





















Průzkum akcelerátorů umělé inteligence a jejich dopad na zavádění velkých jazykových modelů (LLM) ve velkém měřítku.
Příspěvky v této sérii :
Optimalizace odvození primeru na velkém jazykovém modelu (LLM): 1. Formulace pozadí a problému
Primer on Large Language Model (LLM) Inference Optimizations: 2. Úvod do akcelerátorů umělé inteligence (AI) (tento příspěvek)
V předchozím příspěvku jsme diskutovali o problémech odvození z velkého jazykového modelu (LLM), jako je vysoká latence, intenzivní spotřeba zdrojů a problémy se škálovatelností. Efektivní řešení těchto problémů často vyžaduje správnou hardwarovou podporu. Tento příspěvek se ponoří do akcelerátorů AI – specializovaného hardwaru navrženého ke zvýšení výkonu pracovních zátěží AI, včetně odvození LLM – a zdůrazňuje jejich architekturu, klíčové typy a dopad na nasazení LLM ve velkém.
Proč AI akcelerátory?
Pokud vás někdy zajímalo, jak společnosti jako OpenAI a Google zvládají provozovat tyto masivní jazykové modely sloužící milionům uživatelů současně, tajemství spočívá ve specializovaném hardwaru zvaném AI akcelerátory. Zatímco tradiční CPU zvládají úkoly pro obecné účely dobře, nejsou optimalizovány pro požadavky zátěže AI. Naproti tomu akcelerátory umělé inteligence jsou určeny pro úkoly umělé inteligence a nabízejí vysokorychlostní přístup k datům, možnosti paralelního zpracování a podporu pro aritmetiku s nízkou přesností. Přesunutím výpočtů na akcelerátory AI mohou organizace dosáhnout výrazného zvýšení výkonu a snížit náklady, zejména při provozování složitých modelů, jako jsou LLM. Pojďme prozkoumat některé běžné typy akcelerátorů AI a jejich jedinečné výhody pro tato pracovní zatížení.
Typy AI akcelerátorů
Akcelerátory umělé inteligence přicházejí v několika formách, z nichž každá je přizpůsobena konkrétním úkolům a prostředím umělé inteligence. Tři hlavní typy jsou GPU, TPU a FPGA/ASIC, z nichž každý má jedinečné vlastnosti a výhody:
Jednotky grafického zpracování (GPU)
GPU, původně vyvinuté pro vykreslování grafiky, se díky svým schopnostem paralelního zpracování staly mocným nástrojem pro úkoly hlubokého učení. Jejich architektura je vhodná pro vysoce výkonné maticové výpočty, které jsou nezbytné pro úlohy, jako je LLM inference. GPU jsou obzvláště oblíbené v datových centrech pro školení a vyvozování ve velkém měřítku. GPU jako NVIDIA Tesla, AMD Radeon a Intel Xe jsou široce používány v cloudových i místních prostředích.
Jednotky TPU (Tensor Processing Units)
Google vyvinul TPU speciálně pro pracovní zátěže hlubokého učení s optimalizací pro školení a vyvozování založené na TensorFlow. Jednotky TPU jsou navrženy tak, aby efektivně urychlovaly rozsáhlé úlohy umělé inteligence a poháněly mnoho aplikací Google, včetně vyhledávání a překladu. Jednotky TPU dostupné prostřednictvím služby Google Cloud nabízejí vysoký výkon pro školení i vyvozování, díky čemuž jsou preferovanou volbou pro uživatele TensorFlow.
Field-Programmable Gate Arrays (FPGA) / Application-Specific Integrated Circuits (ASIC)
FPGA a ASIC jsou dva odlišné typy přizpůsobitelných akcelerátorů, které podporují specifické úkoly AI. FPGA jsou přeprogramovatelné, což jim umožňuje přizpůsobit se různým modelům a aplikacím umělé inteligence, zatímco ASIC jsou účelově vytvořeny pro konkrétní úkoly a nabízejí maximální efektivitu pro tyto pracovní zátěže. Oba typy se používají v datových centrech a na okraji, kde je rozhodující nízká latence a vysoká propustnost. Příklady zahrnují Intel Arria a Xilinx Alveo (FPGA) a Google Edge TPU (ASIC).
Klíčové rozdíly mezi CPU a AI akcelerátory
Odlišné architektury CPU a AI akcelerátorů je činí vhodnými pro různé typy pracovních zátěží. Zde je srovnání některých nejkritičtějších funkcí:
- Architektura : Zatímco CPU jsou univerzální procesory, AI akcelerátory jsou specializovaný hardware optimalizovaný pro zátěž AI. Procesory mají obvykle méně jader, ale vysoké takty, díky čemuž jsou ideální pro úlohy vyžadující rychlý výkon s jedním vláknem. AI akcelerátory však mají tisíce jader optimalizovaných pro paralelní zpracování a vysokou propustnost.
- Přesnost a paměť : CPU často používají vysoce přesnou aritmetiku a velkou mezipaměť, která podporuje obecné výpočetní úlohy. Naproti tomu akcelerátory umělé inteligence podporují aritmetiku s nízkou přesností, jako je 8bitová nebo 16bitová, čímž snižují nároky na paměť a spotřebu energie, aniž by výrazně ohrozily přesnost – klíč k vyvozování LLM.
- Energetická účinnost : Akcelerátory, které jsou navrženy pro náročné úkoly umělé inteligence, spotřebovávají na operaci výrazně méně energie než CPU, což přispívá k úspoře nákladů a nižšímu dopadu na životní prostředí při nasazení ve velkém měřítku.
Reference: Programming Massively Parallel Processors od Davida B. Kirka a Wen-mei W. Hwu [1]


Všimněte si, že v CPU je méně jader (4-8) a design je optimalizován pro nízkou latenci a vysoký jednovláknový výkon. Oproti tomu GPU mají tisíce jader a jsou optimalizovány pro vysokou propustnost a paralelní zpracování. Tato schopnost paralelního zpracování umožňuje GPU efektivně zvládat rozsáhlé pracovní zátěže AI.
Klíčové vlastnosti akcelerátorů AI a dopad na odvození LLM
Akcelerátory AI mají několik funkcí, díky kterým jsou ideální pro zvládání rozsáhlých úloh AI, jako je LLM inference. Mezi klíčové vlastnosti patří:
Paralelní zpracování
AI akcelerátory jsou navrženy pro rozsáhlé paralelní zpracování díky své architektuře s tisíci jádry. Tento paralelismus jim umožňuje efektivně zpracovávat intenzivní maticové výpočty požadované v LLM inferencích. Mnoho urychlovačů také obsahuje specializovaná tenzorová jádra, která jsou optimalizována pro tenzorové operace, jako je násobení matic. Díky těmto schopnostem jsou akcelerátory AI výrazně rychlejší než CPU při zpracování úloh LLM ve velkém měřítku.
Reference: Inference Optimization of Foundation Models on AI Accelerators od Youngsuk Park, et al.


Paměť s vysokou šířkou pásma
Akcelerátory se dodávají se specializovanou pamětí, která umožňuje velkou šířku pásma, což jim umožňuje přístup k velkým datovým sadám a parametrům modelu s minimální latencí. Tato funkce je nezbytná pro odvození LLM, kde je vyžadován častý přístup k datům pro načtení vstupního textu a parametrů modelu. Paměť s velkou šířkou pásma snižuje problémové místo při získávání dat, což má za následek nižší latenci a lepší výkon.
Šířka pásma vysokorychlostního propojení
Akcelerátory umělé inteligence jsou vybaveny vysokorychlostními propojeními pro usnadnění rychlého přenosu dat v rámci nastavení s více zařízeními. To je zvláště důležité pro škálování LLM odvození napříč více zařízeními, kde akcelerátory potřebují efektivně komunikovat a sdílet data. Velká šířka pásma propojení zajišťuje, že velké datové sady mohou být rozděleny mezi zařízení a zpracovávány v tandemu, aniž by to způsobovalo úzká hrdla.
Nízko přesná aritmetika
Další výhodou AI akcelerátorů je jejich podpora pro aritmetiku s nízkou přesností, jako jsou 8bitové celočíselné a 16bitové výpočty s plovoucí desetinnou čárkou. To snižuje využití paměti a spotřebu energie, takže úkoly AI jsou efektivnější. Pro odvození LLM poskytují výpočty s nízkou přesností rychlejší zpracování při zachování dostatečné přesnosti pro většinu aplikací. AI akcelerátory mají velmi bohatý výběr datových typů.
Reference: Inference Optimization of Foundation Models on AI Accelerators od Youngsuk Park, et al.


Optimalizované knihovny a rámce
Většina akcelerátorů AI přichází s optimalizovanými knihovnami pro oblíbené rámce AI, jako je cuDNN pro GPU NVIDIA a XLA pro TPU Google. Tyto knihovny poskytují rozhraní API na vysoké úrovni pro provádění běžných operací AI a zahrnují optimalizace speciálně pro LLM. Použití těchto knihoven umožňuje rychlejší vývoj modelu, nasazení a optimalizaci odvození.
Škálovatelnost a energetická účinnost
Akcelerátory umělé inteligence jsou vysoce škálovatelné, což umožňuje nasazení v clusterech nebo datových centrech pro efektivní zvládání velkých pracovních zátěží. Jsou také navrženy tak, aby byly energeticky účinné, spotřebovávaly méně energie než CPU pro srovnatelné úkoly, což je činí ideálními pro výpočetně náročné aplikace, jako je LLM inference v měřítku. Tato efektivita pomáhá snižovat provozní náklady i dopad provozu velkých modelů umělé inteligence na životní prostředí.
Paralelismus v akcelerátorech AI
K maximalizaci účinnosti akcelerátorů AI pro odvození LLM se používají různé typy technik paralelismu:
Datový paralelismus
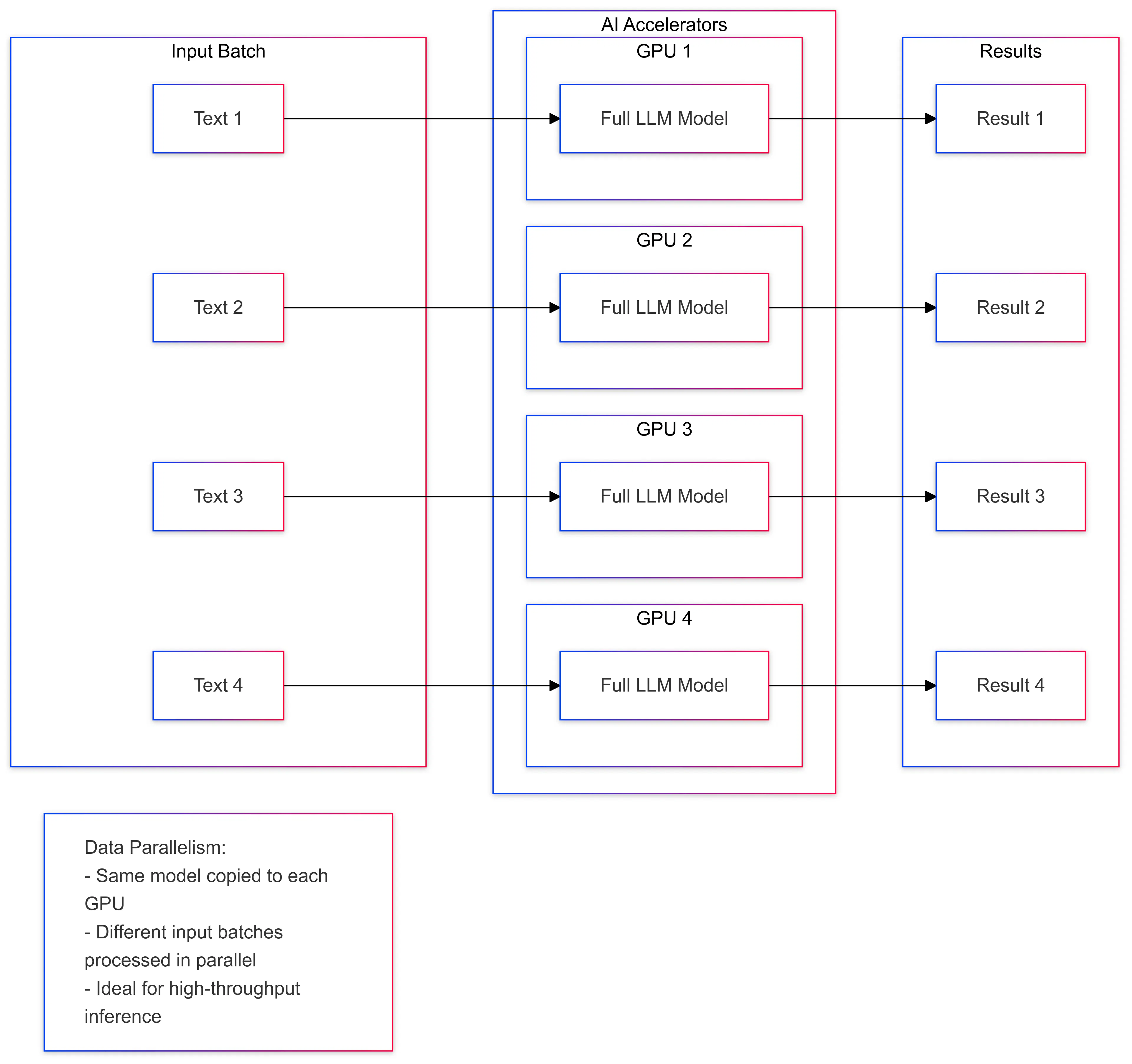
Datový paralelismus zahrnuje rozdělení vstupních dat do více dávek a paralelní zpracování každé dávky. To je užitečné pro pracovní zátěže umělé inteligence, které zahrnují velké datové sady, jako je hloubkové učení a inference. Díky distribuci dat mezi více zařízení mohou akcelerátory AI zpracovat pracovní zátěž rychleji a zlepšit celkový výkon. Příkladem datového paralelismu v odvození LLM je rozdělení vstupního textu do dávek a zpracování každé dávky na samostatném akcelerátoru.

Modelový paralelismus
Paralelismus modelu zahrnuje rozdělení komponent modelu AI na více zařízení, což umožňuje paralelní zpracování různých částí modelu. Tento přístup je zvláště důležitý pro velké modely umělé inteligence, které překračují kapacitu paměti jednoho zařízení nebo vyžadují distribuované výpočty pro efektivní zpracování. Paralelismus modelů je široce používán ve velkých jazykových modelech (LLM) a dalších architekturách hlubokého učení, kde je velikost modelu významným omezením.
Paralelismus modelu lze implementovat dvěma hlavními přístupy:
Paralelnost mezi vrstvami (Tensor Parallelism) : Jednotlivé vrstvy nebo komponenty jsou rozděleny mezi zařízení, přičemž každé zařízení zpracovává část výpočtu v rámci stejné vrstvy. Například u modelů transformátorů mohou být hlavy pozornosti nebo dopředné síťové vrstvy distribuovány mezi více zařízení. Tento přístup minimalizuje komunikační režii, protože zařízení se potřebují synchronizovat pouze na hranicích vrstev.


Paralelnost mezi vrstvami (rovnoběžnost s potrubím) : Po sobě jdoucí skupiny vrstev jsou rozmístěny mezi zařízeními a vytvářejí zřetězení výpočtů. Každé zařízení zpracovává své přiřazené vrstvy před předáním výsledků dalšímu zařízení v potrubí. Tento přístup je zvláště účinný pro hluboké sítě, ale zavádí latenci potrubí.


Paralelismus úkolů
Paralelnost úloh zahrnuje rozdělení zátěže AI do více úloh a paralelní zpracování každé úlohy. To je užitečné pro pracovní zátěže AI, které zahrnují více nezávislých úkolů, jako je autonomní řízení. Paralelním zpracováním úkolů mohou akcelerátory AI zkrátit čas potřebný k dokončení složitých úkolů a zlepšit celkový výkon. Paralelismus úloh se často používá v akcelerátorech AI pro úkoly, jako je detekce objektů a analýza videa.


Představte si LLM se 70 miliardami parametrů, které zpracovávají dávku textových vstupů:
- Datová paralelnost : Vstupní dávka je rozdělena mezi více GPU, z nichž každý zpracovává část vstupů nezávisle.
- Tenzorový paralelismus : Pozorovací hlavy modelu transformátoru jsou rozmístěny mezi více zařízeními, přičemž každé zařízení obsluhuje podmnožinu hlav.
- Paralelnost potrubí : Vrstvy modelu transformátoru jsou rozděleny do sekvenčních skupin, přičemž každá skupina je zpracována jiným zařízením zřetězeným způsobem.
- Paralelnost úloh : Na různých jednotkách akcelerátoru je současně zpracováváno více nezávislých požadavků na odvození.
Režim společného zpracování v akcelerátorech AI
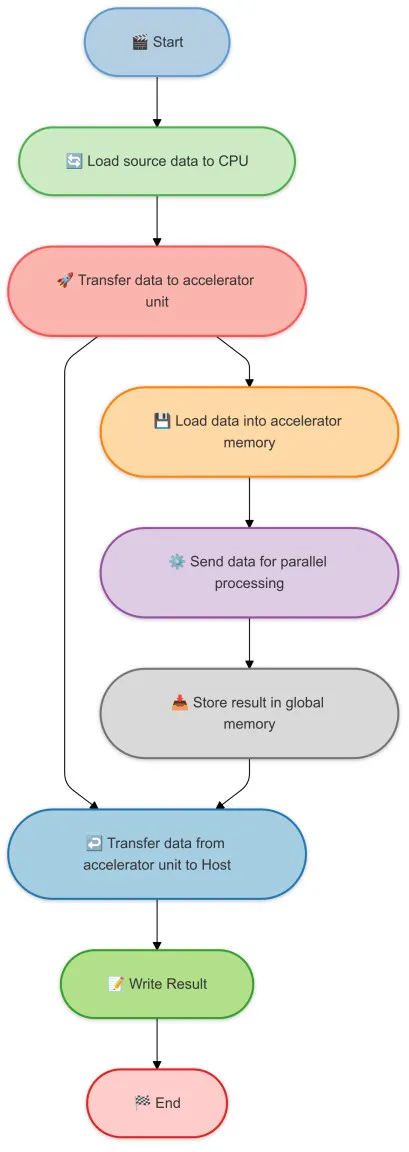
Akcelerátory AI často pracují v tandemu s hlavním CPU, aby odlehčily náročné výpočetní úlohy. Hlavní CPU je zodpovědné za obecné úlohy a akcelerátory AI jsou zodpovědné za náročné výpočetní úlohy. Obvykle se tomu říká společné zpracování. Zde je jednoduchý diagram, který ukazuje, jak AI akcelerátory spolupracují s hlavním CPU. Zde je nějaká stručná nomenklatura pro společné zpracování:
- Host : Hlavní CPU. Je zodpovědný za hlavní tok programu. Organizuje úlohu načítáním hlavních dat a zpracováním vstupních/výstupních operací. V režimu společného zpracování hostitel zahájí proces, přenese data do akcelerátorů AI a obdrží výsledky. Zvládá veškerou nevýpočtovou logiku a nechává hromadění čísel na akcelerátorech AI.
- Zařízení : Akcelerátory AI. Jsou zodpovědní za náročné výpočetní úlohy. Po přijetí dat od hostitele je akcelerátor načte do své specializované paměti a provede paralelní zpracování optimalizované pro pracovní zátěže AI, jako je násobení matic. Jakmile dokončí zpracování, uloží výsledky a přenese je zpět na hostitele.

Nové trendy v akcelerátorech AI
Vzhledem k tomu, že zátěž AI neustále narůstá ve složitosti a rozsahu, akcelerátory AI se vyvíjejí, aby vyhovovaly požadavkům moderních aplikací. Některé klíčové trendy utvářející budoucnost akcelerátorů AI [3] zahrnují:
Inteligentní procesorové jednotky (IPU)
IPU vyvinuté společností Graphcore jsou navrženy tak, aby zvládaly složité úlohy strojového učení s vysokou účinností. Jejich architektura se zaměřuje na paralelní zpracování, díky čemuž jsou vhodné pro rozsáhlé pracovní zátěže AI.
Rekonfigurovatelné jednotky toku dat (RDU)
RDU vyvinuté společností SambaNova Systems jsou navrženy tak, aby urychlily pracovní zátěž AI dynamickou optimalizací datového toku v procesoru. Tento přístup zlepšuje výkon a efektivitu pro úkoly, jako je LLM odvození.
Neuronové procesorové jednotky (NPU)
NPU se specializují na hluboké učení a úlohy neuronové sítě a poskytují efektivní zpracování dat přizpůsobené pracovní zátěži AI. Stále více se integrují do zařízení vyžadujících schopnosti umělé inteligence na zařízení.
Závěr
V tomto příspěvku jsme diskutovali o roli akcelerátorů AI při zvyšování výkonu pracovních zátěží AI, včetně odvození LLM. Využitím možností paralelního zpracování, vysokorychlostní paměti a aritmetiky s nízkou přesností akcelerátorů mohou organizace dosáhnout výrazného zvýšení výkonu a úspor nákladů při nasazování LLM ve velkém měřítku. Pochopení klíčových funkcí a typů akcelerátorů AI je zásadní pro optimalizaci odvození LLM a zajištění efektivního využití zdrojů v rozsáhlých nasazeních AI. V příštím příspěvku budeme diskutovat o technikách optimalizace systému pro nasazení LLM ve velkém pomocí AI akcelerátorů.
Reference
- [1] Programování masivně paralelních procesorů od Davida B. Kirka a Wen-mei W. Hwu
- [2] Inference Optimization of Foundation Models on AI Accelerators od Youngsuk Park, et al.
- [3] Hodnocení vznikajících akcelerátorů AI/ML: GPU IPU, RDU a NVIDIA/AMD od Hongwu Penga a kol.




