























機械学習の世界では、量子化と呼ばれる技術によって深層学習 (DL) モデルの効率が大幅に向上することをご存知ですか?ニューラル ネットワークのパフォーマンスを犠牲にすることなく、ニューラル ネットワークの計算負荷を軽減できることを想像してみてください。本質を失わずに大きなファイルを圧縮するのと同じように、モデルの量子化によりモデルをより小さく、より高速に行うことができます。量子化という魅力的な概念を詳しく掘り下げ、現実世界の展開に合わせてニューラル ネットワークを最適化する秘密を明らかにしましょう。
本題に入る前に、読者はニューラル ネットワークと、スケール (S) やゼロ ポイント (ZP) という用語を含む量子化の基本概念についてよく理解しておく必要があります。もう一度復習したい読者のために、この記事とこの記事では、量子化の広範な概念と種類について説明します。
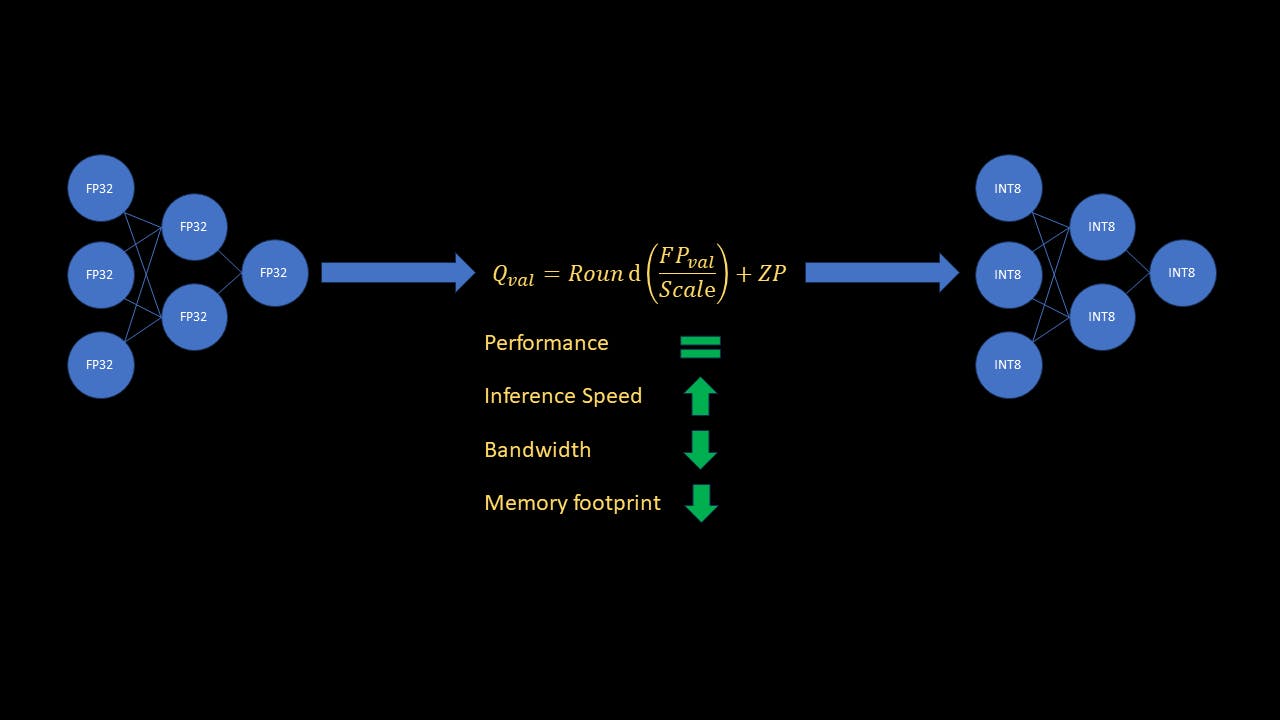
このガイドでは、量子化が重要な理由と、Pytorch を使用して量子化を実装する方法を簡単に説明します。ここでは主に「トレーニング後の静的量子化」と呼ばれる量子化のタイプに焦点を当てます。これにより、ML モデルのメモリ フットプリントが 4 分の 1 に削減され、推論が最大 4 倍高速になります。
コンセプト
なぜ量子化が重要なのでしょうか?
ニューラル ネットワークの計算は、32 ビット浮動小数点数を使用して実行されるのが最も一般的です。単一の 32 ビット浮動小数点数 (FP32) には 4 バイトのメモリが必要です。比較すると、単一の 8 ビット整数 (INT8) には 1 バイトのメモリのみが必要です。さらに、コンピューターは整数演算を浮動小数点演算よりもはるかに高速に処理します。 ML モデルを FP32 から INT8 に量子化すると、メモリが 4 倍少なくなることがすぐにわかります。さらに、推論も 4 倍も高速化されます。現在、大規模なモデルが大流行しているため、実務者にとって、トレーニング済みモデルのメモリとリアルタイム推論の速度を最適化できることが重要です。


重要な用語
Weights -トレーニングされたニューラル ネットワークの重み。
活性化 -量子化の観点から見ると、活性化は Sigmoid や ReLU のような活性化関数ではありません。アクティベーションとは、次の層への入力となる中間層の特徴マップ出力を意味します。
トレーニング後の静的量子化
トレーニング後の静的量子化は、元のモデルをトレーニングした後に量子化のためにモデルをトレーニングしたり微調整したりする必要がないことを意味します。また、オンザフライのアクティベーションと呼ばれる中間層の入力を量子化する必要もありません。この量子化モードでは、各レイヤーのスケールとゼロ点を計算することによって重みが直接量子化されます。ただし、アクティベーションの場合、モデルへの入力が変化すると、アクティベーションも同様に変化します。推論中にモデルが遭遇するそれぞれの入力の範囲はわかりません。では、ネットワークのすべてのアクティベーションのスケールとゼロ点を計算するにはどうすればよいでしょうか?
これは、適切な代表的なデータセットを使用してモデルを調整することで実現できます。次に、キャリブレーション セットの活性化の値の範囲を観察し、それらの統計を使用してスケールとゼロ点を計算します。これは、キャリブレーション中にデータ統計を収集するオブザーバーをモデルに挿入することによって行われます。モデルを準備した後 (オブザーバーを挿入)、キャリブレーション データセット上でモデルのフォワード パスを実行します。観測者はこの校正データを使用して、活性化のスケールとゼロ点を計算します。ここでの推論は、それぞれのスケールとゼロ点を持つすべてのレイヤーに線形変換を適用するだけです。
推論全体は INT8 で行われますが、最終モデル出力は逆量子化されます (INT8 から FP32 へ)。
入力とネットワークの重みがすでに量子化されているのに、なぜアクティベーションを量子化する必要があるのでしょうか?
これは素晴らしい質問です。ネットワーク入力と重みは確かにすでに INT8 値ですが、オーバーフローを避けるために、層の出力は INT32 として保存されます。次の層の処理の複雑さを軽減するために、アクティベーションは INT32 から INT8 に量子化されます。
概念が明確になったら、コードを詳しく見て、それがどのように機能するかを見てみましょう。
この例では、Pytorch で直接利用できる Flowers102 データセットで微調整された resnet18 モデルを使用します。ただし、このコードは、適切なキャリブレーション データセットを使用すれば、トレーニング済みの CNN に対しても機能します。このチュートリアルは量子化に焦点を当てているため、トレーニングと微調整の部分については説明しません。ただし、すべてのコードはここにあります。飛び込んでみましょう!
量子化コード
量子化に必要なライブラリをインポートし、微調整されたモデルをロードしましょう。
import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore')
次に、いくつかのパラメータを定義し、データ変換とデータローダーを定義して、微調整されたモデルをロードしましょう
model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model')この例では、いくつかのトレーニング サンプルをキャリブレーション セットとして使用します。
ここで、モデルの量子化に使用される構成を定義しましょう。
# Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig)上のスニペットではデフォルトの設定を使用していますが、モデルまたはモデルの一部を量子化する方法を記述するために Pytorch のQConfigクラスが使用されています。これを行うには、重みとアクティベーションに使用するオブザーバー クラスのタイプを指定します。
これで、モデルを量子化する準備が整いました。
# Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) prepare_fx関数は、オブザーバーをモデルに挿入し、conv→relu モジュールと conv→bn→relu モジュールを融合します。これにより、これらのモジュールの中間結果を保存する必要がなくなるため、操作が減り、メモリ帯域幅が低下します。
キャリブレーション データに対してフォワード パスを実行してモデルをキャリブレーションします。
# Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: breakトレーニング セット全体に対してキャリブレーションを実行する必要はありません。この例では 100 個のランダム サンプルを使用していますが、実際には、展開中にモデルが表示するものを表すデータセットを選択する必要があります。
モデルを量子化し、量子化された重みを保存します。
# Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk')以上です!ここで、量子化モデルをロードする方法を見て、元のモデルと量子化モデルの精度、速度、メモリ使用量を比較してみましょう。
量子化されたモデルをロードする
量子化されたモデル グラフは、たとえ両方が同じレイヤーを持っていたとしても、元のモデルとまったく同じではありません。
両方のモデルの最初のレイヤー ( conv1 ) を印刷すると、違いがわかります。
print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') 

異なるクラスとともに、量子化モデルの conv1 レイヤーにはスケールとゼロ点パラメーターも含まれていることがわかります。
したがって、必要なことは、量子化プロセスに従って (キャリブレーションなしで) モデル グラフを作成し、量子化された重みをロードすることです。もちろん、量子化モデルを onnx 形式で保存すると、量子化関数を毎回実行することなく、他の onnx モデルと同様にロードできます。
その間に、量子化モデルをロードする関数を定義し、それをinference_utils.pyに保存しましょう。
import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model
精度と速度を測定するための関数を定義する
測定精度
import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samplesこれは非常に単純な Pytorch コードです。
推論速度をミリ秒 (ms) 単位で測定します。
import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000
これら両方の関数をinference_utils.pyに追加します。これでモデルを比較する準備が整いました。コードを見てみましょう。
精度、速度、サイズについてモデルを比較する
まず必要なライブラリをインポートし、パラメータ、データ変換、およびテスト データローダーを定義しましょう。
import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)
2 つのモデルをロードする
# Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path)
モデルの比較
# Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB')
結果


ご覧のとおり、テスト データ上の量子化モデルの精度は、元のモデルの精度とほぼ同じです。量子化モデルを使用した推論は、元のモデルに比べて最大 3.6 倍 (!) 高速になり、量子化モデルに必要なメモリは最大 4 倍少なくなります。
結論
この記事では、ML モデルの量子化の広範な概念と、トレーニング後の静的量子化と呼ばれる量子化の種類について理解しました。また、量子化がなぜ重要であり、大規模なモデルの場合には強力なツールであるのかについても検討しました。最後に、Pytorch を使用してトレーニング済みモデルを量子化するコード例を確認し、結果を確認しました。結果が示したように、元のモデルの量子化はパフォーマンスに影響を与えず、同時に推論速度が最大 3.6 倍低下し、メモリ フットプリントが最大 4 倍減少しました。
いくつかの注意点 - 静的量子化は CNN には適切に機能しますが、シーケンス モデルには動的量子化が推奨される方法です。さらに、量子化がモデルのパフォーマンスに大きな影響を与える場合は、量子化認識トレーニング (QAT) と呼ばれる手法によって精度を回復できます。
動的量子化と QAT はどのように機能しますか?これらはまた別の機会に投稿します。このガイドにより、独自の Pytorch モデルで静的量子化を実行するための知識が得られることを願っています。
参考文献








