























Autoren:
(1) Mingjie Liu, NVIDIA {Gleicher Beitrag};
(2) Teodor-Dumitru Ene, NVIDIA {Gleicher Beitrag};
(3) Robert Kirby, NVIDIA {Gleicher Beitrag};
(4) Chris Cheng, NVIDIA {Gleicher Beitrag};
(5) Nathaniel Pinckney, NVIDIA {Gleicher Beitrag};
(6) Rongjian Liang, NVIDIA {Gleicher Beitrag};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Linktabelle
- Zusammenfassung und Einleitung
- Datensatz
- ChipNemo-Domänenanpassungsmethoden
- LLM-Bewerbungen
- Bewertungen
- Diskussion
- Verwandte Arbeiten
- Schlussfolgerungen
- Danksagungen, Beiträge und Referenzen
- Anhang
IV. LLM-BEWERBUNGEN
Wir haben in unseren Designteams eine Umfrage zu potenziellen LLM-Anwendungen durchgeführt und diese in vier Kategorien eingeteilt: Codegenerierung, Fragen und Antworten, Analyse und Berichterstellung sowie Triage . Unter Codegenerierung versteht man ein LLM, das Designcode, Testbänke, Behauptungen, Skripte interner Tools usw. generiert. Unter Fragen und Antworten versteht man ein LLM, das Fragen zu Designs, Tools, Infrastrukturen usw. beantwortet. Unter Analyse und Berichterstellung versteht man ein LLM, das Daten analysiert und Berichte bereitstellt. Triage bezeichnet ein LLM, das bei der Fehlerbehebung von Design- oder Toolproblemen anhand von Protokollen und Berichten hilft. Aus jeder Kategorie haben wir für diese Arbeit eine Schlüsselanwendung ausgewählt, mit Ausnahme der Kategorie Triage , die wir weiteren Untersuchungen überlassen. Die Motivation und die technischen Details der einzelnen Anwendungen sind unten aufgeführt.
A. Chatbot für technischen Assistenten
Diese Anwendung soll Konstrukteuren mit Antworten auf ihre Fragen zu Architektur, Design, Verifizierung und Aufbau helfen, was ihre Gesamtproduktivität erheblich steigern könnte, ohne die Produktivität anderer zu beeinträchtigen. Es wurde beobachtet, dass Konstrukteure häufig gerne Brainstorming betreiben, Hardware entwerfen und Code schreiben, aber durch das Warten auf Antworten auf fehlendes Designwissen ausgebremst werden können. Die Designproduktivität kann auch dadurch gesteigert werden, dass Ingenieure Code nicht auf der Grundlage falscher Annahmen schreiben oder Code debuggen, mit dem sie nicht vertraut sind. Interne Studien haben gezeigt, dass bis zu 60 % der Zeit eines typischen Chipdesigners mit Debugging- oder Checklistenaufgaben zu einer Reihe von Themen wie Designspezifikationen, Testbench-Konstruktion, Architekturdefinition und Tools oder Infrastruktur verbracht wird. Experten für diese Themen sind in einem multinationalen Unternehmen häufig über den ganzen Globus verteilt, sodass es nicht immer bequem ist, sofort Hilfe zu finden. Daher könnte ein Chatbot als technischer Assistent, der auf Wissen aus internen Designdokumenten, Code, allen aufgezeichneten Daten zu Designs und technischer Kommunikation wie E-Mails und Instant Communications des Unternehmens usw. basiert, dazu beitragen, die Designproduktivität erheblich zu verbessern. Wir haben diese Anwendung mit der domänenangepassten RAG-Methode implementiert, die in Abschnitt III-D erwähnt wird.
B. EDA-Skriptgenerierung
Eine weitere häufige Aufgabe in einem industriellen Chip-Design-Flow ist das Schreiben von EDA-Skripten, um eine Vielzahl von Aufgaben zu erfüllen, wie

wie Designimplementierung, Introspektion und Transformation. Diese Skripte nutzen oft sowohl werkzeugspezifische als auch benutzerdefinierte interne Skriptbibliotheken. Das Erlernen dieser Bibliotheken, das Navigieren in der Werkzeugdokumentation sowie das Schreiben und Debuggen dieser Skripte kann einen erheblichen Teil der Entwicklungszeit in Anspruch nehmen.
LLMs haben sich bei der Generierung von Code in kleinem Maßstab für eine Vielzahl von Aufgaben als geeignet erwiesen [32]. Daher ist die Anpassung dieser Modelle zur Beschleunigung der Produktivität des Ingenieurs bei dieser domänenspezifischen Aufgabe eine naheliegende Lösung. In dieser Arbeit konzentrieren wir uns auf die Generierung von zwei verschiedenen Arten von Skripten aus Aufgabenbeschreibungen in natürlicher Sprache. Die ersten sind Skripte, die Tool1 nutzen, eine interne Python-Bibliothek zur Bearbeitung und Analyse von Designs. Die zweiten sind Tcl-Skripte, die die Befehlsschnittstelle von Tool2 verwenden, einem führenden industriellen Werkzeug zur statischen Zeitanalyse.
Um unseren domänenspezifischen Feinabstimmungsdatensatz für diese Aufgabe zu erstellen, wurden Produktionsskripte für beide Tools von Designexperten gesammelt. Wir haben festgestellt, dass unsere DAPT-Modelle sinnvolle Inline-Kommentare für den Code generieren können. Dies ermöglichte es uns, diese Modelle zu verwenden, um die Qualität der gesammelten Skripte durch die Generierung zusätzlicher Inline-Kommentare zu verbessern. Menschliche Experten überprüften und korrigierten diese Kommentare später und erstellten eine zugehörige Eingabeaufforderung. Diese Eingabeaufforderungen und Codepaare bilden die für DSFT verwendeten Daten in dem in Abschnitt III-C beschriebenen Format.
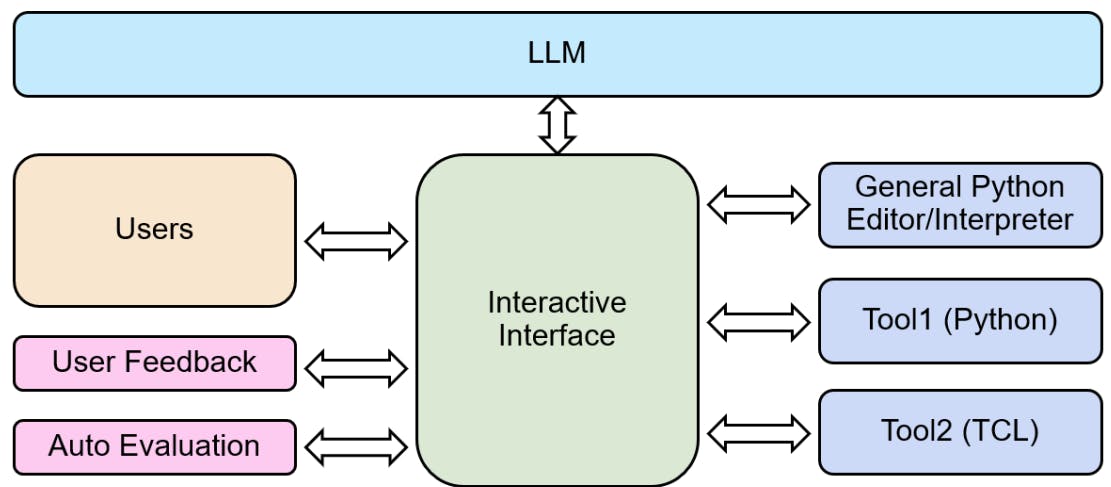
Um Feedback auf möglichst sinnvolle Weise bereitzustellen und zu sammeln, haben wir viel Aufwand in die Entwicklung des in Abb. 4 gezeigten Ablaufs gesteckt, bei dem Ingenieure sowohl das Modell abfragen als auch generierten Code über dieselbe Schnittstelle ausführen können. Dadurch können wir uns auf die Richtigkeit des generierten Codes verlassen und präzises Feedback geben, da Ingenieure sehen, wie viele Korrekturen sie möglicherweise benötigen, um ein funktionierendes Skript zu erhalten. Wir unterstützen die Integration von Tool1 und Tool2, indem wir interaktive Verbindungen zu Tool-Servern herstellen.
Darüber hinaus stellen wir ein Benutzerfeedbackformular zur Verfügung, mit dem wir verschiedene Modelle vergleichen und aus dem Benutzerfeedback wertvolle Erkenntnisse gewinnen können. Diese wertvollen Informationen können uns dabei helfen, unsere Modelle weiter zu verfeinern.
C. Fehlerzusammenfassung und -analyse
Das Verfolgen der Berichterstattung, Sichtung, Fehlerbehebung und Lösung verschiedener Funktionen und Fehler über die verschiedenen Phasen des Produktionsflusses hinweg ist ein zeitaufwändiger Prozess. Technische Manager verbringen viel Zeit damit, interne Problemverfolgungsdatenbanken zu überprüfen, um den Status des Projekts zu verstehen und die Ausführung zu beschleunigen. Daher würde ein Tool, das alle unterstützenden Informationen einsehen und sowohl technische als auch organisatorische Daten schnell zusammenfassen sowie nächste Schritte vorschlagen kann, die Produktivität des Teams steigern. Wir konzentrieren uns darauf, LLMs zu verwenden, um drei verschiedene Ergebnisse zu generieren – eines mit Schwerpunkt auf technischen Details, eines mit organisatorischen Details und eines mit Empfehlungen zur Aufgabenzuweisung.
Zur Untersuchung dieser Aufgaben haben wir die interne Fehlerdatenbank von NVIDIA, NVBugs, verwendet. Diese Datenbank wird für die Fehlerberichterstattung, -verfolgung und -behebung sowie die allgemeine Aufgaben- und Funktionsverfolgung im gesamten Unternehmen verwendet. Wir gehen davon aus, dass ChipNeMo-Modelle bei dieser Aufgabe gute Ergebnisse erzielen, da der DAPT-Datensatz eine große Menge an Fehlerdaten enthielt. Darüber hinaus haben wir für diese Aufgabe einen domänenspezifischen SFT-Datensatz erstellt, der Beispiele für die Aufgaben zur Fehlerzusammenfassung und Aufgabenzuweisung enthält.
Fehlerbeschreibungen enthalten häufig große Ausschnitte von Protokolldateien oder Code-Dumps sowie lange Kommentarverläufe. In solchen Fällen ist der Fehlertext zu groß für unsere LLM-Kontextfenster. Um dies zu umgehen, haben wir zwei Lösungen implementiert. Erstens haben wir lange Pfadnamen gefunden und durch kürzere Aliase ersetzt, damit das Modell Pfade verknüpfen kann, die an mehreren Stellen im Fehler auftreten, ohne die gesamte Zeichenfolge verarbeiten zu müssen. Zweitens haben wir die Zusammenfassungsaufgabe in eine inkrementelle Aufgabe aufgeteilt, bei der das Modell Daten aus mehreren Zusammenfassungs- und Fehlerdatenblöcken sammeln muss. Wir verwenden einen hierarchischen Ansatz, bei dem der Fehler zuerst in Blöcke aufgeteilt wird, die in das Kontextfenster passen. Diese Blöcke werden dann zusammengefasst und die Zusammenfassungen werden gesammelt und dann in Blöcke aufgeteilt. Dieser Prozess wird wiederholt, bis der gesamte Satz von Zusammenfassungen in ein einzelnes Kontextfenster passt und eine einzelne Zusammenfassung generiert wird. Wir verwenden denselben Ansatz unabhängig vom für die Zusammenfassung verwendeten LLM.
Dieses Dokument ist auf Arxiv unter der CC 4.0-Lizenz verfügbar .








