





































Jan 01, 1970
1,593 Lesungen
Warum konzentrieren sich Vision Transformers auf langweilige Hintergründe?
Zu lang; Lesen
Vision Transformers (ViTs) erfreuen sich zunehmender Beliebtheit bei bildbezogenen Aufgaben, zeigen jedoch ein seltsames Verhalten: Sie konzentrieren sich auf unwichtige Hintergrundbereiche statt auf die Hauptmotive in Bildern. Forscher fanden heraus, dass ein kleiner Teil der Patch-Tokens mit ungewöhnlich hohen L2-Normen diese Aufmerksamkeitsspitzen verursacht. Sie gehen davon aus, dass ViTs Patches mit geringem Informationsgehalt recyceln, um globale Bildinformationen zu speichern, was zu diesem Verhalten führt. Um das Problem zu beheben, schlagen sie das Hinzufügen von „Registrierungs“-Tokens vor, um dedizierten Speicher bereitzustellen, was zu reibungsloseren Aufmerksamkeitskarten, besserer Leistung und verbesserten Objekterkennungsfähigkeiten führt. Diese Studie unterstreicht die Notwendigkeit einer fortlaufenden Erforschung von Modellartefakten, um die Transformatorfähigkeiten zu verbessern.
Für viele Vision-Aufgaben sind Transformatoren zur Modellarchitektur der Wahl geworden. Besonders beliebt sind Vision Transformers (ViTs). Sie wenden den Transformator direkt auf Sequenzen von Bildfeldern an. ViTs erreichen oder übertreffen jetzt CNNs bei Benchmarks wie der Bildklassifizierung. Forscher von Meta und INRIA haben jedoch einige seltsame Artefakte im Innenleben von ViTs identifiziert.
In diesem Beitrag werden wir uns eingehend mit einem befassen
Die mysteriösen Aufmerksamkeitsspitzen
In vielen früheren Arbeiten wurden Vision Transformer für die Erstellung reibungsloser, interpretierbarer Aufmerksamkeitskarten gelobt. Dadurch können wir einen Blick darauf werfen, auf welche Teile des Bildes sich das Modell konzentriert.
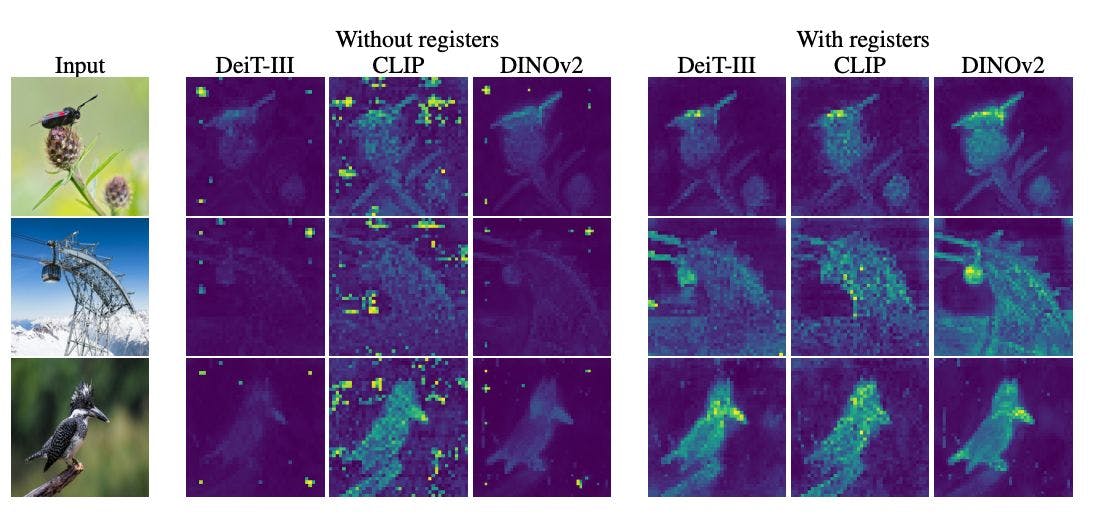
Seltsamerweise zeigen viele ViT-Varianten Spitzen hoher Aufmerksamkeit auf zufälligen, nicht informativen Hintergrund-Patches. Warum konzentrieren sich diese Models so sehr auf langweilige, unwichtige Hintergrundelemente statt auf die Hauptmotive dieser Bilder?
Durch die Visualisierung von Aufmerksamkeitskarten über Modelle hinweg und die Erstellung von Bildern wie dem oben gezeigten zeigen die Forscher eindeutig, dass dies in überwachten Versionen wie DeiT und CLIP sowie in neueren selbstüberwachten Modellen wie DINOv2 geschieht.
Offensichtlich führt irgendetwas dazu, dass sich Modelle aus unerklärlichen Gründen auf Hintergrundgeräusche konzentrieren. Aber was?
Der Ursache auf der Spur: High-Norm-Ausreißer-Token
Durch numerische Untersuchung der Ausgabeeinbettungen identifizierten die Autoren die Grundursache. Ein kleiner Teil (etwa 2 %) der Patch-Token weist ungewöhnlich hohe L2-Normen auf, was sie zu extremen Ausreißern macht.
Im Kontext neuronaler Netze können die Gewichte und Bias der Neuronen als Vektoren dargestellt werden. Die L2-Norm (auch als euklidische Norm bekannt) eines Vektors ist ein Maß für seine Größe und wird als Quadratwurzel der Summe der Quadrate seiner Elemente berechnet.
Wenn wir sagen, dass ein Vektor (z. B. Gewichtungen eines Neurons oder einer Schicht) eine „ungewöhnlich hohe L2-Norm“ aufweist, bedeutet dies, dass die Größe oder Länge dieses Vektors im Vergleich zu dem, was im gegebenen Kontext erwartet oder typisch ist, ungewöhnlich groß ist.
Hohe L2-Normen in neuronalen Netzen können auf einige Probleme hinweisen:
Überanpassung : Wenn das Modell zu genau an die Trainingsdaten angepasst ist und Rauschen erfasst, können die Gewichte sehr groß werden. Regularisierungstechniken wie die L2-Regularisierung bestrafen große Gewichte, um dies zu mildern.
Numerische Instabilität : Sehr große oder sehr kleine Gewichte können numerische Probleme verursachen und zu Modellinstabilität führen.
Schlechte Generalisierung : Hohe L2-Normen können auch darauf hindeuten, dass das Modell möglicherweise nicht gut auf neue, unbekannte Daten generalisiert.
Was bedeutet das im Klartext? Stellen Sie sich vor, Sie versuchen, eine Wippe zu balancieren, und Sie haben Gewichte (oder Sandsäcke) unterschiedlicher Größe, die Sie auf beiden Seiten platzieren können. Die Größe jeder Tasche gibt an, wie viel Einfluss oder Bedeutung sie beim Ausbalancieren der Wippe hat. Wenn nun einer dieser Beutel ungewöhnlich groß ist (eine hohe „L2-Norm“ aufweist), bedeutet das, dass der Beutel einen zu großen Einfluss auf das Gleichgewicht hat.
Wenn im Kontext eines neuronalen Netzwerks ein Teil davon einen ungewöhnlich hohen Einfluss hat (hohe L2-Norm), kann dies andere wichtige Teile überschatten, was zu falschen Entscheidungen oder einer übermäßigen Abhängigkeit von bestimmten Merkmalen führen kann. Das ist nicht ideal und wir versuchen oft, die Maschine so einzustellen, dass kein einzelnes Teil zu viel Einfluss hat.
Diese High-Norm-Token entsprechen direkt den Spitzen in den Aufmerksamkeitskarten. Daher heben die Modelle diese Flecken aus unbekannten Gründen selektiv hervor.
Zusätzliche Experimente zeigen:
- Die Ausreißer treten nur beim Training ausreichend großer Modelle auf.
- Sie tauchen etwa in der Mitte des Trainings auf.
- Sie treten auf Flecken auf, die ihren Nachbarn sehr ähnlich sind, was auf Redundanz hindeutet.
Darüber hinaus behalten die Ausreißer zwar weniger Informationen über ihren ursprünglichen Patch bei, sind aber aussagekräftiger für die vollständige Bildkategorie.
Diese Beweise deuten auf eine faszinierende Theorie hin ...
Die Recycling-Hypothese
Die Autoren gehen davon aus, dass Modelle beim Training mit großen Datensätzen wie ImageNet-22K lernen, Patches mit geringen Informationen zu identifizieren, deren Werte verworfen werden können, ohne dass die Bildsemantik verloren geht.
Anschließend recycelt das Modell diese Patch-Einbettungen, um temporäre globale Informationen über das gesamte Bild zu speichern, wobei irrelevante lokale Details verworfen werden. Dies ermöglicht eine effiziente interne Merkmalsverarbeitung.
Dieses Recycling verursacht jedoch unerwünschte Nebenwirkungen:
- Verlust der ursprünglichen Patch-Details, wodurch dichte Aufgaben wie die Segmentierung beeinträchtigt werden
- Stachelige Aufmerksamkeitskarten, die schwer zu interpretieren sind
- Inkompatibilität mit Objekterkennungsmethoden
Obwohl dieses Verhalten natürlich auftritt, hat es negative Folgen.
ViTs mit expliziten Registern reparieren
Um die recycelten Patches zu verringern, schlagen die Forscher vor, den Modellen dedizierten Speicher zu geben, indem sie der Sequenz „Register“-Tokens hinzufügen. Dies stellt temporären Arbeitsspeicher für interne Berechnungen bereit und verhindert so die Übernahme zufälliger Patch-Einbettungen.
Bemerkenswerterweise funktioniert diese einfache Optimierung sehr gut.
Mit Registern trainierte Modelle zeigen:
- Glattere, semantisch aussagekräftigere Aufmerksamkeitskarten
- Kleinere Leistungssteigerungen bei verschiedenen Benchmarks
- Deutlich verbesserte Fähigkeiten zur Objekterkennung
Die Register geben dem Recyclingmechanismus ein richtiges Zuhause und eliminieren seine unangenehmen Nebenwirkungen. Schon eine kleine architektonische Änderung bringt spürbare Vorteile mit sich.
Die zentralen Thesen
Diese faszinierende Studie liefert mehrere wertvolle Erkenntnisse:
- Vision-Transformer entwickeln unvorhergesehene Verhaltensweisen wie das Recycling von Patches zur Lagerung
- Durch das Hinzufügen von Registern wird temporärer Arbeitsraum geschaffen, wodurch unbeabsichtigte Nebenwirkungen vermieden werden
- Dieser einfache Fix verbessert die Aufmerksamkeitskarten und die Downstream-Leistung
- Es gibt wahrscheinlich noch andere unentdeckte Modellartefakte, die untersucht werden müssen
Ein Blick in die Blackboxen neuronaler Netze verrät viel über deren Innenleben und leitet so schrittweise Verbesserungen ab. Weitere Arbeiten wie diese werden die Transformatorfähigkeiten stetig verbessern.
Der rasante Fortschritt bei Vision Transformern zeigt keine Anzeichen einer Verlangsamung. Wir leben in aufregenden Zeiten!
Auch hier veröffentlicht.
L O A D I N G
. . . comments & more!
. . . comments & more!



