesma interface. Isso nos permite ter confiança na exatidão do código gerado, bem como fornecer feedback preciso, permitindo que os engenheiros vejam quantas correções eles podem precisar para obter um script funcional. Oferecemos suporte à integração de Tool1 e Tool2 estabelecendo conexões interativas com servidores de ferramentas.
Além disso, fornecemos um formulário de feedback do usuário, que nos permite comparar diferentes modelos e obter informações valiosas do feedback do usuário. Essas informações valiosas podem nos ajudar a refinar ainda mais nossos modelos.
C. Resumo e análise de bugs
Acompanhar os relatórios, a triagem, a depuração e a resolução de vários recursos e bugs em todos os estágios do fluxo de produção é um processo demorado. Os gerentes de engenharia passam muito tempo revisando bancos de dados internos de rastreamento de problemas para compreender o estado do projeto e ajudar a acelerar sua execução. Portanto, uma ferramenta capaz de analisar todas as informações de apoio e resumir rapidamente os dados técnicos e gerenciais, bem como sugerir os próximos passos, aumentaria a produtividade da equipe. Nós nos concentramos no uso de LLMs para gerar três resultados diferentes - um focado em detalhes técnicos, um em detalhes gerenciais e um recomendando atribuição de tarefas.
Para estudar essas tarefas usamos o banco de dados interno de bugs da NVIDIA, NVBugs. Este banco de dados é usado para relatórios, rastreamento e resolução de bugs, bem como tarefas gerais e rastreamento de recursos em toda a empresa. Esperamos que os modelos ChipNeMo tenham um bom desempenho nesta tarefa, já que uma grande quantidade de dados de bugs foi incluída no conjunto de dados DAPT. Além disso, construímos um conjunto de dados SFT específico de domínio para esta tarefa que inclui exemplos de resumo de bugs e tarefas de atribuição de tarefas.
Freqüentemente, as descrições de bugs contêm grandes trechos de arquivos de log ou despejos de código junto com longos históricos de comentários. Nesses casos, o texto do bug é muito grande para nossas janelas de contexto LLM. Para contornar isso, implementamos duas soluções. Primeiro, encontramos e substituímos nomes de caminhos longos por aliases mais curtos para permitir que o modelo associe caminhos que ocorrem em vários locais do bug sem a necessidade de processar a string inteira. Em segundo lugar, dividimos a tarefa de resumo em uma tarefa incremental em que o modelo tem a tarefa de acumular dados em vários blocos de dados de resumo e de bugs. Usamos uma abordagem hierárquica onde o bug é primeiro separado em partes que cabem na janela de contexto. Esses pedaços são então resumidos e os resumos são acumulados e separados em pedaços. Este processo é repetido até que todo o conjunto de resumos caiba em uma única janela de contexto e um único resumo seja gerado. Usamos essa mesma abordagem independente do LLM usado para resumo.
Este artigo está disponível no arxiv sob licença CC 4.0.








