



































Jan 01, 1970
Pourquoi les transformateurs de vision se concentrent-ils sur des arrière-plans ennuyeux ? par@mikeyoung44
1,593 lectures
Pourquoi les transformateurs de vision se concentrent-ils sur des arrière-plans ennuyeux ?
Trop long; Pour lire
Les transformateurs de vision (ViT) ont gagné en popularité pour les tâches liées aux images, mais présentent un comportement étrange : ils se concentrent sur des zones d'arrière-plan sans importance au lieu des sujets principaux des images. Les chercheurs ont découvert qu’une petite fraction des jetons de correctifs avec des normes L2 anormalement élevées provoquent ces pics d’attention. Ils émettent l’hypothèse que les ViT recyclent les correctifs à faible information pour stocker des informations d’image globales, conduisant à ce comportement. Pour résoudre ce problème, ils proposent d'ajouter des jetons de « registre » pour fournir un stockage dédié, ce qui se traduit par des cartes d'attention plus fluides, de meilleures performances et des capacités de découverte d'objets améliorées. Cette étude met en évidence la nécessité de recherches continues sur les artefacts de modèles pour faire progresser les capacités des transformateurs.
Les transformateurs sont devenus l’architecture modèle de choix pour de nombreuses tâches de vision. Les transformateurs de vision (ViT) sont particulièrement populaires. Ils appliquent le transformateur directement aux séquences de patchs d'image. Les ViT égalent ou dépassent désormais les CNN sur des critères tels que la classification des images. Cependant, des chercheurs de Meta et de l’INRIA ont identifié d’étranges artefacts dans le fonctionnement interne des ViT.
Dans cet article, nous allons approfondir un
Les mystérieux pics d’attention
De nombreux travaux antérieurs ont fait l’éloge des transformateurs de vision pour produire des cartes d’attention fluides et interprétables. Ceux-ci nous permettent de voir sur quelles parties de l’image le modèle se concentre.
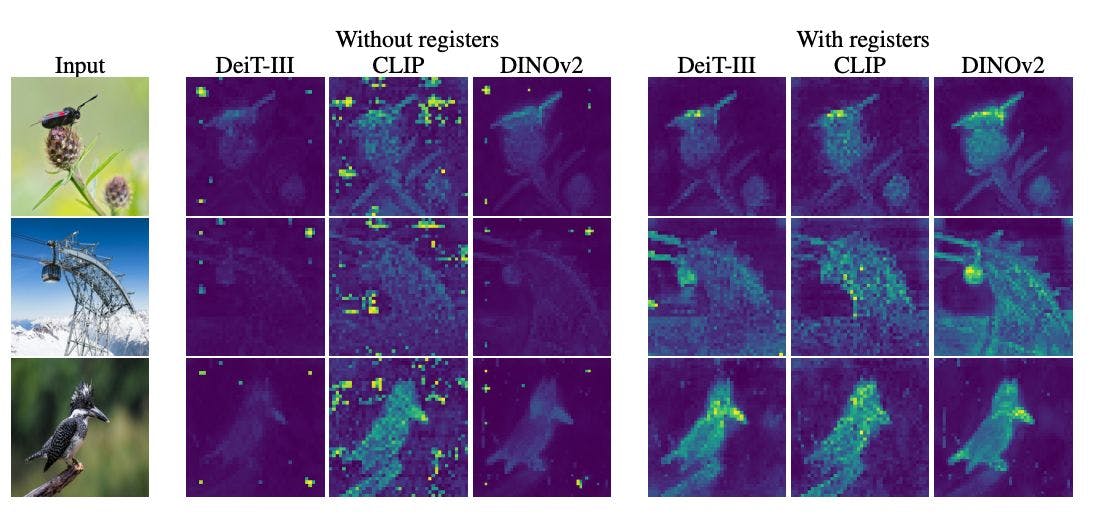
Curieusement, de nombreuses variantes de ViT affichent des pics d'attention élevés sur des correctifs d'arrière-plan aléatoires et non informatifs. Pourquoi ces modèles se concentrent-ils autant sur des éléments d’arrière-plan ennuyeux et sans importance au lieu des sujets principaux de ces images ?
En visualisant des cartes d'attention à travers les modèles et en créant des images comme celle ci-dessus, les chercheurs montrent définitivement que cela se produit dans des versions supervisées comme DeiT et CLIP, ainsi que dans de nouveaux modèles auto-supervisés comme DINOv2.
De toute évidence, quelque chose amène les modèles à se concentrer inexplicablement sur le bruit de fond. Mais quoi?
Rechercher la cause : jetons aberrants de haute qualité
En sondant numériquement les intégrations de sortie, les auteurs ont identifié la cause première. Une petite fraction (environ 2 %) des jetons de patch ont des normes L2 anormalement élevées, ce qui en fait des valeurs aberrantes extrêmes.
Dans le contexte des réseaux de neurones, les poids et biais des neurones peuvent être représentés sous forme de vecteurs. La norme L2 (également connue sous le nom de norme euclidienne) d'un vecteur est une mesure de sa grandeur et est calculée comme la racine carrée de la somme des carrés de ses éléments.
Lorsque nous disons qu'un vecteur (par exemple, le poids d'un neurone ou d'une couche) a une « norme L2 anormalement élevée », cela signifie que l'ampleur ou la longueur de ce vecteur est inhabituellement grande par rapport à ce qui est attendu ou typique dans le contexte donné.
Des normes L2 élevées dans les réseaux de neurones peuvent être révélatrices de quelques problèmes :
Surajustement : si le modèle s'adapte trop étroitement aux données d'entraînement et capture le bruit, les poids peuvent devenir très importants. Les techniques de régularisation comme la régularisation L2 pénalisent les poids importants pour atténuer cela.
Instabilité numérique : des poids très élevés ou très faibles peuvent entraîner des problèmes numériques, conduisant à une instabilité du modèle.
Mauvaise généralisation : des normes L2 élevées peuvent également indiquer que le modèle pourrait ne pas se généraliser correctement à de nouvelles données invisibles.
Qu’est-ce que cela signifie en anglais simple ? Imaginez que vous essayez d'équilibrer une balançoire et que vous avez des poids (ou des sacs de sable) de différentes tailles à placer de chaque côté. La taille de chaque sac représente l'influence ou l'importance qu'il a dans l'équilibre de la balançoire. Or, si l’un de ces sacs est anormalement grand (a une « norme L2 » élevée), cela signifie que le sac a trop d’influence sur la balance.
Dans le contexte d'un réseau neuronal , si une partie de celui-ci a une influence anormalement élevée (norme L2 élevée), elle peut éclipser d'autres parties importantes, ce qui peut conduire à de mauvaises décisions ou à une dépendance excessive à l'égard de fonctionnalités spécifiques. Ce n’est pas idéal et nous essayons souvent d’ajuster la machine pour nous assurer qu’aucune pièce n’a trop d’influence indue.
Ces jetons de norme élevée correspondent directement aux pics des cartes d’attention. Les modèles mettent donc en évidence ces correctifs de manière sélective pour des raisons inconnues.
Des expériences supplémentaires révèlent :
- Les valeurs aberrantes n'apparaissent que lors de la formation de modèles suffisamment grands.
- Ils émergent vers la moitié de la formation.
- Ils se trouvent sur des parcelles très similaires à leurs voisines, ce qui suggère une redondance.
De plus, même si les valeurs aberrantes conservent moins d’informations sur leur patch d’origine, elles sont plus prédictives de la catégorie d’image complète.
Ces preuves pointent vers une théorie intrigante...
L’hypothèse du recyclage
Les auteurs émettent l’hypothèse qu’à mesure que les modèles s’entraînent sur de grands ensembles de données comme ImageNet-22K, ils apprennent à identifier les correctifs à faible information dont les valeurs peuvent être ignorées sans perdre la sémantique de l’image.
Le modèle recycle ensuite ces intégrations de correctifs pour stocker des informations globales temporaires sur l'image complète, en supprimant les détails locaux non pertinents. Cela permet un traitement efficace des fonctionnalités internes.
Cependant, ce recyclage entraîne des effets secondaires indésirables :
- Perte des détails du patch d'origine, nuisant aux tâches denses comme la segmentation
- Des cartes d'attention pointues et difficiles à interpréter
- Incompatibilité avec les méthodes de découverte d'objets
Même si ce comportement apparaît naturellement, il a des conséquences négatives.
Correction des ViT avec des registres explicites
Pour alléger les correctifs recyclés, les chercheurs proposent de donner aux modèles un stockage dédié en ajoutant des jetons « registre » à la séquence. Cela fournit un espace de travail temporaire pour les calculs internes, empêchant ainsi le détournement d'intégrations de correctifs aléatoires.
Remarquablement, ce simple ajustement fonctionne très bien.
Les modèles entraînés avec des registres montrent :
- Des cartes d'attention plus fluides et plus significatives sur le plan sémantique
- Améliorations mineures des performances sur divers benchmarks
- Capacités de découverte d'objets considérablement améliorées
Les registres donnent au mécanisme de recyclage un véritable foyer, éliminant ainsi ses effets secondaires désagréables. Un simple petit changement architectural débloque des gains notables.
Points clés à retenir
Cette étude fascinante fournit plusieurs informations précieuses :
- Les transformateurs de vision développent des comportements imprévus comme le recyclage des correctifs pour le stockage
- L'ajout de registres donne un espace de travail temporaire, évitant ainsi les effets secondaires involontaires
- Ce correctif simple améliore les cartes d'attention et les performances en aval
- Il existe probablement d'autres artefacts de modèle non découverts à étudier
Un coup d’œil à l’intérieur des boîtes noires des réseaux neuronaux révèle beaucoup de choses sur leur fonctionnement interne, guidant des améliorations progressives. Davantage de travaux comme celui-ci feront progresser progressivement les capacités des transformateurs.
Le rythme rapide des progrès en matière de transformation de la vision ne montre aucun signe de ralentissement. Nous vivons des moments excitants!
Également publié ici.
L O A D I N G
. . . comments & more!
. . . comments & more!



