



































Jan 01, 1970
1,593 रीडिंग
विज़न ट्रांसफॉर्मर उबाऊ पृष्ठभूमि पर ध्यान क्यों केंद्रित कर रहे हैं?
बहुत लंबा; पढ़ने के लिए
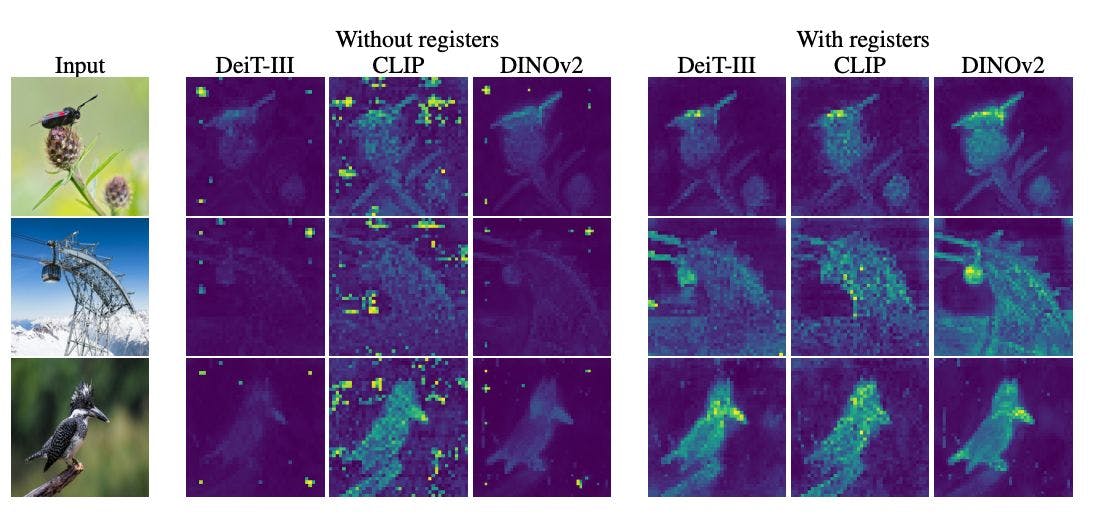
विज़न ट्रांसफॉर्मर्स (वीआईटी) ने छवि-संबंधित कार्यों के लिए लोकप्रियता हासिल की है, लेकिन अजीब व्यवहार प्रदर्शित करते हैं: छवियों में मुख्य विषयों के बजाय महत्वहीन पृष्ठभूमि पैच पर ध्यान केंद्रित करना। शोधकर्ताओं ने पाया कि असामान्य रूप से उच्च L2 मानदंडों वाले पैच टोकन का एक छोटा सा अंश ध्यान में इन स्पाइक्स का कारण बनता है। उनका अनुमान है कि वीआईटी वैश्विक छवि जानकारी संग्रहीत करने के लिए कम जानकारी वाले पैच को रीसायकल करता है, जिससे यह व्यवहार होता है। इसे ठीक करने के लिए, वे समर्पित भंडारण प्रदान करने के लिए "रजिस्टर" टोकन जोड़ने का प्रस्ताव करते हैं, जिसके परिणामस्वरूप सहज ध्यान मानचित्र, बेहतर प्रदर्शन और बेहतर वस्तु खोज क्षमताएं प्राप्त होती हैं। यह अध्ययन ट्रांसफार्मर क्षमताओं को आगे बढ़ाने के लिए मॉडल कलाकृतियों में चल रहे शोध की आवश्यकता पर प्रकाश डालता है।
ट्रांसफॉर्मर कई विज़न कार्यों के लिए पसंद का मॉडल आर्किटेक्चर बन गए हैं। विज़न ट्रांसफॉर्मर (वीआईटी) विशेष रूप से लोकप्रिय हैं। वे ट्रांसफार्मर को सीधे छवि पैच के अनुक्रम पर लागू करते हैं। वीआईटी अब छवि वर्गीकरण जैसे बेंचमार्क पर सीएनएन से मेल खाते हैं या उससे आगे निकल जाते हैं। हालाँकि, मेटा और आईएनआरआईए के शोधकर्ताओं ने वीआईटी की आंतरिक कार्यप्रणाली में कुछ अजीब कलाकृतियों की पहचान की है।
इस पोस्ट में, हम गहराई से जानेंगे
रहस्यमय ध्यान स्पाइक्स
बहुत पहले के कार्यों में सहज, व्याख्या योग्य ध्यान मानचित्र तैयार करने के लिए दृष्टि ट्रांसफार्मर की प्रशंसा की गई है। इससे हमें पता चलता है कि मॉडल छवि के किन हिस्सों पर ध्यान केंद्रित कर रहा है।
अजीब बात है कि, कई ViT वेरिएंट यादृच्छिक, बिना सूचना वाले पृष्ठभूमि पैच पर उच्च ध्यान देने वाले स्पाइक्स दिखाते हैं। ये मॉडल इन छवियों के मुख्य विषयों के बजाय उबाऊ, महत्वहीन पृष्ठभूमि तत्वों पर इतना ध्यान क्यों केंद्रित कर रहे हैं?
सभी मॉडलों में ध्यान मानचित्रों की कल्पना करके और उपरोक्त जैसी छवियां बनाकर, शोधकर्ता निश्चित रूप से दिखाते हैं कि यह DeiT और CLIP जैसे पर्यवेक्षित संस्करणों के साथ-साथ DINOv2 जैसे नए स्व-पर्यवेक्षित मॉडल में भी होता है।
स्पष्ट रूप से, कुछ चीज़ों के कारण मॉडल बेवजह पृष्ठभूमि शोर पर ध्यान केंद्रित कर रहे हैं। क्या पर?
कारण का पता लगाना: उच्च-मानदंड बाह्य टोकन
आउटपुट एम्बेडिंग की संख्यात्मक जांच करके, लेखकों ने मूल कारण की पहचान की। पैच टोकन के एक छोटे से हिस्से (लगभग 2%) में असामान्य रूप से उच्च L2 मानदंड होते हैं, जो उन्हें अत्यधिक आउटलेयर बनाते हैं।
तंत्रिका नेटवर्क के संदर्भ में, न्यूरॉन्स के वजन और पूर्वाग्रह को वैक्टर के रूप में दर्शाया जा सकता है। एक वेक्टर का L2 मानदंड (यूक्लिडियन मानदंड के रूप में भी जाना जाता है) इसके परिमाण का एक माप है और इसकी गणना इसके तत्वों के वर्गों के योग के वर्गमूल के रूप में की जाती है।
जब हम कहते हैं कि एक वेक्टर (उदाहरण के लिए, एक न्यूरॉन या परत का वजन) में "असामान्य रूप से उच्च L2 मानदंड" होता है, तो इसका मतलब है कि उस वेक्टर का परिमाण या लंबाई दिए गए संदर्भ में अपेक्षित या विशिष्ट की तुलना में असामान्य रूप से बड़ी है।
तंत्रिका नेटवर्क में उच्च L2 मानदंड कुछ मुद्दों का संकेत हो सकते हैं:
ओवरफिटिंग : यदि मॉडल प्रशिक्षण डेटा के बहुत करीब फिट हो रहा है और शोर को कैप्चर कर रहा है, तो वजन बहुत बड़ा हो सकता है। एल2 नियमितीकरण जैसी नियमितीकरण तकनीकें इसे कम करने के लिए बड़े भार को दंडित करती हैं।
संख्यात्मक अस्थिरता : बहुत बड़ा या बहुत छोटा वजन संख्यात्मक समस्याओं का कारण बन सकता है, जिससे मॉडल अस्थिरता हो सकती है।
ख़राब सामान्यीकरण : उच्च L2 मानदंड यह भी संकेत दे सकते हैं कि मॉडल नए, अनदेखे डेटा को अच्छी तरह से सामान्यीकृत नहीं कर सकता है।
सरल अंग्रेज़ी में इसका क्या अर्थ है? कल्पना कीजिए कि आप एक सी-सॉ को संतुलित करने का प्रयास कर रहे हैं, और आपके पास दोनों तरफ रखने के लिए विभिन्न आकारों के वजन (या रेत के बैग) हैं। प्रत्येक बैग का आकार दर्शाता है कि सी-सॉ को संतुलित करने में इसका कितना प्रभाव या महत्व है। अब, यदि उनमें से एक बैग असामान्य रूप से बड़ा है (उच्च "एल 2 मानक" है), तो इसका मतलब है कि बैग संतुलन पर बहुत अधिक प्रभाव डाल रहा है।
यूराल नेटवर्क के संदर्भ में, यदि इसके एक हिस्से में असामान्य रूप से उच्च प्रभाव (उच्च एल 2 मानदंड) है, तो यह अन्य महत्वपूर्ण हिस्सों पर हावी हो सकता है, जिससे गलत निर्णय या विशिष्ट सुविधाओं पर अत्यधिक निर्भरता हो सकती है। यह आदर्श नहीं है, और हम अक्सर यह सुनिश्चित करने के लिए मशीन को समायोजित करने का प्रयास करते हैं कि किसी एक हिस्से पर बहुत अधिक अनुचित प्रभाव न पड़े।
ये उच्च-मानदंड टोकन सीधे ध्यान मानचित्रों में स्पाइक्स से मेल खाते हैं। इसलिए मॉडल अज्ञात कारणों से इन पैच को चुनिंदा रूप से उजागर कर रहे हैं।
अतिरिक्त प्रयोगों से पता चलता है:
- आउटलेयर केवल पर्याप्त बड़े मॉडलों के प्रशिक्षण के दौरान दिखाई देते हैं।
- वे प्रशिक्षण के लगभग आधे रास्ते से उभर कर सामने आते हैं।
- वे अपने पड़ोसियों के समान पैच पर पाए जाते हैं, जो अतिरेक का संकेत देते हैं।
इसके अलावा, जबकि आउटलेर्स अपने मूल पैच के बारे में कम जानकारी रखते हैं, वे पूर्ण छवि श्रेणी के बारे में अधिक पूर्वानुमानित होते हैं।
यह साक्ष्य एक दिलचस्प सिद्धांत की ओर इशारा करता है...
पुनर्चक्रण परिकल्पना
लेखकों का अनुमान है कि जैसे-जैसे मॉडल ImageNet-22K जैसे बड़े डेटासेट पर प्रशिक्षण लेते हैं, वे कम जानकारी वाले पैच की पहचान करना सीखते हैं जिनके मूल्यों को छवि शब्दार्थ को खोए बिना खारिज किया जा सकता है।
फिर मॉडल पूरी छवि के बारे में अस्थायी वैश्विक जानकारी संग्रहीत करने के लिए उन पैच एम्बेडिंग को पुन: चक्रित करता है, अप्रासंगिक स्थानीय विवरणों को हटा देता है। यह कुशल आंतरिक सुविधा प्रसंस्करण की अनुमति देता है।
हालाँकि, यह पुनर्चक्रण अवांछनीय दुष्प्रभावों का कारण बनता है:
- मूल पैच विवरण का नुकसान, विभाजन जैसे गहन कार्यों को नुकसान पहुंचा रहा है
- कांटेदार ध्यान मानचित्र जिनकी व्याख्या करना कठिन है
- वस्तु खोज विधियों के साथ असंगति
इसलिए जबकि यह व्यवहार स्वाभाविक रूप से उभरता है, इसके नकारात्मक परिणाम होते हैं।
स्पष्ट रजिस्टरों के साथ वीआईटी को ठीक करना
पुनर्नवीनीकरण पैच को कम करने के लिए, शोधकर्ताओं ने अनुक्रम में "रजिस्टर" टोकन जोड़कर मॉडल को समर्पित भंडारण देने का प्रस्ताव दिया है। यह आंतरिक गणनाओं के लिए अस्थायी स्क्रैच स्थान प्रदान करता है, जिससे यादृच्छिक पैच एम्बेडिंग के अपहरण को रोका जा सकता है।
उल्लेखनीय रूप से, यह सरल बदलाव बहुत अच्छी तरह से काम करता है।
रजिस्टरों से प्रशिक्षित मॉडल दिखाते हैं:
- अधिक सहज, अधिक अर्थपूर्ण ध्यान मानचित्र
- विभिन्न बेंचमार्क पर मामूली प्रदर्शन बढ़ जाता है
- वस्तु खोज क्षमताओं में काफी सुधार हुआ
रजिस्टर रीसाइक्लिंग तंत्र को एक उचित स्थान देते हैं, जिससे इसके बुरे दुष्प्रभाव समाप्त हो जाते हैं। बस एक छोटा सा वास्तुशिल्प परिवर्तन ध्यान देने योग्य लाभ खोलता है।
चाबी छीनना
यह दिलचस्प अध्ययन कई मूल्यवान अंतर्दृष्टि प्रदान करता है:
- विज़न ट्रांसफार्मर भंडारण के लिए रीसाइक्लिंग पैच जैसे अप्रत्याशित व्यवहार विकसित करते हैं
- रजिस्टर जोड़ने से अस्थायी स्क्रैच स्पेस मिलता है, जिससे अनपेक्षित दुष्प्रभावों को रोका जा सकता है
- यह सरल समाधान ध्यान मानचित्र और डाउनस्ट्रीम प्रदर्शन को बेहतर बनाता है
- जांच के लिए अन्य अनदेखे मॉडल कलाकृतियां होने की संभावना है
तंत्रिका नेटवर्क ब्लैक बॉक्स के अंदर झाँकने से उनके आंतरिक कामकाज के बारे में बहुत कुछ पता चलता है, जो वृद्धिशील सुधारों का मार्गदर्शन करता है। इस तरह के और अधिक कार्य ट्रांसफार्मर क्षमताओं को लगातार आगे बढ़ाएंगे।
दृष्टि ट्रांसफार्मर में प्रगति की तीव्र गति धीमी होने का कोई संकेत नहीं दिखाती है। हम रोमांचक समय में रहते हैं!
L O A D I N G
. . . comments & more!
. . . comments & more!



