














































Jan 01, 1970
Sách nhập môn về Tối ưu hóa suy luận mô hình ngôn ngữ lớn (LLM): 2. Giới thiệu về bộ tăng tốc trí tuệ nhân tạo (AI) từ tác giả@mandliya
750 lượt đọc
Sách nhập môn về Tối ưu hóa suy luận mô hình ngôn ngữ lớn (LLM): 2. Giới thiệu về bộ tăng tốc trí tuệ nhân tạo (AI)
dài quá đọc không nổi
Bài đăng này khám phá các công cụ tăng tốc AI và tác động của chúng đến việc triển khai Mô hình ngôn ngữ lớn (LLM) ở quy mô lớn.Khám phá các công cụ tăng tốc AI và tác động của chúng đến việc triển khai Mô hình ngôn ngữ lớn (LLM) ở quy mô lớn.
Các bài viết trong loạt bài này :
Bài học cơ bản về Tối ưu hóa suy luận mô hình ngôn ngữ lớn (LLM): 1. Bối cảnh và công thức vấn đề
Sách nhập môn về Tối ưu hóa suy luận mô hình ngôn ngữ lớn (LLM): 2. Giới thiệu về bộ tăng tốc trí tuệ nhân tạo (AI) (bài đăng này)
Trong bài đăng trước, chúng tôi đã thảo luận về những thách thức của suy luận Mô hình ngôn ngữ lớn (LLM), chẳng hạn như độ trễ cao, tiêu thụ tài nguyên chuyên sâu và các vấn đề về khả năng mở rộng. Giải quyết các vấn đề này hiệu quả thường đòi hỏi sự hỗ trợ phần cứng phù hợp. Bài đăng này đi sâu vào các bộ tăng tốc AI—phần cứng chuyên dụng được thiết kế để nâng cao hiệu suất của khối lượng công việc AI, bao gồm suy luận LLM—làm nổi bật kiến trúc, các loại chính và tác động của chúng đối với việc triển khai LLM ở quy mô lớn.
Tại sao lại là AI Accelerators?
Nếu bạn từng thắc mắc làm thế nào các công ty như OpenAI và Google có thể chạy các mô hình ngôn ngữ khổng lồ này phục vụ hàng triệu người dùng cùng lúc, thì bí mật nằm ở phần cứng chuyên dụng được gọi là bộ tăng tốc AI. Trong khi CPU truyền thống xử lý tốt các tác vụ thông thường, chúng không được tối ưu hóa cho nhu cầu của khối lượng công việc AI. Ngược lại, bộ tăng tốc AI được xây dựng có mục đích cho các tác vụ AI, cung cấp khả năng truy cập dữ liệu tốc độ cao, khả năng xử lý song song và hỗ trợ số học có độ chính xác thấp. Bằng cách chuyển đổi tính toán sang bộ tăng tốc AI, các tổ chức có thể đạt được hiệu suất tăng đáng kể và giảm chi phí, đặc biệt là khi chạy các mô hình phức tạp như LLM. Hãy cùng khám phá một số loại bộ tăng tốc AI phổ biến và những lợi thế độc đáo của chúng đối với các khối lượng công việc này.
Các loại máy gia tốc AI
Bộ tăng tốc AI có nhiều dạng, mỗi dạng được thiết kế riêng cho các tác vụ và môi trường AI cụ thể. Ba loại chính là GPU, TPU và FPGA/ASIC, mỗi loại có các tính năng và ưu điểm riêng:
Bộ xử lý đồ họa (GPU)
Ban đầu được phát triển để dựng hình đồ họa, GPU đã trở thành một công cụ mạnh mẽ cho các tác vụ học sâu nhờ khả năng xử lý song song của chúng. Kiến trúc của chúng rất phù hợp cho các phép tính ma trận thông lượng cao, vốn rất cần thiết cho các tác vụ như suy luận LLM. GPU đặc biệt phổ biến trong các trung tâm dữ liệu để đào tạo và suy luận ở quy mô lớn. Các GPU như NVIDIA Tesla, AMD Radeon và Intel Xe được sử dụng rộng rãi trong cả môi trường đám mây và tại chỗ.
Bộ xử lý Tensor (TPU)
Google đã phát triển TPU dành riêng cho khối lượng công việc học sâu, với các tối ưu hóa cho đào tạo và suy luận dựa trên TensorFlow. TPU được thiết kế để tăng tốc các tác vụ AI quy mô lớn một cách hiệu quả, hỗ trợ nhiều ứng dụng của Google, bao gồm tìm kiếm và dịch thuật. Có sẵn thông qua Google Cloud, TPU cung cấp hiệu suất cao cho cả đào tạo và suy luận, khiến chúng trở thành lựa chọn ưu tiên cho người dùng TensorFlow.
Mảng cổng lập trình được (FPGA) / Mạch tích hợp ứng dụng cụ thể (ASIC)
FPGA và ASIC là hai loại bộ tăng tốc tùy chỉnh riêng biệt hỗ trợ các tác vụ AI cụ thể. FPGA có thể lập trình lại, cho phép chúng thích ứng với các mô hình và ứng dụng AI khác nhau, trong khi ASIC được xây dựng có mục đích cho các tác vụ cụ thể, mang lại hiệu quả tối đa cho các khối lượng công việc đó. Cả hai loại đều được sử dụng trong các trung tâm dữ liệu và tại biên, nơi độ trễ thấp và thông lượng cao là rất quan trọng. Ví dụ bao gồm Intel Arria và Xilinx Alveo (FPGA) và Edge TPU (ASIC) của Google.
Sự khác biệt chính giữa CPU và AI Accelerators
Kiến trúc riêng biệt của CPU và bộ tăng tốc AI khiến chúng phù hợp với nhiều loại khối lượng công việc khác nhau. Sau đây là so sánh một số tính năng quan trọng nhất:
- Kiến trúc : Trong khi CPU là bộ xử lý đa năng, bộ tăng tốc AI là phần cứng chuyên dụng được tối ưu hóa cho khối lượng công việc AI. CPU thường có ít lõi hơn nhưng tốc độ xung nhịp cao, khiến chúng trở nên lý tưởng cho các tác vụ đòi hỏi hiệu suất luồng đơn nhanh. Tuy nhiên, bộ tăng tốc AI có hàng nghìn lõi được tối ưu hóa cho xử lý song song và thông lượng cao.
- Độ chính xác và bộ nhớ : CPU thường sử dụng phép tính số học có độ chính xác cao và bộ nhớ đệm lớn, hỗ trợ các tác vụ tính toán chung. Ngược lại, bộ tăng tốc AI hỗ trợ phép tính số học có độ chính xác thấp, như 8 bit hoặc 16 bit, giảm dung lượng bộ nhớ và mức tiêu thụ năng lượng mà không ảnh hưởng nhiều đến độ chính xác—chìa khóa cho suy luận LLM.
- Hiệu quả năng lượng : Được thiết kế cho các tác vụ AI cường độ cao, bộ tăng tốc tiêu thụ ít điện năng hơn đáng kể cho mỗi thao tác so với CPU, góp phần tiết kiệm chi phí và giảm tác động đến môi trường khi triển khai ở quy mô lớn.
Tài liệu tham khảo: Lập trình bộ xử lý song song hàng loạt của David B. Kirk và Wen-mei W. Hwu [1]
Lưu ý rằng CPU có ít lõi hơn (4-8) và thiết kế được tối ưu hóa cho độ trễ thấp và hiệu suất luồng đơn cao. Ngược lại, GPU có hàng nghìn lõi và được tối ưu hóa cho thông lượng cao và xử lý song song. Khả năng xử lý song song này cho phép GPU xử lý hiệu quả khối lượng công việc AI quy mô lớn.
Các tính năng chính của AI Accelerators & Tác động đến suy luận LLM
Các trình tăng tốc AI được xây dựng với một số tính năng khiến chúng trở nên lý tưởng để xử lý khối lượng công việc AI quy mô lớn như suy luận LLM. Các tính năng chính bao gồm:
Xử lý song song
Các bộ tăng tốc AI được thiết kế để xử lý song song quy mô lớn, nhờ vào kiến trúc của chúng với hàng nghìn lõi. Tính song song này cho phép chúng xử lý các phép tính ma trận chuyên sâu cần thiết trong suy luận LLM một cách hiệu quả. Nhiều bộ tăng tốc cũng bao gồm các lõi tenxơ chuyên dụng, được tối ưu hóa cho các phép toán tenxơ như phép nhân ma trận. Các khả năng này làm cho các bộ tăng tốc AI nhanh hơn đáng kể so với CPU khi xử lý các tác vụ LLM ở quy mô lớn.
Tài liệu tham khảo: Tối ưu hóa suy luận của các mô hình nền tảng trên các trình tăng tốc AI của Youngsuk Park và cộng sự.
Bộ nhớ băng thông cao
Bộ tăng tốc đi kèm với bộ nhớ chuyên dụng cho phép băng thông cao, cho phép chúng truy cập vào các tập dữ liệu lớn và các tham số mô hình với độ trễ tối thiểu. Tính năng này rất cần thiết cho suy luận LLM, trong đó cần truy cập dữ liệu thường xuyên để tải văn bản đầu vào và các tham số mô hình. Bộ nhớ băng thông cao làm giảm tình trạng tắc nghẽn trong quá trình truy xuất dữ liệu, dẫn đến độ trễ thấp hơn và hiệu suất được cải thiện.
Băng thông kết nối tốc độ cao
Các bộ tăng tốc AI được trang bị các kết nối tốc độ cao để tạo điều kiện truyền dữ liệu nhanh trong các thiết lập đa thiết bị. Điều này đặc biệt quan trọng để mở rộng suy luận LLM trên nhiều thiết bị, nơi các bộ tăng tốc cần giao tiếp và chia sẻ dữ liệu hiệu quả. Băng thông kết nối cao đảm bảo rằng các tập dữ liệu lớn có thể được chia trên các thiết bị và xử lý song song mà không gây ra tình trạng tắc nghẽn.
Số học có độ chính xác thấp
Một lợi thế khác của bộ tăng tốc AI là hỗ trợ số học có độ chính xác thấp, chẳng hạn như phép tính số nguyên 8 bit và phép tính dấu phẩy động 16 bit. Điều này làm giảm mức sử dụng bộ nhớ và mức tiêu thụ năng lượng, giúp các tác vụ AI hiệu quả hơn. Đối với suy luận LLM, các phép tính có độ chính xác thấp cung cấp khả năng xử lý nhanh hơn trong khi vẫn duy trì độ chính xác đủ cho hầu hết các ứng dụng. Bộ tăng tốc AI có khả năng lựa chọn kiểu dữ liệu rất phong phú.
Tài liệu tham khảo: Tối ưu hóa suy luận của các mô hình nền tảng trên các trình tăng tốc AI của Youngsuk Park và cộng sự.
Thư viện và Khung được Tối ưu hóa
Hầu hết các trình tăng tốc AI đều có các thư viện được tối ưu hóa cho các khuôn khổ AI phổ biến, chẳng hạn như cuDNN cho GPU NVIDIA và XLA cho Google TPU. Các thư viện này cung cấp các API cấp cao để thực hiện các hoạt động AI phổ biến và bao gồm các tối ưu hóa dành riêng cho LLM. Sử dụng các thư viện này cho phép phát triển mô hình, triển khai và tối ưu hóa suy luận nhanh hơn.
Khả năng mở rộng và hiệu quả năng lượng
Bộ tăng tốc AI có khả năng mở rộng cao, cho phép triển khai trong các cụm hoặc trung tâm dữ liệu để xử lý khối lượng công việc lớn một cách hiệu quả. Chúng cũng được thiết kế để tiết kiệm năng lượng, tiêu thụ ít điện năng hơn CPU cho các tác vụ tương đương, điều này khiến chúng trở nên lý tưởng cho các ứng dụng tính toán chuyên sâu như suy luận LLM ở quy mô lớn. Hiệu quả này giúp giảm cả chi phí vận hành và tác động đến môi trường khi chạy các mô hình AI lớn.
Tính song song trong các bộ tăng tốc AI
Các loại kỹ thuật song song khác nhau được sử dụng để tối đa hóa hiệu quả của bộ tăng tốc AI cho suy luận LLM:
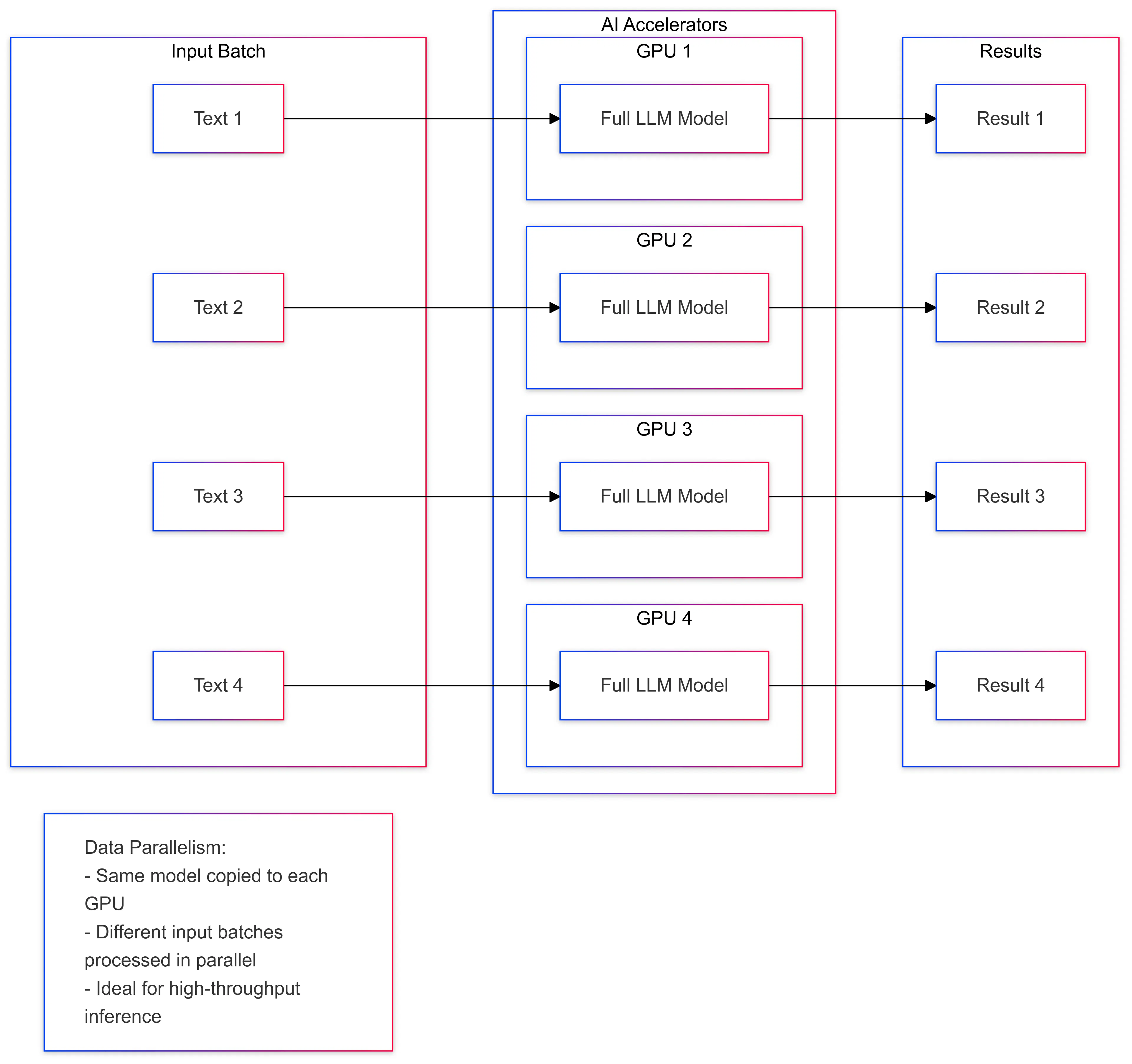
Dữ liệu song song
Song song dữ liệu liên quan đến việc chia dữ liệu đầu vào thành nhiều đợt và xử lý từng đợt song song. Điều này hữu ích cho khối lượng công việc AI liên quan đến các tập dữ liệu lớn, chẳng hạn như đào tạo học sâu và suy luận. Bằng cách phân phối dữ liệu trên nhiều thiết bị, các bộ tăng tốc AI có thể xử lý khối lượng công việc nhanh hơn và cải thiện hiệu suất tổng thể. Một ví dụ về song song dữ liệu trong suy luận LLM là chia văn bản đầu vào thành nhiều đợt và xử lý từng đợt trên một bộ tăng tốc riêng biệt.
Mô hình song song
Song song mô hình liên quan đến việc chia tách các thành phần của mô hình AI trên nhiều thiết bị, cho phép xử lý song song các phần mô hình khác nhau. Cách tiếp cận này đặc biệt quan trọng đối với các mô hình AI lớn vượt quá dung lượng bộ nhớ của một thiết bị hoặc yêu cầu tính toán phân tán để xử lý hiệu quả. Song song mô hình được sử dụng rộng rãi trong các mô hình ngôn ngữ lớn (LLM) và các kiến trúc học sâu khác, trong đó kích thước mô hình là một hạn chế đáng kể.
Tính song song của mô hình có thể được thực hiện theo hai cách tiếp cận chính:
Song song trong lớp (Song song Tensor) : Các lớp hoặc thành phần riêng lẻ được chia thành nhiều thiết bị, với mỗi thiết bị xử lý một phần tính toán trong cùng một lớp. Ví dụ, trong các mô hình máy biến áp, đầu chú ý hoặc các lớp mạng truyền thẳng có thể được phân phối trên nhiều thiết bị. Cách tiếp cận này giảm thiểu chi phí truyền thông vì các thiết bị chỉ cần đồng bộ hóa tại ranh giới lớp.
Song song giữa các lớp (Pipeline Parallelism) : Các nhóm lớp tuần tự được phân phối trên các thiết bị, tạo ra một đường ống tính toán. Mỗi thiết bị xử lý các lớp được chỉ định trước khi chuyển kết quả đến thiết bị tiếp theo trong đường ống. Cách tiếp cận này đặc biệt hiệu quả đối với các mạng sâu nhưng lại gây ra độ trễ đường ống.
Nhiệm vụ song song
Song song tác vụ liên quan đến việc chia khối lượng công việc AI thành nhiều tác vụ và xử lý từng tác vụ song song. Điều này hữu ích cho khối lượng công việc AI liên quan đến nhiều tác vụ độc lập, chẳng hạn như lái xe tự động. Bằng cách xử lý các tác vụ song song, các bộ tăng tốc AI có thể giảm thời gian hoàn thành các tác vụ phức tạp và cải thiện hiệu suất tổng thể. Song song tác vụ thường được sử dụng trong các bộ tăng tốc AI cho các tác vụ như phát hiện đối tượng và phân tích video.
Hãy xem xét một LLM với 70 tỷ tham số xử lý một loạt dữ liệu đầu vào văn bản:
- Tính song song của dữ liệu : Lô dữ liệu đầu vào được chia thành nhiều GPU, mỗi GPU xử lý một phần dữ liệu đầu vào một cách độc lập.
- Song song Tensor : Các đầu chú ý của mô hình biến áp được phân bổ trên nhiều thiết bị, trong đó mỗi thiết bị xử lý một tập hợp con các đầu chú ý.
- Song song đường ống : Các lớp của mô hình máy biến áp được chia thành các nhóm tuần tự, với mỗi nhóm được xử lý bởi một thiết bị khác nhau theo kiểu đường ống.
- Tính song song của tác vụ : Nhiều yêu cầu suy luận độc lập được xử lý đồng thời trên các đơn vị tăng tốc khác nhau.
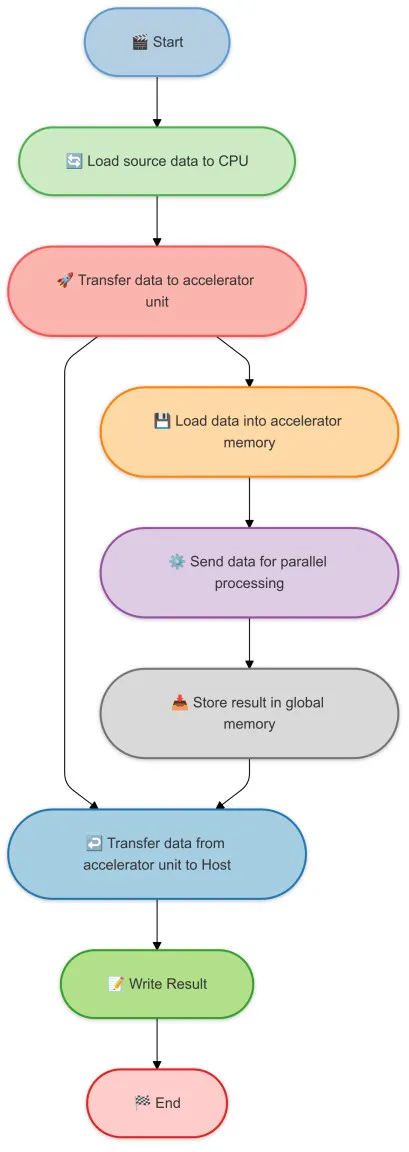
Chế độ đồng xử lý trong bộ tăng tốc AI
AI Accelerators thường hoạt động song song với CPU chính để giảm tải các tác vụ tính toán nặng. CPU chính chịu trách nhiệm cho các tác vụ mục đích chung và AI Accelerators chịu trách nhiệm cho các tác vụ tính toán nặng. Điều này thường được gọi là đồng xử lý. Sau đây là sơ đồ đơn giản để hiển thị cách AI Accelerators hoạt động với CPU chính. Sau đây là một số thuật ngữ ngắn gọn cho đồng xử lý:
- Host : CPU chính. Nó chịu trách nhiệm cho luồng chính của chương trình. Nó sắp xếp nhiệm vụ bằng cách tải dữ liệu chính và xử lý các hoạt động đầu vào/đầu ra. Ở chế độ đồng xử lý, host khởi tạo quy trình, chuyển dữ liệu đến AI Accelerators và nhận kết quả. Nó xử lý tất cả các logic không tính toán và để AI Accelerators xử lý số liệu.
- Thiết bị : Bộ tăng tốc AI. Chúng chịu trách nhiệm cho các tác vụ tính toán nặng. Sau khi nhận dữ liệu từ máy chủ, bộ tăng tốc tải dữ liệu vào bộ nhớ chuyên dụng và thực hiện xử lý song song được tối ưu hóa cho khối lượng công việc AI, chẳng hạn như phép nhân ma trận. Sau khi hoàn tất quá trình xử lý, nó lưu trữ kết quả và chuyển chúng trở lại máy chủ.
Xu hướng mới nổi trong các công cụ tăng tốc AI
Khi khối lượng công việc AI tiếp tục tăng về độ phức tạp và quy mô, các trình tăng tốc AI đang phát triển để đáp ứng nhu cầu của các ứng dụng hiện đại. Một số xu hướng chính định hình tương lai của các trình tăng tốc AI [3] bao gồm:
Bộ xử lý thông minh (IPU)
Được phát triển bởi Graphcore, IPU được thiết kế để xử lý các tác vụ học máy phức tạp với hiệu quả cao. Kiến trúc của chúng tập trung vào xử lý song song, khiến chúng phù hợp với khối lượng công việc AI quy mô lớn.
Đơn vị luồng dữ liệu có thể cấu hình lại (RDU)
Được phát triển bởi SambaNova Systems, RDU được thiết kế để tăng tốc khối lượng công việc AI bằng cách tối ưu hóa luồng dữ liệu trong bộ xử lý một cách năng động. Phương pháp này cải thiện hiệu suất và hiệu quả cho các tác vụ như suy luận LLM.
Đơn vị xử lý thần kinh (NPU)
NPU chuyên về các tác vụ học sâu và mạng nơ-ron, cung cấp khả năng xử lý dữ liệu hiệu quả phù hợp với khối lượng công việc AI. Chúng ngày càng được tích hợp vào các thiết bị yêu cầu khả năng AI trên thiết bị.
Phần kết luận
Trong bài đăng này, chúng tôi đã thảo luận về vai trò của các bộ tăng tốc AI trong việc nâng cao hiệu suất của khối lượng công việc AI, bao gồm suy luận LLM. Bằng cách tận dụng khả năng xử lý song song, bộ nhớ tốc độ cao và số học độ chính xác thấp của các bộ tăng tốc, các tổ chức có thể đạt được mức tăng hiệu suất đáng kể và tiết kiệm chi phí khi triển khai LLM ở quy mô lớn. Việc hiểu các tính năng chính và loại bộ tăng tốc AI là điều cần thiết để tối ưu hóa suy luận LLM và đảm bảo sử dụng tài nguyên hiệu quả trong các triển khai AI quy mô lớn. Trong bài đăng tiếp theo, chúng tôi sẽ thảo luận về các kỹ thuật tối ưu hóa hệ thống để triển khai LLM ở quy mô lớn bằng cách sử dụng bộ tăng tốc AI.
Tài liệu tham khảo
- [1] Lập trình bộ xử lý song song hàng loạt của David B. Kirk và Wen-mei W. Hwu
- [2] Tối ưu hóa suy luận của các mô hình nền tảng trên các bộ tăng tốc AI của Youngsuk Park và cộng sự.
- [3] Đánh giá các bộ tăng tốc AI/ML mới nổi: GPU IPU, RDU và NVIDIA/AMD của Hongwu Peng và cộng sự.
L O A D I N G
. . . comments & more!
. . . comments & more!



