





















Exploración dos aceleradores de IA e o seu impacto na implantación de grandes modelos de linguaxe (LLM) a escala.
Publicacións desta serie :
Manual sobre as optimizacións de inferencia do modelo de linguaxe grande (LLM): 2. Introdución aos aceleradores de intelixencia artificial (IA) (esta publicación)
Na publicación anterior, discutimos os desafíos da inferencia do Modelo de Linguaxe Grande (LLM), como a alta latencia, o consumo intensivo de recursos e os problemas de escalabilidade. Abordar estes problemas de forma eficaz require moitas veces o soporte de hardware adecuado. Esta publicación afonda nos aceleradores de IA (hardware especializado deseñado para mellorar o rendemento das cargas de traballo de IA, incluída a inferencia de LLM), destacando a súa arquitectura, os tipos de clave e o impacto na implantación de LLM a escala.
Por que aceleradores de IA?
Se algunha vez te preguntas como empresas como OpenAI e Google conseguen executar estes modelos de linguaxe masivos que serven a millóns de usuarios simultaneamente, o segredo reside no hardware especializado chamado aceleradores de IA. Aínda que as CPU tradicionais manexan ben as tarefas de propósito xeral, non están optimizadas para as demandas das cargas de traballo de IA. Os aceleradores de intelixencia artificial, pola contra, están creados especialmente para tarefas de intelixencia artificial, que ofrecen acceso a datos de alta velocidade, capacidades de procesamento paralelo e soporte para aritmética de baixa precisión. Ao cambiar a computación aos aceleradores de IA, as organizacións poden lograr beneficios significativos de rendemento e reducir custos, especialmente cando se executan modelos complexos como os LLM. Exploremos algúns tipos comúns de aceleradores de IA e as súas vantaxes únicas para estas cargas de traballo.
Tipos de aceleradores de IA
Os aceleradores de IA teñen varias formas, cada unha adaptada a tarefas e ambientes de IA específicos. Os tres tipos principais son GPU, TPU e FPGA/ASIC, cada un con características e vantaxes únicas:
Unidades de procesamento gráfico (GPU)
Desenvolvidas orixinalmente para renderizar gráficos, as GPU convertéronse nunha poderosa ferramenta para tarefas de aprendizaxe profunda debido ás súas capacidades de procesamento paralelo. A súa arquitectura é moi adecuada para cálculos matriciales de alto rendemento, que son esenciais para tarefas como a inferencia LLM. As GPU son particularmente populares nos centros de datos para adestramento e inferencia a escala. As GPU como NVIDIA Tesla, AMD Radeon e Intel Xe son amplamente utilizadas tanto en ambientes na nube como en ambientes locais.
Unidades de procesamento de tensores (TPU)
Google desenvolveu TPU especificamente para cargas de traballo de aprendizaxe profunda, con optimizacións para a formación e inferencia baseadas en TensorFlow. As TPU están deseñadas para acelerar tarefas de intelixencia artificial a gran escala de forma eficiente, alimentando moitas das aplicacións de Google, incluídas a busca e a tradución. Dispoñibles a través de Google Cloud, as TPU ofrecen un alto rendemento tanto para a formación como para a inferencia, polo que son a opción preferida para os usuarios de TensorFlow.
Arrays de porta programables en campo (FPGA) / Circuítos integrados específicos de aplicación (ASIC)
Os FPGA e os ASIC son dous tipos distintos de aceleradores personalizables que admiten tarefas específicas de IA. As FPGA son reprogramables, o que lles permite adaptarse a diferentes modelos e aplicacións de IA, mentres que os ASIC están deseñados para tarefas específicas, ofrecendo a máxima eficiencia para esas cargas de traballo. Ambos os tipos utilízanse nos centros de datos e nos extremos, onde a baixa latencia e o alto rendemento son cruciais. Os exemplos inclúen Intel Arria e Xilinx Alveo (FPGA) e Google's Edge TPU (ASIC).
Diferenzas clave entre as CPU e os aceleradores de IA
As distintas arquitecturas das CPU e dos aceleradores de IA fan que sexan axeitados para diferentes tipos de cargas de traballo. Aquí tes unha comparación dalgunhas das características máis importantes:
- Arquitectura : aínda que as CPU son procesadores de propósito xeral, os aceleradores de IA son hardware especializado optimizado para cargas de traballo de IA. As CPU adoitan ter menos núcleos pero altas velocidades de reloxo, polo que son ideais para tarefas que requiren un rendemento rápido dun só fío. Os aceleradores de IA, con todo, teñen miles de núcleos optimizados para procesamento paralelo e alto rendemento.
- Precisión e memoria : as CPU adoitan usar aritmética de alta precisión e memoria caché grande, que admite tarefas informáticas xerais. Pola contra, os aceleradores de IA admiten aritmética de baixa precisión, como 8 ou 16 bits, o que reduce a pegada de memoria e o consumo de enerxía sen comprometer moito a precisión, clave para a inferencia de LLM.
- Eficiencia enerxética : deseñados para tarefas de intelixencia artificial de alta intensidade, os aceleradores consomen moito menos enerxía por operación que as CPU, o que contribúe ao aforro de custos e ao menor impacto ambiental cando se implantan a gran escala.
Referencia: Programming Massively Parallel Processors de David B. Kirk e Wen-mei W. Hwu [1]


Teña en conta que na CPU hai menos núcleos (4-8) e o deseño está optimizado para unha baixa latencia e un alto rendemento dun só fío. Pola contra, as GPU teñen miles de núcleos e están optimizadas para un alto rendemento e procesamento paralelo. Esta capacidade de procesamento paralelo permite ás GPU manexar cargas de traballo de IA a gran escala de forma eficiente.
Características principais dos aceleradores de IA e impacto na inferencia LLM
Os aceleradores de IA están creados con varias funcións que os fan ideais para manexar cargas de traballo de IA a gran escala como a inferencia de LLM. As características principais inclúen:
Procesamento paralelo
Os aceleradores de IA están deseñados para procesamento paralelo a gran escala, grazas á súa arquitectura con miles de núcleos. Este paralelismo permítelles manexar os cálculos matriciales intensivos necesarios na inferencia LLM de forma eficiente. Moitos aceleradores tamén inclúen núcleos tensoriais especializados, que están optimizados para operacións con tensores como multiplicacións matriciales. Estas capacidades fan que os aceleradores de IA sexan significativamente máis rápidos que as CPU ao procesar tarefas de LLM a escala.
Referencia: Optimización de inferencia de modelos de fundación en aceleradores de IA por Youngsuk Park, et al.


Memoria de gran ancho de banda
Os aceleradores veñen con memoria especializada que permite un alto ancho de banda, o que lles permite acceder a grandes conxuntos de datos e parámetros do modelo cunha latencia mínima. Esta función é esencial para a inferencia LLM, onde se require un acceso frecuente aos datos para cargar o texto de entrada e os parámetros do modelo. A memoria de gran ancho de banda reduce o pescozo de botella na recuperación de datos, o que resulta nunha menor latencia e un rendemento mellorado.
Ancho de banda de interconexión de alta velocidade
Os aceleradores de IA están equipados con interconexións de alta velocidade para facilitar a transferencia rápida de datos dentro de configuracións multidispositivo. Isto é particularmente importante para escalar a inferencia de LLM en varios dispositivos, onde os aceleradores deben comunicarse e compartir datos de forma eficiente. O alto ancho de banda de interconexión garante que grandes conxuntos de datos se poidan dividir entre dispositivos e procesarse en conxunto sen causar embotellamentos.
Aritmética de baixa precisión
Outra vantaxe dos aceleradores de IA é o seu soporte para aritmética de baixa precisión, como os cálculos de enteiros de 8 bits e de coma flotante de 16 bits. Isto reduce o uso de memoria e o consumo de enerxía, facendo que as tarefas de IA sexan máis eficientes. Para a inferencia de LLM, os cálculos de baixa precisión proporcionan un procesamento máis rápido mentres manteñen a precisión suficiente para a maioría das aplicacións. Os aceleradores de IA teñen unha selección de tipos de datos moi rica.
Referencia: Optimización de inferencia de modelos de fundación en aceleradores de IA por Youngsuk Park, et al.


Bibliotecas e marcos optimizados
A maioría dos aceleradores de IA inclúen bibliotecas optimizadas para marcos de IA populares, como cuDNN para GPU NVIDIA e XLA para TPU de Google. Estas bibliotecas proporcionan API de alto nivel para realizar operacións de IA comúns e inclúen optimizacións específicas para LLM. O uso destas bibliotecas permite un desenvolvemento, implantación e optimización de inferencias máis rápidos.
Escalabilidade e eficiencia enerxética
Os aceleradores de IA son altamente escalables, o que permite a súa implantación en clústeres ou centros de datos para xestionar grandes cargas de traballo de forma eficiente. Tamén están deseñados para ser eficientes enerxéticamente, consumindo menos enerxía que as CPU para tarefas comparables, o que os fai ideais para aplicacións de computación intensiva como a inferencia LLM a escala. Esta eficiencia axuda a reducir tanto o custo operativo como o impacto ambiental da execución de grandes modelos de IA.
Paralelismo nos aceleradores de IA
Empréganse diferentes tipos de técnicas de paralelismo para maximizar a eficiencia dos aceleradores de IA para a inferencia de LLM:
Paralelismo de datos
O paralelismo de datos implica dividir os datos de entrada en varios lotes e procesar cada lote en paralelo. Isto é útil para cargas de traballo de IA que impliquen grandes conxuntos de datos, como formación e inferencia de aprendizaxe profunda. Ao distribuír os datos en varios dispositivos, os aceleradores de IA poden procesar a carga de traballo máis rápido e mellorar o rendemento xeral. Un exemplo de paralelismo de datos na inferencia LLM é dividir o texto de entrada en lotes e procesar cada lote nun acelerador separado.

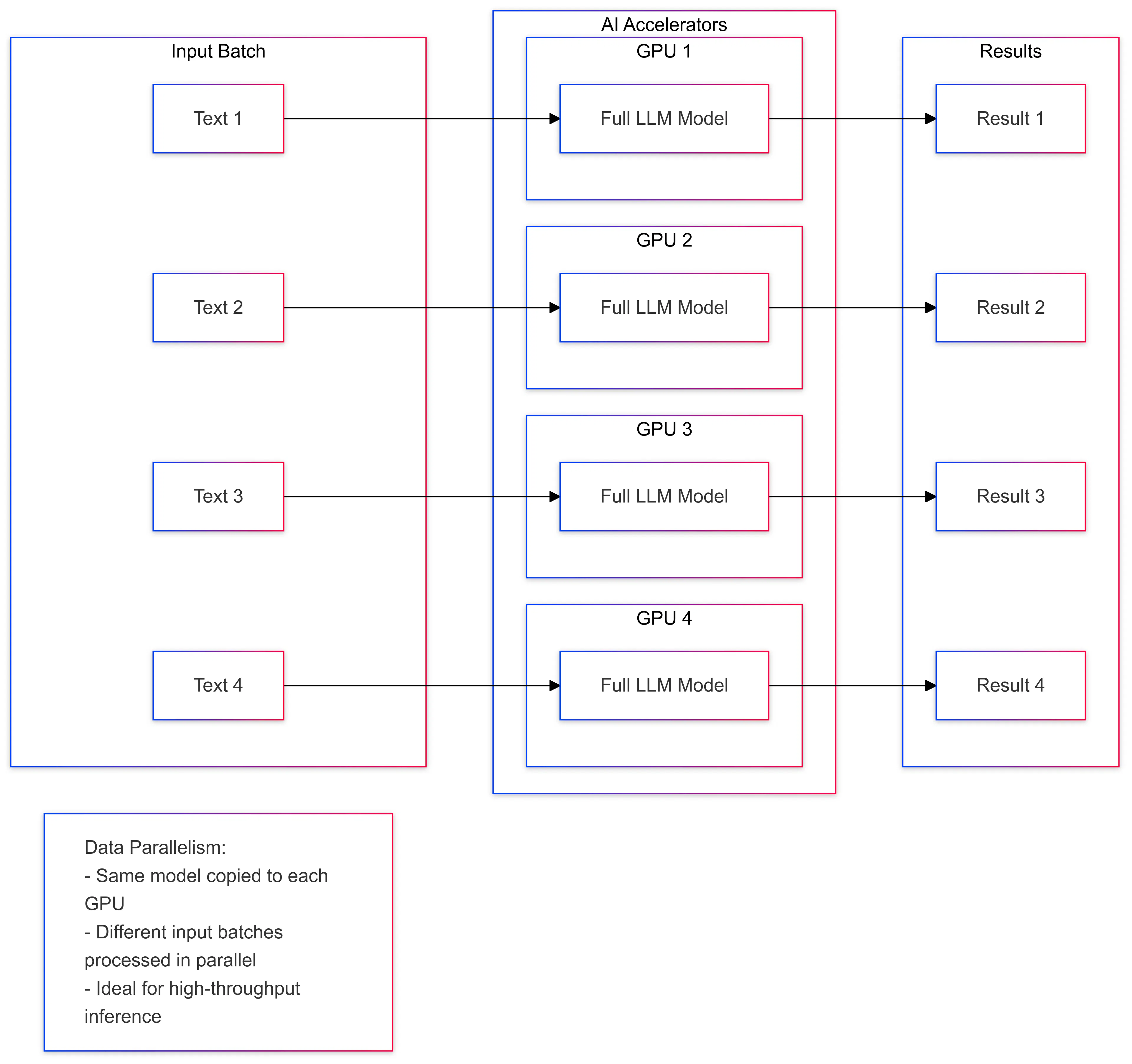
Paralelismo de modelos
O paralelismo de modelos implica dividir os compoñentes do modelo de IA en varios dispositivos, permitindo o procesamento paralelo de diferentes partes do modelo. Este enfoque é particularmente crucial para grandes modelos de IA que superan a capacidade de memoria dun só dispositivo ou requiren computación distribuída para un procesamento eficiente. O paralelismo de modelos úsase amplamente en grandes modelos de linguaxe (LLM) e noutras arquitecturas de aprendizaxe profunda onde o tamaño do modelo é unha limitación significativa.
O paralelismo de modelos pódese implementar en dous enfoques principais:
Paralelismo intracapa (paralelismo tensor) : as capas ou compoñentes individuais divídense entre os dispositivos, e cada dispositivo xestiona unha parte do cálculo dentro da mesma capa. Por exemplo, nos modelos de transformadores, as cabezas de atención ou as capas de rede de alimentación anticipada pódense distribuír en varios dispositivos. Este enfoque minimiza a sobrecarga de comunicación xa que os dispositivos só precisan sincronizarse nos límites das capas.


Paralelismo entre capas (paralelismo de canalizacións) : os grupos secuenciais de capas distribúense entre os dispositivos, creando unha canalización de cálculo. Cada dispositivo procesa as súas capas asignadas antes de pasar os resultados ao seguinte dispositivo da canalización. Este enfoque é particularmente efectivo para redes profundas pero introduce a latencia de canalización.


Paralelismo de tarefas
O paralelismo de tarefas implica dividir a carga de traballo da IA en varias tarefas e procesar cada tarefa en paralelo. Isto é útil para cargas de traballo de IA que implican múltiples tarefas independentes, como a condución autónoma. Ao procesar as tarefas en paralelo, os aceleradores de IA poden reducir o tempo necesario para completar tarefas complexas e mellorar o rendemento xeral. O paralelismo de tarefas úsase a miúdo nos aceleradores de IA para tarefas como a detección de obxectos e a análise de vídeo.


Considere un LLM con 70 mil millóns de parámetros que procesa un lote de entradas de texto:
- Paralelismo de datos : o lote de entrada divídese en varias GPU, cada unha procesando unha parte das entradas de forma independente.
- Paralelismo de tensor : as cabezas de atención do modelo de transformador distribúense en varios dispositivos, con cada dispositivo que manexa un subconxunto de cabezas.
- Paralelismo de canalizacións : as capas do modelo de transformador divídense en grupos secuenciais, sendo cada grupo procesado por un dispositivo diferente de forma canalizada.
- Paralelismo de tarefas : procesan simultáneamente varias solicitudes de inferencia independentes en diferentes unidades de aceleración.
Modo de coprocesamento en aceleradores de IA
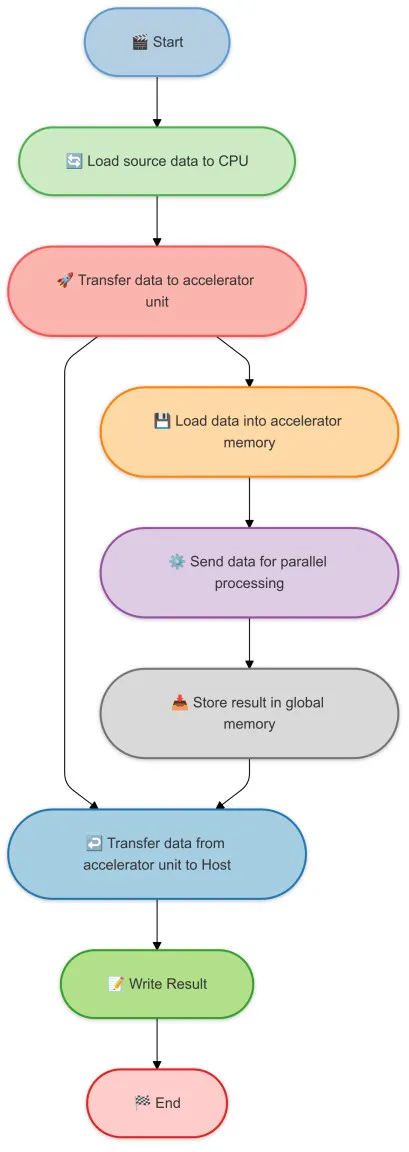
Os aceleradores de intelixencia artificial adoitan traballar en conxunto coa CPU principal para descargar as pesadas tarefas de cálculo. A CPU principal é responsable das tarefas de propósito xeral e os aceleradores de IA son responsables das tarefas de cálculo pesadas. Isto adoita chamarse coprocesamento. Aquí tes un diagrama sinxelo para mostrar como funcionan os aceleradores AI coa CPU principal. Aquí tes unha breve nomenclatura para o coprocesamento:
- Host : a CPU principal. É responsable do fluxo principal do programa. Orquestra a tarefa cargando os datos principais e xestionando as operacións de entrada/saída. No modo de co-procesamento, o anfitrión inicia o proceso, transfire datos a AI Accelerators e recibe os resultados. Manexa toda a lóxica non computacional e deixa o número en mans dos aceleradores de IA.
- Dispositivo : os aceleradores de IA. Son responsables das pesadas tarefas de cálculo. Despois de recibir datos do host, o acelerador cárgaos na súa memoria especializada e realiza un procesamento paralelo optimizado para cargas de traballo de IA, como multiplicacións matriciales. Unha vez que completa o procesamento, almacena os resultados e transfíreos de novo ao servidor.

Tendencias emerxentes en aceleradores de IA
A medida que as cargas de traballo de IA seguen crecendo en complexidade e escala, os aceleradores de IA están evolucionando para satisfacer as demandas das aplicacións modernas. Algunhas tendencias clave que configuran o futuro dos aceleradores de IA [3] inclúen:
Unidades de procesamento intelixente (IPU)
Desenvolvidas por Graphcore, as IPU están deseñadas para xestionar tarefas complexas de aprendizaxe automática con alta eficiencia. A súa arquitectura céntrase no procesamento paralelo, polo que son axeitados para cargas de traballo de IA a gran escala.
Unidades de fluxo de datos reconfigurables (RDU)
Desenvolvidas por SambaNova Systems, as RDU están deseñadas para acelerar as cargas de traballo da intelixencia artificial optimizando o fluxo de datos dentro do procesador de forma dinámica. Este enfoque mellora o rendemento e a eficiencia para tarefas como a inferencia de LLM.
Unidades de procesamento neuronal (NPU)
As NPU están especializadas para tarefas de aprendizaxe profunda e redes neuronais, proporcionando un procesamento de datos eficiente adaptado ás cargas de traballo de IA. Cada vez están máis integrados en dispositivos que requiren capacidades de intelixencia artificial no dispositivo.
Conclusión
Nesta publicación, discutimos o papel dos aceleradores de IA para mellorar o rendemento das cargas de traballo de IA, incluída a inferencia de LLM. Ao aproveitar as capacidades de procesamento paralelo, a memoria de alta velocidade e a aritmética de pouca precisión dos aceleradores, as organizacións poden conseguir importantes ganancias de rendemento e aforro de custos ao implantar LLM a escala. Comprender as principais características e tipos de aceleradores de IA é esencial para optimizar a inferencia de LLM e garantir unha utilización eficiente dos recursos nas implantacións de IA a gran escala. Na seguinte publicación, discutiremos as técnicas de optimización do sistema para implementar LLMs a escala usando aceleradores de IA.
Referencias
- [1] Programación de procesadores masivamente paralelos de David B. Kirk e Wen-mei W. Hwu
- [2] Optimización de inferencia de modelos de fundación en aceleradores de IA por Youngsuk Park, et al.
- [3] Avaliación de aceleradores AI/ML emerxentes: GPU IPU, RDU e NVIDIA/AMD por Hongwu Peng, et al.








