























Makine öğrenimi dünyasında Derin Öğrenme (DL) modellerinin verimliliğinin, niceleme adı verilen bir teknikle önemli ölçüde artırılabileceğini biliyor muydunuz? Performansından ödün vermeden sinir ağınızın hesaplama yükünü azalttığınızı hayal edin. Tıpkı büyük bir dosyayı özünü kaybetmeden sıkıştırmak gibi, model niceleme de modellerinizi daha küçük ve daha hızlı hale getirmenize olanak tanır. Büyüleyici nicemleme kavramına dalalım ve sinir ağlarınızı gerçek dünyadaki dağıtım için optimize etmenin sırlarını açığa çıkaralım.
Konuya girmeden önce okuyucuların sinir ağlarına ve ölçek (S) ve sıfır noktası (ZP) terimleri de dahil olmak üzere temel niceleme kavramına aşina olmaları gerekir. Bilgilerini tazelemek isteyen okuyucular için bu makale ve bu makalede kuantizasyon kavramı ve türleri açıklanmaktadır.
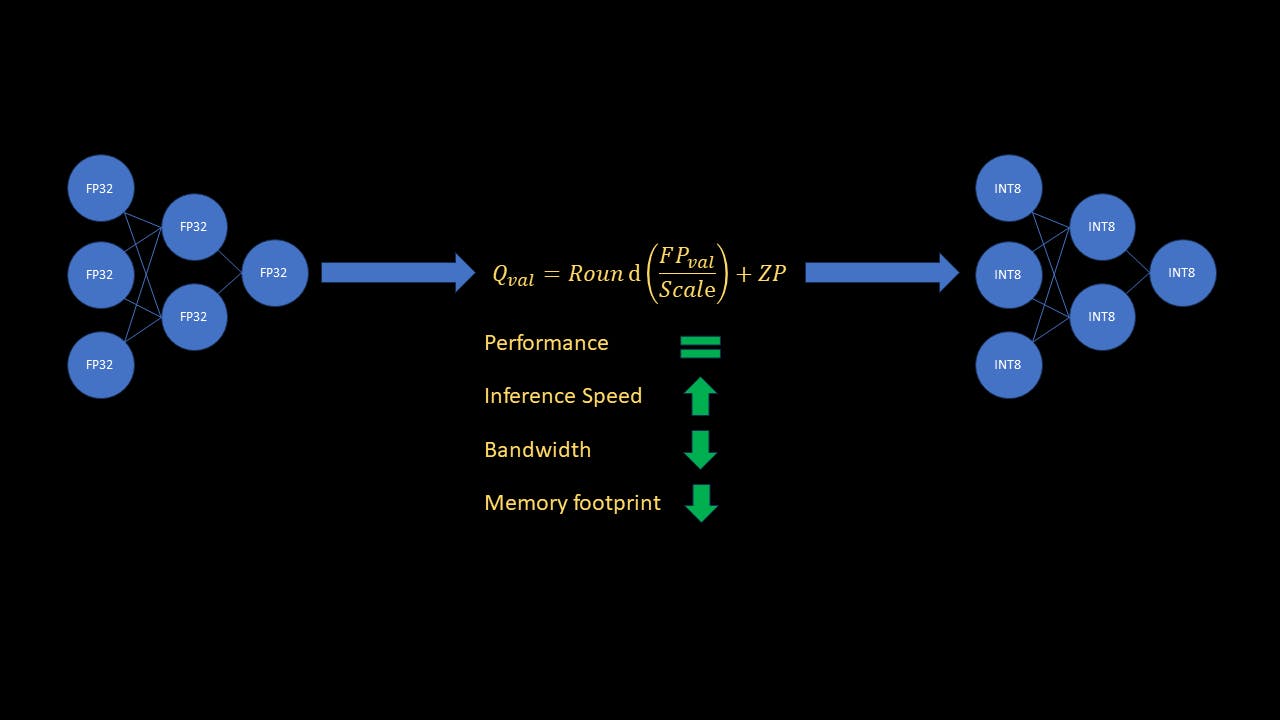
Bu kılavuzda nicelemenin neden önemli olduğunu ve Pytorch kullanarak nasıl uygulanacağını kısaca açıklayacağım. Temel olarak, ML modelinin 4 kat daha az bellek alanıyla sonuçlanan ve çıkarımı 4 kata kadar daha hızlı hale getiren "eğitim sonrası statik niceleme" adı verilen niceleme türüne odaklanacağım.
Kavramlar
Kuantizasyon Neden Önemlidir?
Sinir Ağları hesaplamaları en yaygın olarak 32 bitlik kayan nokta sayılarıyla gerçekleştirilir. Tek bir 32 bitlik kayan nokta numarası (FP32), 4 baytlık bellek gerektirir. Karşılaştırıldığında, tek bir 8 bitlik tamsayı sayısı (INT8) yalnızca 1 baytlık bellek gerektirir. Ayrıca bilgisayarlar tamsayı aritmetiğini kayan noktalı işlemlerden çok daha hızlı işler. Bir ML modelinin FP32'den INT8'e nicelendirilmesinin 4 kat daha az bellekle sonuçlanacağını hemen görebilirsiniz. Dahası, çıkarımı 4 kata kadar hızlandıracak! Büyük modellerin şu sıralar revaçta olduğu göz önüne alındığında, uygulayıcıların gerçek zamanlı çıkarım için bellek ve hız açısından eğitilmiş modelleri optimize edebilmeleri önemlidir.


Anahtar terimler
Ağırlıklar - Eğitilmiş sinir ağının ağırlıkları.
Aktivasyonlar - Kuantizasyon açısından aktivasyonlar, Sigmoid veya ReLU gibi aktivasyon fonksiyonları değildir. Aktivasyon derken, bir sonraki katmanlara girdi olan ara katmanların özellik haritası çıktılarını kastediyorum.
Eğitim Sonrası Statik Niceleme
Eğitim sonrası statik kuantizasyon, orijinal modeli eğittikten sonra modeli kuantizasyon için eğitmemize veya ince ayar yapmamıza gerek olmadığı anlamına gelir. Ayrıca, anında aktivasyonlar olarak adlandırılan ara katman girişlerini nicelememize de ihtiyacımız yok. Bu niceleme modunda ağırlıklar, her katman için ölçek ve sıfır noktası hesaplanarak doğrudan nicelenir. Ancak aktivasyonlarda modelin girdisi değiştikçe aktivasyonlar da değişecektir. Çıkarım sırasında modelin karşılaşacağı her girdinin aralığını bilmiyoruz. Peki ağın tüm aktivasyonları için ölçeği ve sıfır noktasını nasıl hesaplayabiliriz?
Bunu, iyi bir temsili veri kümesi kullanarak modeli kalibre ederek yapabiliriz. Daha sonra kalibrasyon seti için aktivasyonların değer aralığını gözlemliyoruz ve ardından bu istatistikleri ölçeği ve sıfır noktasını hesaplamak için kullanıyoruz. Bu, kalibrasyon sırasında veri istatistiklerini toplayan gözlemcilerin modele eklenmesiyle yapılır. Modeli hazırladıktan sonra (gözlemcileri yerleştirdikten sonra), modelin kalibrasyon veri seti üzerinde ileri geçişini çalıştırıyoruz. Gözlemciler bu kalibrasyon verilerini aktivasyonlar için ölçeği ve sıfır noktasını hesaplamak amacıyla kullanır. Artık çıkarım yalnızca doğrusal dönüşümü tüm katmanlara ilgili ölçekleri ve sıfır noktalarıyla uygulama meselesidir.
Çıkarımın tamamı INT8'de yapılırken, nihai model çıktısının niceliği kaldırılır (INT8'den FP32'ye).
Giriş ve ağ ağırlıkları zaten nicelenmişse aktivasyonların neden nicelenmesi gerekiyor?
Bu mükemmel bir soru. Ağ girişi ve ağırlıklar aslında zaten INT8 değerleri olsa da, taşmayı önlemek için katmanın çıkışı INT32 olarak depolanır. Bir sonraki katmanın işlenmesindeki karmaşıklığı azaltmak için aktivasyonlar INT32'den INT8'e nicelendirilir.
Kavramlar netleştikten sonra kodun içine dalalım ve nasıl çalıştığını görelim!
Bu örnek için, doğrudan Pytorch'ta mevcut olan Flowers102 veri kümesi üzerinde ince ayarı yapılmış bir resnet18 modelini kullanacağım. Ancak kod, uygun kalibrasyon veri kümesiyle eğitimli herhangi bir CNN için çalışacaktır. Bu eğitim kuantizasyona odaklandığından eğitim ve ince ayar kısmını ele almayacağım. Ancak kodun tamamı burada bulunabilir. Hadi dalalım!
Niceleme Kodu
Kuantizasyon için gerekli kütüphaneleri içe aktaralım ve ince ayarlı modeli yükleyelim.
import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore')
Sonra bazı parametreleri tanımlayalım, veri dönüşümlerini ve veri yükleyicileri tanımlayalım ve ince ayarlı modeli yükleyelim
model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model')Bu örnekte kalibrasyon seti olarak bazı eğitim örneklerini kullanacağım.
Şimdi modeli nicelemek için kullanılan konfigürasyonu tanımlayalım.
# Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig)Yukarıdaki kod parçasında, varsayılan yapılandırmayı kullandım, ancak Pytorch'un QConfig sınıfı, modelin veya modelin bir kısmının nasıl kuantize edilmesi gerektiğini açıklamak için kullanılır. Bunu ağırlıklandırma ve aktivasyonlarda kullanılacak gözlemci sınıflarının türünü belirterek yapabiliriz.
Artık modeli kuantizasyon için hazırlamaya hazırız
# Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) prepare_fx işlevi gözlemcileri modele ekler ve ayrıca conv→relu ve conv→bn→relu modüllerini birleştirir. Bu, bu modüllerin ara sonuçlarının saklanmasına gerek kalmaması nedeniyle daha az işlem ve daha düşük bellek bant genişliği ile sonuçlanır.
Kalibrasyon verilerini ileriye doğru aktararak modeli kalibre edin
# Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: breakEğitim setinin tamamında kalibrasyon yapmamıza gerek yok! Bu örnekte 100 rastgele örnek kullanıyorum ancak pratikte modelin dağıtım sırasında göreceğini temsil eden bir veri kümesi seçmelisiniz.
Modeli nicelendirin ve nicelenmiş ağırlıkları kaydedin!
# Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk')Ve bu kadar! Şimdi nicelenmiş bir modelin nasıl yükleneceğini görelim ve ardından orijinal ve nicelenmiş modellerin doğruluğunu, hızını ve bellek ayak izini karşılaştıralım.
Nicelenmiş bir model yükleme
Nicelenmiş bir model grafiği, her ikisi de aynı katmanlara sahip olsa bile orijinal modelle tam olarak aynı değildir.
Her iki modelin de ilk katmanını ( conv1 ) yazdırmak farkı gösterir.
print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') 

Nicelenmiş modelin conv1 katmanının, farklı sınıfın yanı sıra ölçek ve sıfır noktası parametrelerini de içerdiğini fark edeceksiniz.
Bu nedenle yapmamız gereken şey, model grafiğini oluşturmak için niceleme sürecini (kalibrasyon olmadan) takip etmek ve ardından nicelenmiş ağırlıkları yüklemektir. Elbette, eğer nicelenmiş modeli onnx formatında kaydedersek, onu diğer onnx modelleri gibi, her seferinde niceleme fonksiyonlarını çalıştırmadan yükleyebiliriz.
Bu arada nicelenmiş modeli yüklemek için bir fonksiyon tanımlayalım ve onu inference_utils.py dosyasına kaydedelim.
import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model
Doğruluk ve hızı ölçmek için işlevleri tanımlayın
Doğruluğu ölçün
import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samplesBu oldukça basit bir Pytorch kodudur.
Çıkarım hızını milisaniye (ms) cinsinden ölçün
import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000
Bu işlevlerin her ikisini de inference_utils.py dosyasına ekleyin. Artık modelleri karşılaştırmaya hazırız. Kodun üzerinden geçelim.
Modelleri doğruluk, hız ve boyut açısından karşılaştırın
Öncelikle gerekli kütüphaneleri içe aktaralım, parametreleri, veri dönüşümlerini ve test veri yükleyicisini tanımlayalım.
import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)
İki modeli yükleyin
# Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path)
Modelleri karşılaştır
# Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB')
Sonuçlar


Gördüğünüz gibi, test verileri üzerindeki nicelenmiş modelin doğruluğu neredeyse orijinal modelin doğruluğu kadardır! Nicelenmiş modelle çıkarım ~3,6 kat daha hızlıdır (!) ve nicelenmiş model, orijinal modele göre ~4 kat daha az bellek gerektirir!
Çözüm
Bu makalede, ML modeli nicelemesinin geniş konseptini ve Eğitim Sonrası Statik Niceleme adı verilen bir niceleme türünü anladık. Ayrıca büyük modeller çağında nicelemenin neden önemli ve güçlü bir araç olduğuna da baktık. Son olarak, eğitilmiş bir modeli Pytorch kullanarak nicelemek için örnek kodu inceledik ve sonuçları inceledik. Sonuçların gösterdiği gibi, orijinal modeli nicelemek performansı etkilemedi ve aynı zamanda çıkarım hızını ~3,6 kat azalttı ve bellek ayak izini ~4 kat azalttı!
Dikkat edilmesi gereken birkaç nokta: Statik niceleme, CNN'ler için iyi çalışır, ancak dinamik niceleme, dizi modelleri için tercih edilen yöntemdir. Ek olarak, eğer kuantizasyon model performansını büyük ölçüde etkiliyorsa, doğruluk, Kuantizasyon Farkındalık Eğitimi (QAT) adı verilen bir teknikle yeniden kazanılabilir.
Dinamik Niceleme ve QAT nasıl çalışır? Bunlar başka bir zamanın gönderileri. Umarım bu kılavuzla, kendi Pytorch modellerinizde statik kuantizasyon gerçekleştirmeniz için gerekli bilgiyi edinmiş olursunuz.
Referanslar








