



































Jan 01, 1970
1,593 leituras
Por que os Vision Transformers estão se concentrando em fundos chatos?
Muito longo; Para ler
Os Vision Transformers (ViTs) ganharam popularidade para tarefas relacionadas a imagens, mas exibem um comportamento estranho: focando em manchas de fundo sem importância em vez dos assuntos principais nas imagens. Os pesquisadores descobriram que uma pequena fração de tokens de patch com normas L2 anormalmente altas causa esses picos de atenção. Eles levantam a hipótese de que os ViTs reciclam patches com pouca informação para armazenar informações globais da imagem, levando a esse comportamento. Para corrigir isso, eles propõem adicionar tokens de “registro” para fornecer armazenamento dedicado, resultando em mapas de atenção mais suaves, melhor desempenho e habilidades aprimoradas de descoberta de objetos. Este estudo destaca a necessidade de pesquisas contínuas sobre artefatos de modelos para aprimorar as capacidades do transformador.
Os transformadores se tornaram o modelo de arquitetura preferido para muitas tarefas de visão. Os Vision Transformers (ViTs) são especialmente populares. Eles aplicam o transformador diretamente às sequências de patches de imagem. Os ViTs agora correspondem ou excedem os CNNs em benchmarks como classificação de imagens. No entanto, pesquisadores do Meta e do INRIA identificaram alguns artefatos estranhos no funcionamento interno dos ViTs.
Neste post, vamos nos aprofundar em um
Os misteriosos picos de atenção
Muitos trabalhos anteriores elogiaram os transformadores de visão por produzirem mapas de atenção suaves e interpretáveis. Isso nos permite ver em quais partes da imagem o modelo está focando.
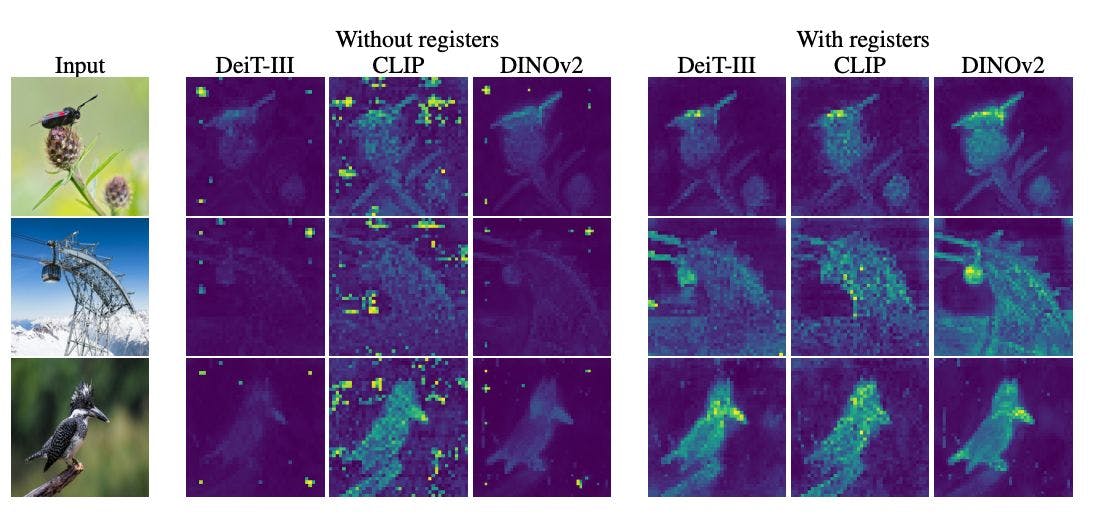
Estranhamente, muitas variantes do ViT mostram picos de atenção em manchas de fundo aleatórias e não informativas. Por que esses modelos estão focando tanto em elementos de fundo chatos e sem importância, em vez de nos assuntos principais dessas imagens?
Ao visualizar mapas de atenção entre modelos e criar imagens como a acima, os pesquisadores mostram definitivamente que isso acontece em versões supervisionadas como DeiT e CLIP, juntamente com modelos autossupervisionados mais recentes, como DINOv2.
Claramente, algo está fazendo com que os modelos se concentrem inexplicavelmente no ruído de fundo. Mas o que?
Rastreando a causa: tokens atípicos de alta norma
Ao investigar numericamente as incorporações de saída, os autores identificaram a causa raiz. Uma pequena fração (cerca de 2%) dos tokens de patch tem normas L2 anormalmente altas, tornando-os extremos.
No contexto das redes neurais, os pesos e vieses dos neurônios podem ser representados como vetores. A norma L2 (também conhecida como norma euclidiana) de um vetor é uma medida de sua magnitude e é calculada como a raiz quadrada da soma dos quadrados de seus elementos.
Quando dizemos que um vetor (por exemplo, pesos de um neurônio ou camada) tem uma “norma L2 anormalmente alta”, isso significa que a magnitude ou comprimento desse vetor é extraordinariamente grande em comparação com o que é esperado ou típico em um determinado contexto.
Normas L2 altas em redes neurais podem ser indicativas de alguns problemas:
Overfitting : se o modelo se ajustar muito aos dados de treinamento e capturar ruído, os pesos poderão se tornar muito grandes. Técnicas de regularização como a regularização L2 penalizam grandes pesos para mitigar isso.
Instabilidade Numérica : Pesos muito grandes ou muito pequenos podem causar problemas numéricos, levando à instabilidade do modelo.
Generalização deficiente : Normas L2 altas também podem indicar que o modelo pode não generalizar bem para dados novos e não vistos.
O que isso significa em inglês simples? Imagine que você está tentando equilibrar uma gangorra e tem pesos (ou sacos de areia) de vários tamanhos para colocar em cada lado. O tamanho de cada bolsa representa quanta influência ou importância ela tem no equilíbrio da gangorra. Agora, se uma dessas sacolas for anormalmente grande (tem uma “norma L2” alta), significa que a sacola está influenciando demais o equilíbrio.
No contexto de uma rede eural , se uma parte dela tiver uma influência anormalmente elevada (norma L2 elevada), poderá ofuscar outras partes importantes, o que pode levar a decisões erradas ou à dependência excessiva de características específicas. Isso não é o ideal, e muitas vezes tentamos ajustar a máquina para garantir que nenhuma peça tenha muita influência indevida.
Esses tokens de alta norma correspondem diretamente aos picos nos mapas de atenção. Portanto, os modelos estão destacando seletivamente essas manchas por razões desconhecidas.
Experimentos adicionais revelam:
- Os outliers só aparecem durante o treinamento de modelos suficientemente grandes.
- Eles surgem na metade do treinamento.
- Eles ocorrem em manchas altamente semelhantes aos seus vizinhos, sugerindo redundância.
Além disso, embora os valores discrepantes retenham menos informações sobre o patch original, eles são mais preditivos da categoria completa da imagem.
Esta evidência aponta para uma teoria intrigante...
A hipótese da reciclagem
Os autores levantam a hipótese de que, à medida que os modelos treinam em grandes conjuntos de dados como o ImageNet-22K, eles aprendem a identificar patches com pouca informação cujos valores podem ser descartados sem perder a semântica da imagem.
O modelo então recicla esses patches para armazenar informações globais temporárias sobre a imagem completa, descartando detalhes locais irrelevantes. Isso permite o processamento eficiente de recursos internos.
No entanto, esta reciclagem causa efeitos colaterais indesejáveis:
- Perda de detalhes originais do patch, prejudicando tarefas densas como segmentação
- Mapas de atenção pontiagudos que são difíceis de interpretar
- Incompatibilidade com métodos de descoberta de objetos
Portanto, embora esse comportamento surja naturalmente, ele traz consequências negativas.
Consertando ViTs com registros explícitos
Para aliviar os patches reciclados, os pesquisadores propõem fornecer armazenamento dedicado aos modelos, adicionando tokens de “registro” à sequência. Isso fornece espaço temporário para cálculos internos, evitando o sequestro de incorporações aleatórias de patches.
Notavelmente, esse ajuste simples funciona muito bem.
Modelos treinados com registros mostram:
- Mapas de atenção mais suaves e semanticamente significativos
- Pequenos aumentos de desempenho em vários benchmarks
- Habilidades de descoberta de objetos bastante aprimoradas
Os registros dão ao mecanismo de reciclagem um local adequado, eliminando seus efeitos colaterais desagradáveis. Apenas uma pequena mudança arquitetônica proporciona ganhos visíveis.
Principais conclusões
Este estudo intrigante fornece vários insights valiosos:
- Os transformadores de visão desenvolvem comportamentos imprevistos, como reciclagem de patches para armazenamento
- Adicionar registros fornece espaço temporário, evitando efeitos colaterais indesejados
- Esta correção simples melhora os mapas de atenção e o desempenho downstream
- Provavelmente existem outros artefatos de modelo não descobertos para investigar
Espiar dentro das caixas pretas das redes neurais revela muito sobre seu funcionamento interno, orientando melhorias incrementais. Mais trabalhos como esse aumentarão continuamente as capacidades do transformador.
O rápido ritmo de progresso nos transformadores de visão não mostra sinais de desaceleração. Vivemos em tempos excitantes!
Também publicado aqui.
L O A D I N G
. . . comments & more!
. . . comments & more!



